Citation: Xiaoyue Xie, Jian Shi. A distributed quantile estimation algorithm of heavy-tailed distribution with massive datasets[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 214-230. doi: 10.3934/mbe.2021011

| [1] |
H. Rootzén, R. W. Katz, Design life level: Quantifying risk in a changing climate. Water Resour. Res., 49 (2013), 5964-5972. doi: 10.1002/wrcr.20425

|
| [2] |
M. M. de Oliveira, N. F. Ebecken, J. L. de Oliveira, E. Gilleland, Generalized extreme wind speed distributions in south America over the Atlantic Ocean region, Theor. Appl. Climatol., 104 (2011), 377-385. doi: 10.1007/s00704-010-0350-3
|
| [3] |
R. Potocky, M. Stehlik, H. Waldl, On sums of claims and their applications in analysis of pension funds and insurance products, Prague Econ. Pap., 23 (2014), 349-370. doi: 10.18267/j.pep.488
|
| [4] |
P. Jordanova, Z. Fabian, P. Hermann, L. Střelec, A. Rivera, S. Girard, et al., Weak properties and robustness of t-hill estimators, Extremes, 19 (2016), 591-626. doi: 10.1007/s10687-016-0256-2
|
| [5] |
M. Stehlík, L. N. Soza, Z. Fabián, M. Jiřina, P. Jordanova, S. C. Arancibia, et al., On ecological aspects of dynamics for zero slope regression for water pollution in Chile, Stochastic Anal. Appl., 37 (2019), 574-601. doi: 10.1080/07362994.2019.1592692
|
| [6] |
J. Pickands, Statistical inference using extreme order statistics, Ann. Stat., 3 (1975), 119-131. doi: 10.1214/aos/1176343003
|
| [7] | J. Hosking, J. Wallis, Parameters and quantile estimation for the generalized pareto distribution, Technometrics, 29 (1998), 339-349. |
| [8] |
S. Juarez, W. Schucany, Robust and efficient estimation for the generalized pareto distribution, Extremes, 7 (2004), 237-251. doi: 10.1007/s10687-005-6475-6
|
| [9] |
J. Zhang, Likelihood moment estimation for the generalized pareto distribution, Aust. N. Z. J. Stat., 49 (2007), 69-77. doi: 10.1111/j.1467-842X.2006.00464.x
|
| [10] |
J. Zhang, Improving on estimation for the generalized pareto distribution, Technometrics, 52 (2010), 335-339. doi: 10.1198/TECH.2010.09206
|
| [11] |
J. Zhang, M. Stephens, A new and efficient estimation method for the generalized pareto distribution, Technometrics, 51 (2009), 316-325. doi: 10.1198/tech.2009.08017
|
| [12] |
J. He, Z. Sheng, B. Wang, K. Yu, Point and exact interval estimation for the generalized Pareto distribution with small samples, Stats its interface, 7 (2014), 389-404. doi: 10.4310/SII.2014.v7.n3.a9
|
| [13] |
J. Song, S. Song, A quantile estimation for massive data with generalized Pareto distribution, Comput. Stat. Data Anal., 56 (2012), 143-150. doi: 10.1016/j.csda.2011.06.030
|
| [14] |
M. H. Park, J. H. T. Kim, Estimating extreme tail risk measures with generalized Pareto distribution, Comput. Stat. Data Anal., 98 (2016), 91-104. doi: 10.1016/j.csda.2015.12.008
|
| [15] |
