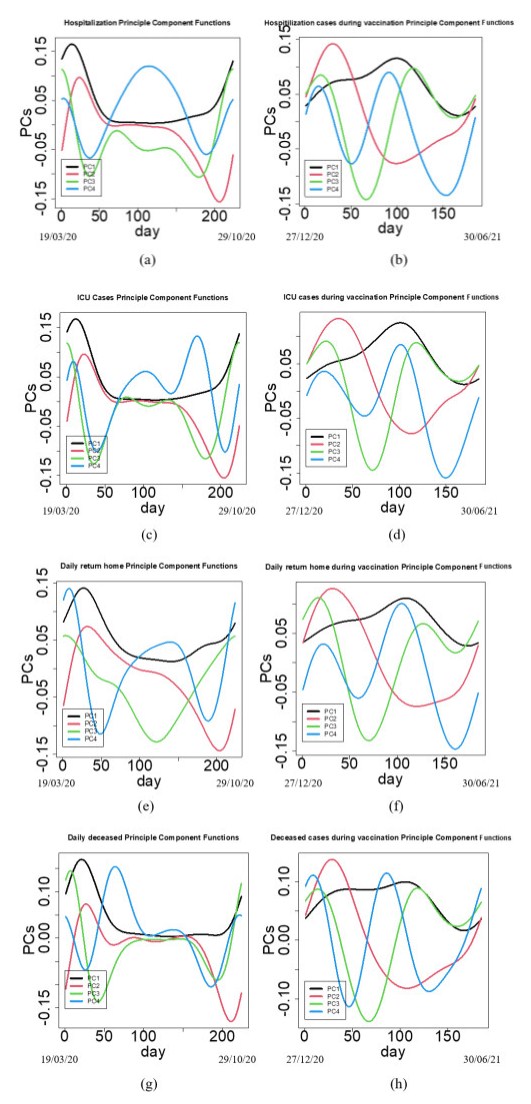
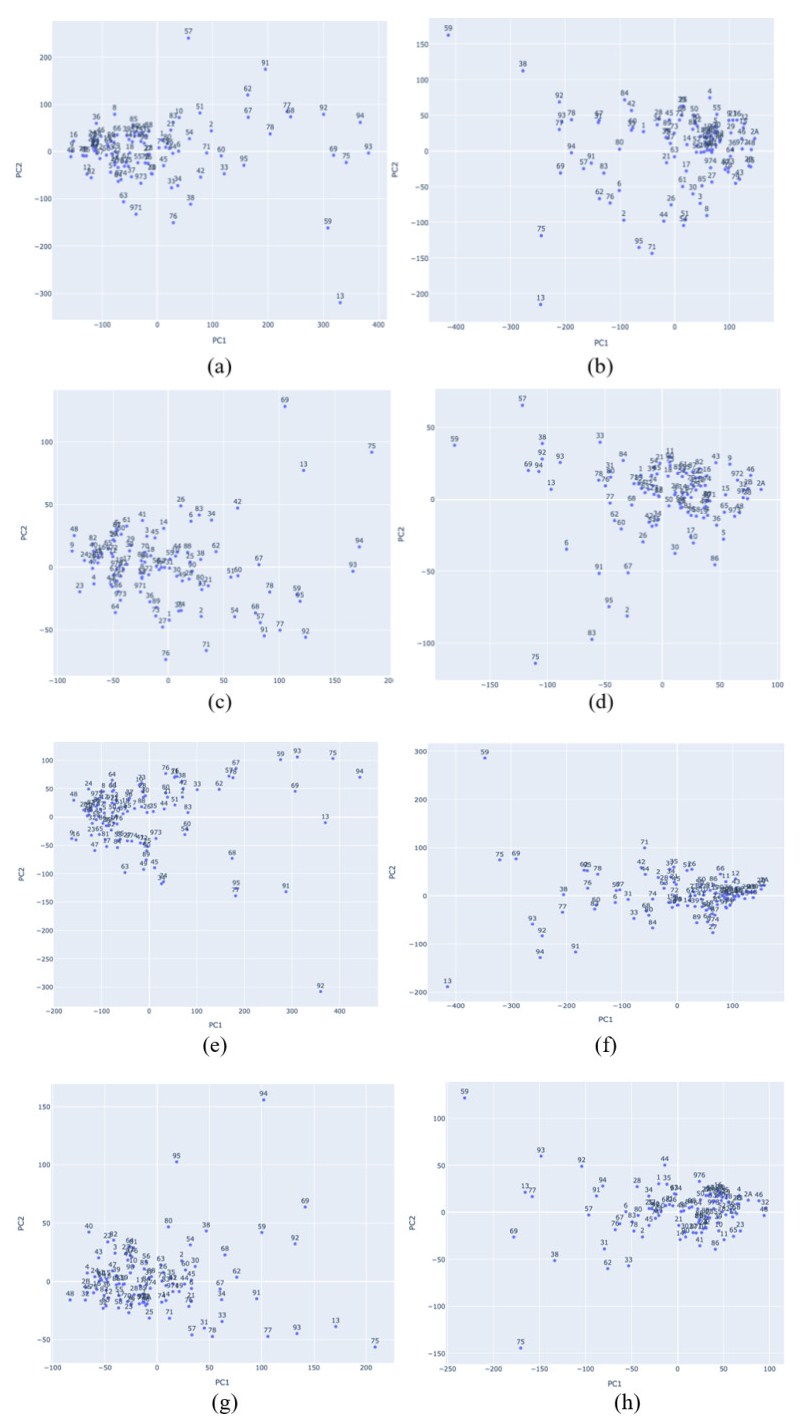
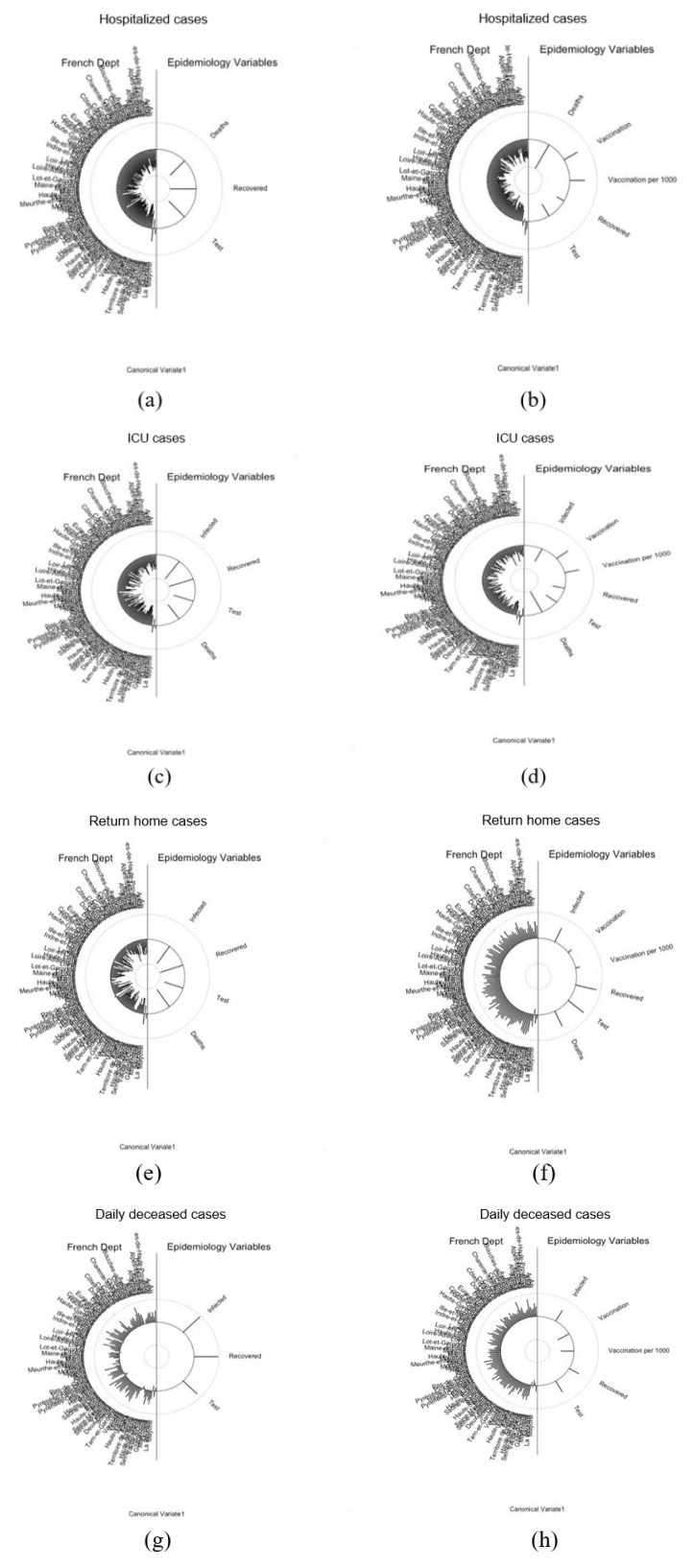
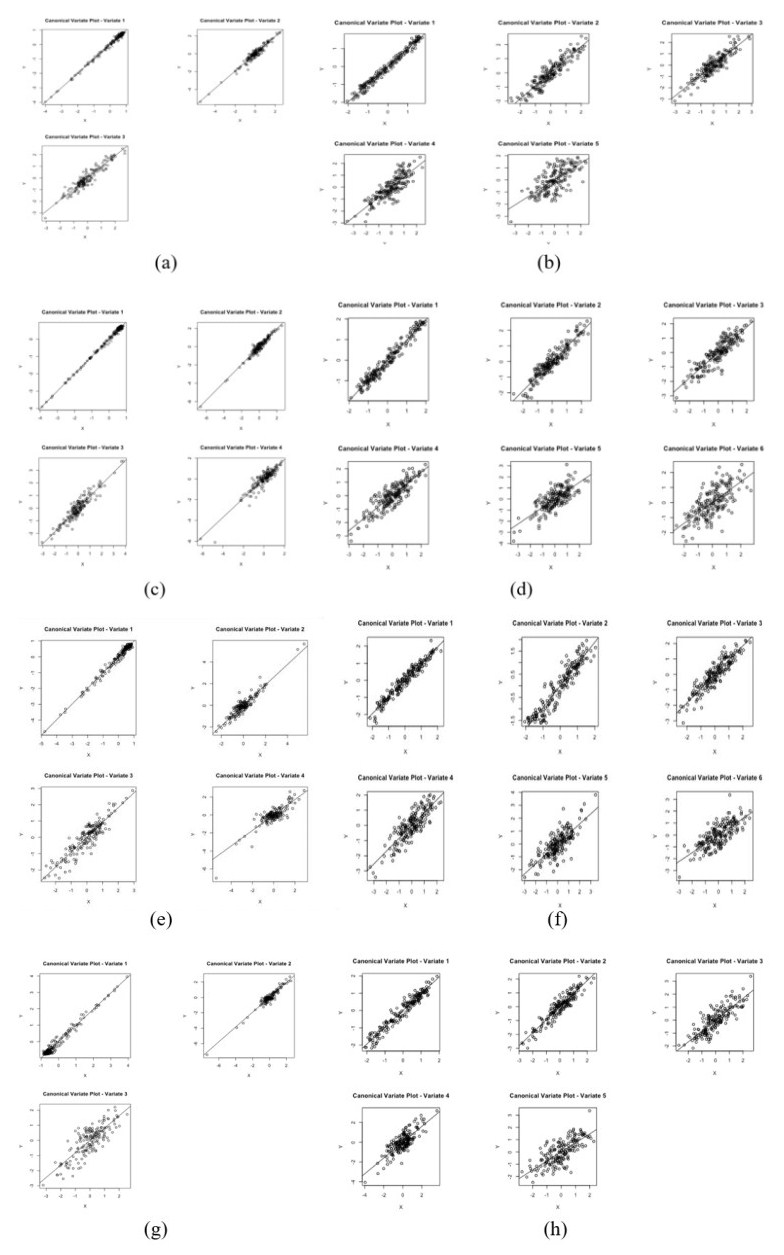
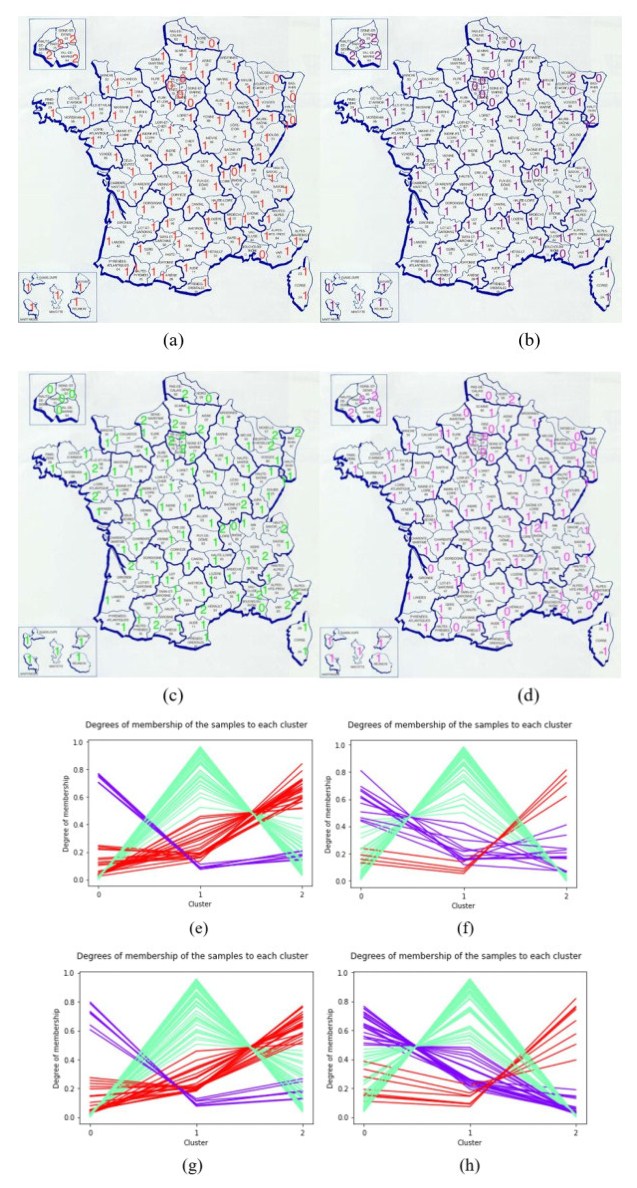
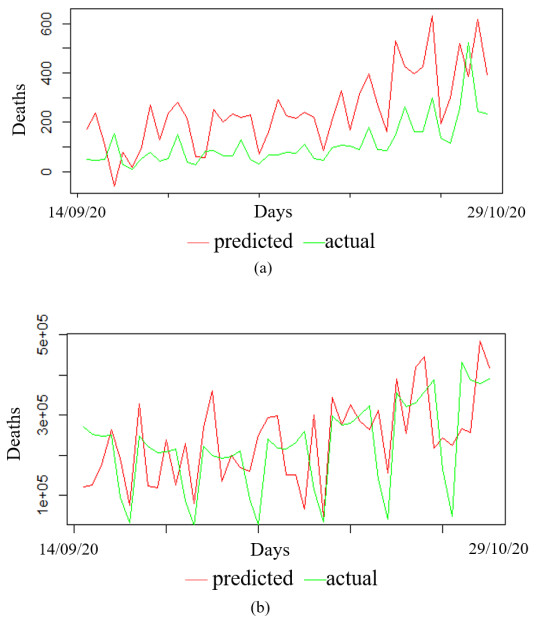
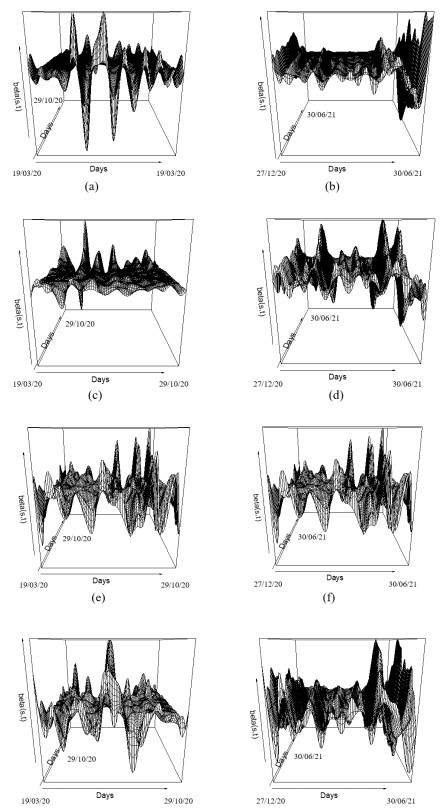
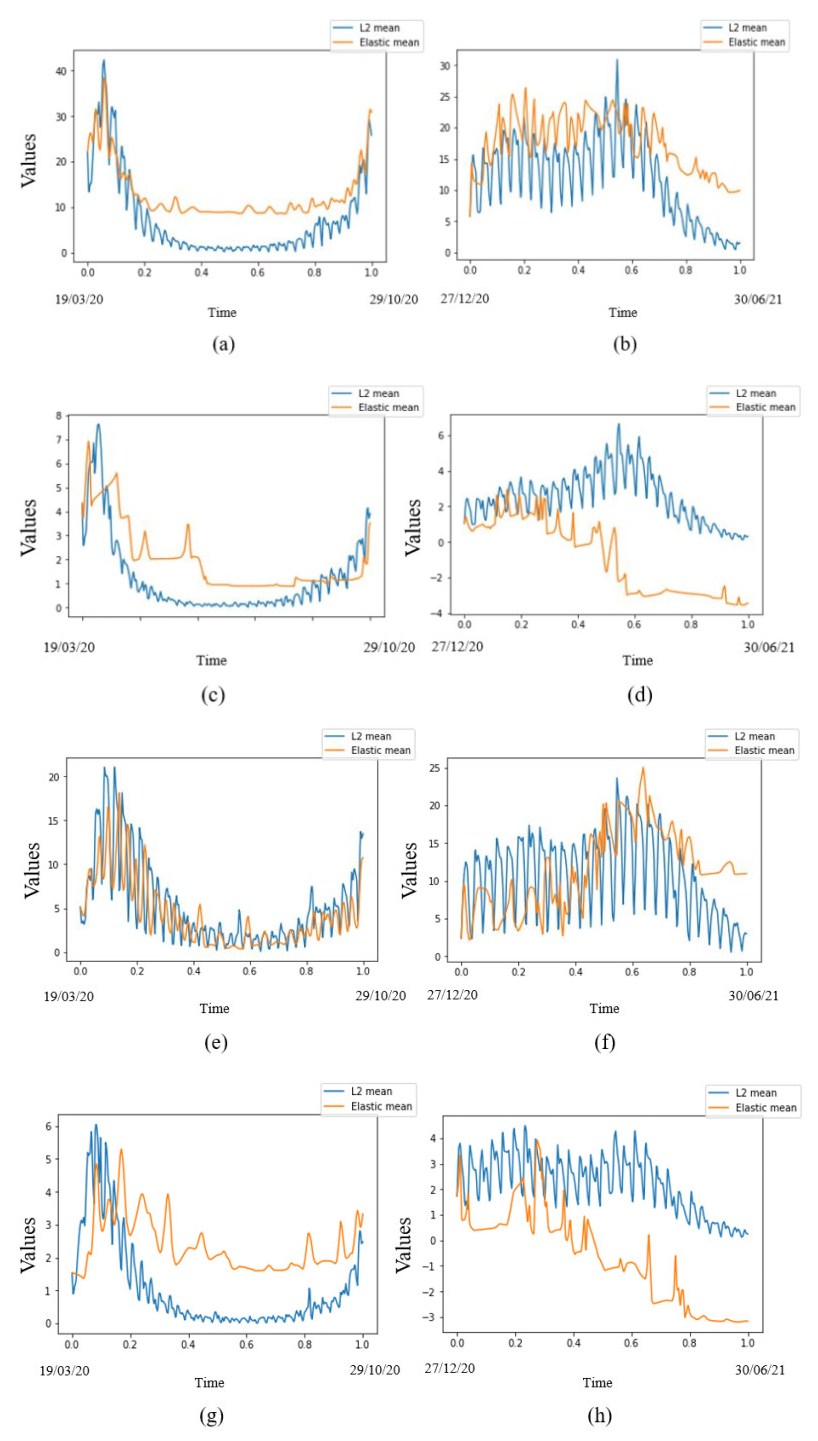
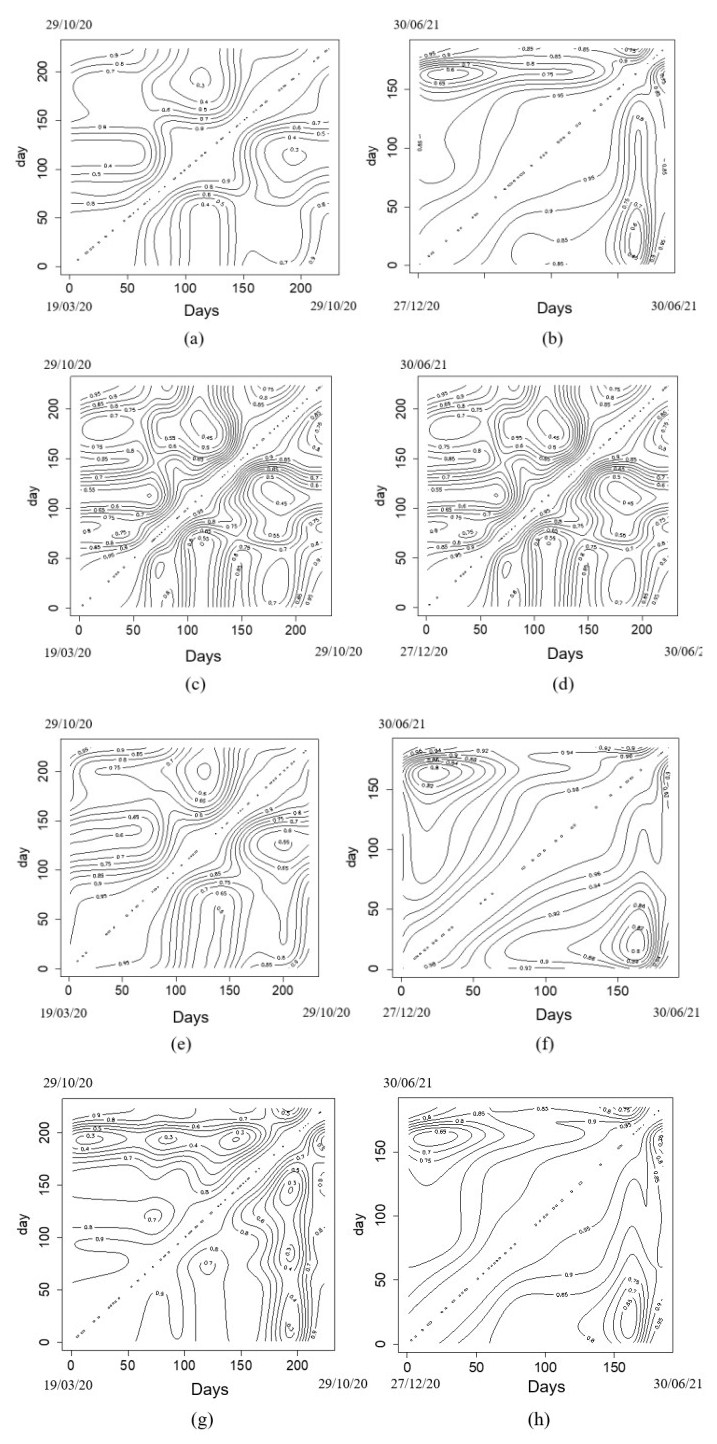
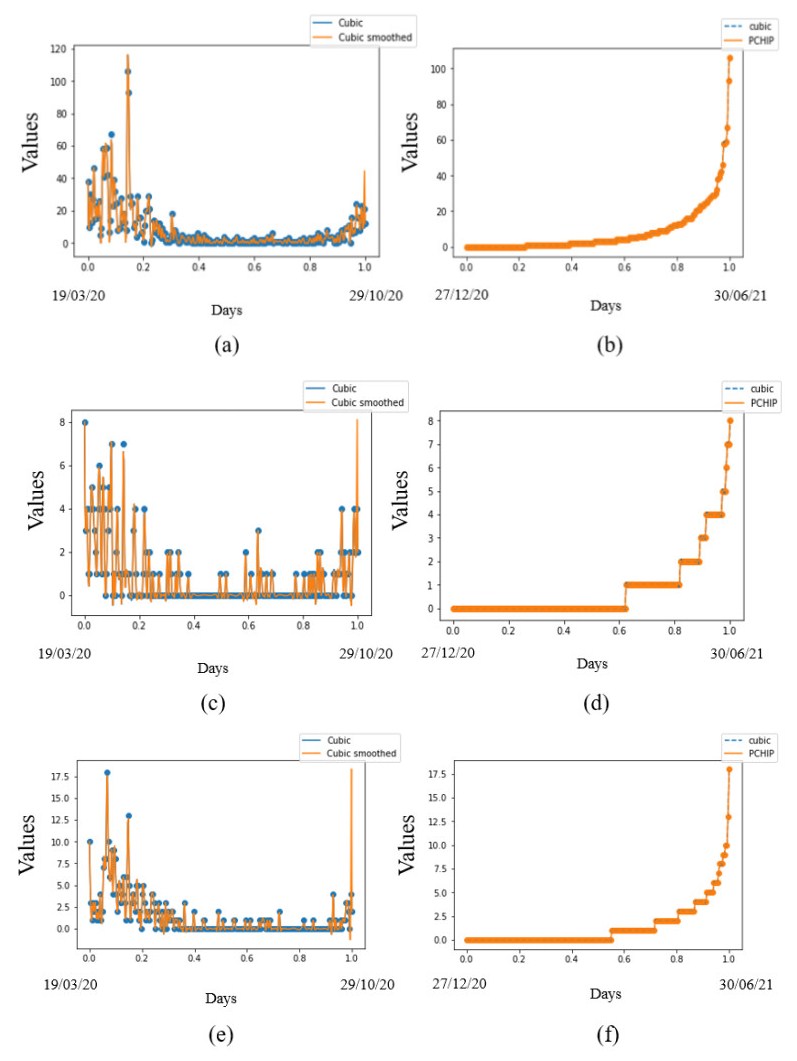
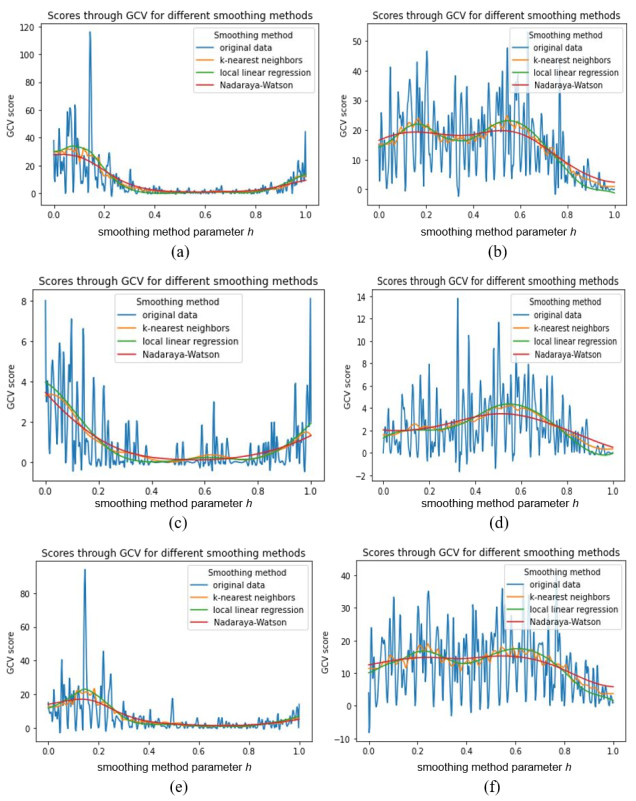
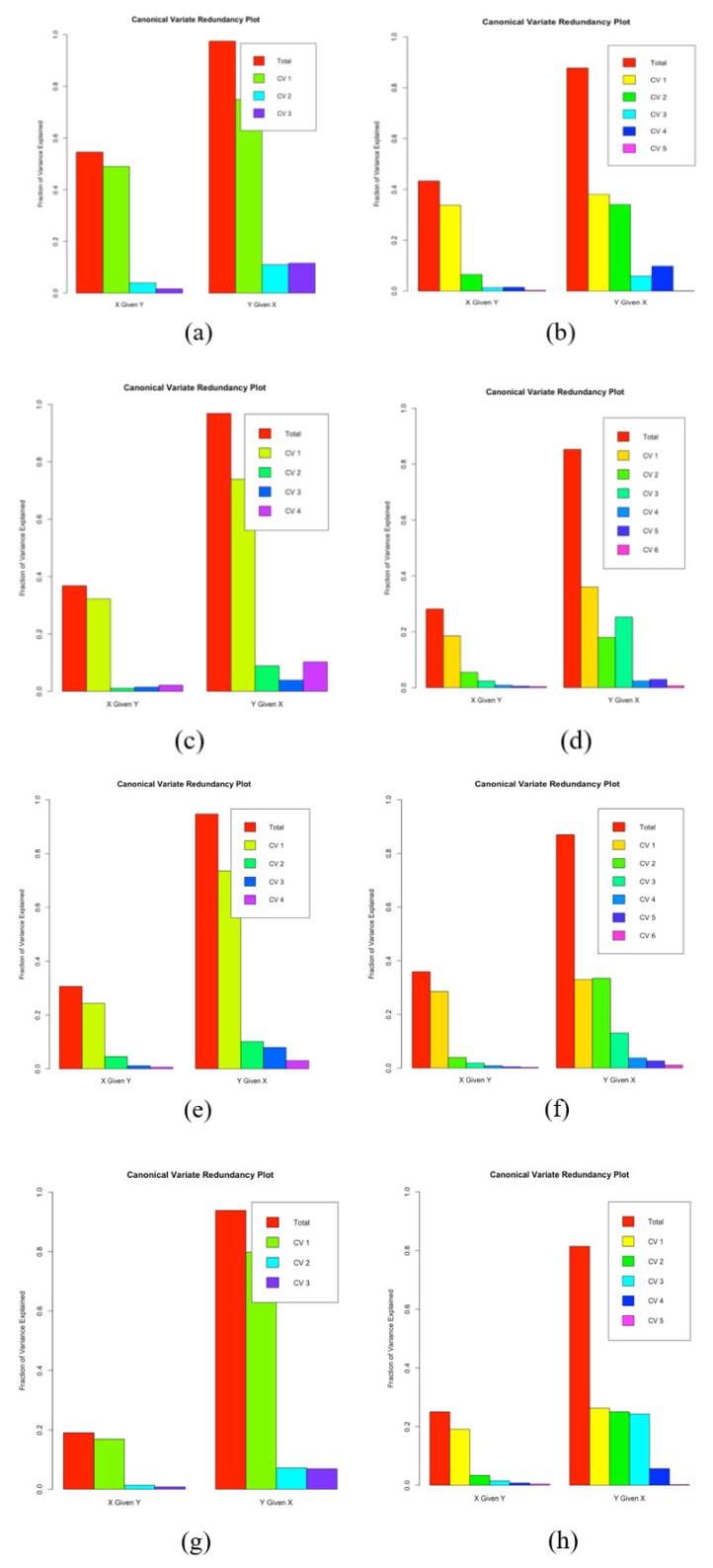
In this paper we use the technique of functional data analysis to model daily hospitalized, deceased, Intensive Care Unit (ICU) cases and return home patient numbers along the COVID-19 outbreak, considered as functional data across different departments in France while our response variables are numbers of vaccinations, deaths, infected, recovered and tests in France. These sets of data were considered before and after vaccination started in France. After smoothing our data set, analysis based on functional principal components method was performed. Then, a clustering using k-means techniques was done to understand the dynamics of the pandemic in different French departments according to their geographical location on France map. We also performed canonical correlations analysis between variables. Finally, we made some predictions to assess the accuracy of the method using functional linear regression models.
Citation: Kayode Oshinubi, Firas Ibrahim, Mustapha Rachdi, Jacques Demongeot. Functional data analysis: Application to daily observation of COVID-19 prevalence in France[J]. AIMS Mathematics, 2022, 7(4): 5347-5385. doi: 10.3934/math.2022298
In this paper we use the technique of functional data analysis to model daily hospitalized, deceased, Intensive Care Unit (ICU) cases and return home patient numbers along the COVID-19 outbreak, considered as functional data across different departments in France while our response variables are numbers of vaccinations, deaths, infected, recovered and tests in France. These sets of data were considered before and after vaccination started in France. After smoothing our data set, analysis based on functional principal components method was performed. Then, a clustering using k-means techniques was done to understand the dynamics of the pandemic in different French departments according to their geographical location on France map. We also performed canonical correlations analysis between variables. Finally, we made some predictions to assess the accuracy of the method using functional linear regression models.

| [1] | D. Bernoulli, Essai d'une nouvelle analyse de la mortalité causée par la petite vérole, et des avantages de l'inoculation pour la prévenir, Histoire de l'Acad., Roy. Sci. (Paris) avec Mem, 1760, 1–45. |
| [2] |
D. A. Henderson, The eradication of smallpox-An overview of the past, present, and future, Vaccine, 29 (2011), D7–D9. https://doi.org/10.1016/j.vaccine.2011.06.080 doi: 10.1016/j.vaccine.2011.06.080

|
| [3] | D. Wujastyk, Medicine in India, In: J. van Alphen, A. Aris, F. Meyer, M. de Fraeye, Oriental medicine: An illustrated guide to the Asian arts of healing, London: Serindia Publications, 1995, 19–38. |
| [4] | A. M. Silverstein, A history of immunology, 2 Eds., London: Academic Press, 2009,293. |
| [5] | L. S. Benjamin, L Melville, Lady Mary Wortley Montagu, her life and letters (1689–1762), Hutchinson, London, 1925. |
| [6] |
R. Ross, An application of the theory of probabilities to the study of a priori pathometry-part I, Proc. R. Soc. Ser. A, 92 (1916), 204–230. https://doi.org/10.1098/rspa.1916.0007 doi: 10.1098/rspa.1916.0007
|
| [7] |
A. G. McKendrick, Applications of mathematics to medical problems, Proc. Edinburgh Math. Soc., 44 (1925), 98–130. https://doi.org/10.1017/S0013091500034428 doi: 10.1017/S0013091500034428
|
| [8] |
J. Gaudart, O. Touré, N. Dessay, A. L. Dicko, S. Ranque, L. Forest, et al., Modelling malaria incidence with environmental dependency in a locality of Sudanese savannah area, Mali. Malaria J., 8 (2009), 61. https://doi.org/10.1186/1475-2875-8-61 doi: 10.1186/1475-2875-8-61
|
| [9] |
J. Gaudart, M. Ghassani, J. Mintsa, M. Rachdi, J. Waku, J. Demongeot, Demography and diffusion in epidemics: Malaria and black death spread, Acta Biotheor., 58 (2010), 277–305. https://doi.org/10.1007/s10441-010-9103-z doi: 10.1007/s10441-010-9103-z
|
| [10] |
J. Demongeot, J. Gaudart, A. Lontos, E. Promayon, J. Mintsa, M. Rachdi, Zero-diffusion domains in reaction-diffusion morphogenetic and epidemiologic processes, Int. J. Bifurcation Chaos, 22 (2012), 1250028. https://doi.org/10.1142/S0218127412500289 doi: 10.1142/S0218127412500289
|
| [11] |
J. Demongeot, J. Gaudart, J. Mintsa, M. Rachdi, Demography in epidemics modelling, Commun. Pure Appl. Anal., 11 (2012), 61–82. http://dx.doi.org/10.3934/cpaa.2012.11.61 doi: 10.3934/cpaa.2012.11.61
|
| [12] |
Z. Liu, P. Magal, O. Seydi, G. Webb, Understanding unreported cases in the COVID-19 epidemic outbreak in Wuhan, China, and importance of major public health interventions, Biology, 9(2020), 50. https://doi.org/10.3390/biology9030050 doi: 10.3390/biology9030050
|
| [13] |
J. Demongeot, Q. Griette, P. Magal, SI epidemic model applied to COVID-19 data in mainland China, Royal Soc. Open Sci., 7 (2020), 201878. https://doi.org/10.1098/rsos.201878 doi: 10.1098/rsos.201878
|
| [14] |
Z. Liu, P. Magal, O. Seydi, G. Webb, Predicting the cumulative number of cases for the COVID-19 epidemic in China from early data, Math. Biosci. Eng., 17 (2020), 3040–3051. https://doi.org/10.3934/mbe.2020172 doi: 10.3934/mbe.2020172
|
| [15] |
P. Magal, O. Seydi, G. Webb, Y. Wu, A model of vaccination for Dengue in the Philippines 2016–2018, Front. Appl. Math. Stat., 7 (2021), 760259. https://doi.org/10.3389/fams.2021.760259 doi: 10.3389/fams.2021.760259
|
| [16] | K. Oshinubi, M. Rachdi, J. Demongeot, Modelling of COVID-19 pandemic vis-à-vis some socioeconomic factors, Front. Appl. Math. Stat., 7 (2021), 786983. |
| [17] | COVID-19 coronavirus pandemic, 2021. Available from: https://www.worldometers.info/coronavirus. |
| [18] | Données hospitalières relatives à l'épidémie de COVID-19, 2021. Available from: https://www.data.gouv.fr/fr/datasets/donnees-hospitalieres-relatives-a-lepidemie-de-Covid-19. |
| [19] | Live COVID-19 vaccination tracker. Available from: https://covidvax.live/location/fra. |
| [20] | F. Ferraty, P. Vieu, Nonparametric functional data analysis, New York: Springer, 2006. https://doi.org/10.1007/0-387-36620-2 |
| [21] | J. D. Tucker, Functional component analysis and regression using elastic methods, PhD. Thesis, Florida State University, 2014. |
| [22] |
J. D. Tucker, W. Wu, A. Srivastava, Generative models for functional data using phase and amplitude separation, Comput. Stat. Data Anal., 61 (2013), 50–66. https://doi.org/10.1016/j.csda.2012.12.001 doi: 10.1016/j.csda.2012.12.001
|
| [23] | J. O. Ramsay, B. W. Silverman, Applied functional data analysis: Methods and case studies, New York: Springer, 2002. https://doi.org/10.1007/b98886 |
| [24] | A. Srivastava, E. P. Klassen, Functional data and elastic registration, In: Functional and shape data analysis, New York: Springer, 2016, 73–123. https://doi.org/10.1007/978-1-4939-4020-2_4 |
| [25] | J. O. Ramsay, G. Hooker, S. Graves, Functional data analysis with R and MATLAB, New York: Springer, 2009. https://doi.org/10.1007/978-0-387-98185-7 |
| [26] | C. Tang, T. Wang, P. Zhang, Functional data analysis: An application to COVID-19 data in the United States, arXiv. Available from: https://arXiv.org/abs/2009.08363. |
| [27] |
C. Acal, M. Escabias, A. M. Aguilera, M. J. Valderrama, COVID-19 data imputation by multiple function-on-function principal component regression, Mathematics, 9 (2021), 1237. https://doi.org/10.3390/math9111237 doi: 10.3390/math9111237
|
| [28] |
T. Boschi, J. Di Iorio, L. Testa, M. A. Cremona, F. Chiaromonte, Functional data analysis characterizes the shapes of the first COVID-19 epidemic wave in Italy, Sci. Rep., 11 (2021), 17054. https://doi.org/10.1038/s41598-021-95866-y doi: 10.1038/s41598-021-95866-y
|
| [29] |
Q. Griette, J. Demongeot, P. Magal, A robust phenomenological approach to investigate COVID-19 data for France, Math. Appl. Sci. Eng., 2 (2021), 149–218. https://doi.org/10.5206/mase/14031 doi: 10.5206/mase/14031
|
| [30] |
Q. Griette, J. Demongeot, P. Magal, What can we learn from COVID-19 data by using epidemic models with unidentied infectious cases, Math. Biosci. Eng., 2 (2021), 149–160. http://dx.doi.org/10.2139/ssrn.3868852 doi: 10.2139/ssrn.3868852
|
| [31] |
J. Gaudart, J. Landier, L. Huiart, E. Legendre, L. Lehot, M. K. Bendiane, et al., Factors associated with spatial heterogeneity of Covid-19 in France: A nationwide ecological study, Lancet Public Health, 6(2021), 222–231. https://doi.org/10.1