S. Kang, J. Song, Parameter and quantile estimation for the generalized pareto distribution in peaks over threshold framework, J. Korean Stat. Soc., 46 (2017), 487-501. doi: 10.1016/j.jkss.2017.02.003
|
| [16] |
S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Eckstein, Distributed optimization and statistical learning via the alternating direction method of multipliers, Found. Trends Mach. Learn., 3 (2010), 1-122. doi: 10.1561/2200000016
|
| [17] |
E. Chu, A. Keshavarz, S. Boyd, A distributed algorithm for fitting generalized additive models, Optim. Eng., 14 (2013), 213-224. doi: 10.1007/s11081-013-9215-9
|
| [18] |
X. Yuan, Alternating direction method for covariance selection models, J. Sci. Comput., 51 (2012), 261-273. doi: 10.1007/s10915-011-9507-1
|
| [19] |
Y. Gu, J. Fan, L. Kong, S. Ma, H. Zou, ADMM for high-dimensional sparse penalized quantile regression, Technometrics, 60 (2018), 319-331, doi: 10.1080/00401706.2017.1345703
|
| [20] | M. Hong, Z. Q. Luo, M. Razaviyayn, Convergence analysis of alternating direction method of multipliers for a family of non-convex problems, SIAM J. Optim., 26 (2014), 3836-3840. |
| [21] |
B. He, X. Yuan, On the O(1/n) convergence rate of the douglas-rachford alternating direction method, SIAM J. Numer. Anal., 50 (2012), 700-709. doi: 10.1137/110836936
|
| [22] |
W. Deng, W. Yin, On the global and linear convergence of the generalized slternating direction method of multipliers, J. Sci. Comput., 66 (2016), 889-916. doi: 10.1007/s10915-015-0048-x
|
| [23] | J. Liu, S. J. Wright, C. Ré, V. Bittorf, S. Sridhar, An asynchronous parallel stochastic coordinate descent algorithm, J. Mach. Learn. Res., 16 (2013), 285-322. |
| [24] |
H. R. Feyzmahdavian, A. Aytekin, M. Johansson, An asynchronous mini-batch algorithm for regularized stochastic optimization, IEEE Trans. Autom. Control, 61 (2016), 3740-3754. doi: 10.1109/TAC.2016.2525015
|
| [25] | A. McNeil, T. Saladin, The peaks over thresholds method for estimating high quantiles of loss distributions, Proc. 28th Int. ASTIN Colloq., (1997), 23-43. |
| [26] | A. A. Balkema, L. de Haan, Residual life time at great age, Ann. Probab., 2 (2004), 792-804. |
| [27] | P. Embrechts, C. Kluppelberg, T. Mikosch, Modelling Extremal Events for Insurance and Finance, Springer-Verlag, Berlin Heidelberg, 1997. |
| [28] |
H. Zhu, A. Cano, G. Giannakis, Distributed consensus-based demodulation: Algorithms and error analysis, IEEE Trans. Wireless Commun., 9 (2010), 2044-2054. doi: 10.1109/TWC.2010.06.090890
|
 mbe-18-01-011- supplementary.pdf mbe-18-01-011- supplementary.pdf |
 |
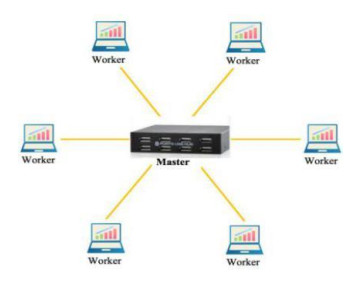
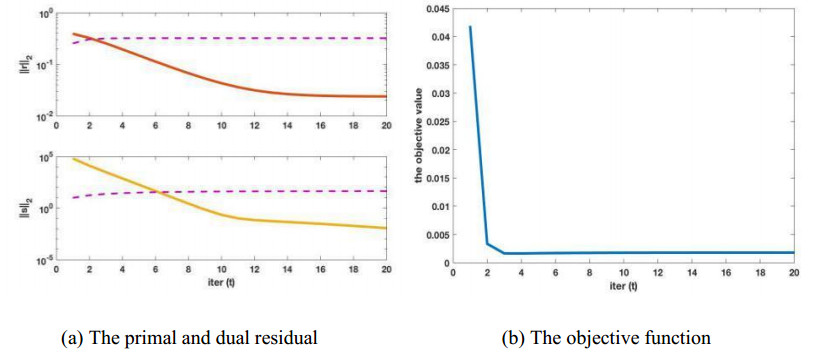
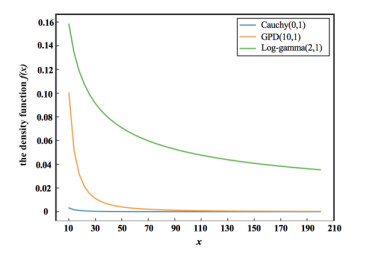
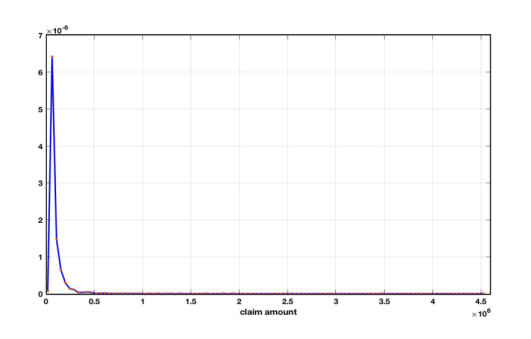
Figures(4) / Tables(4)

Xiaoyue Xie, Jian Shi. A distributed quantile estimation algorithm of heavy-tailed distribution with massive datasets[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 214-230. doi: 10.3934/mbe.2021011







 DownLoad:
DownLoad: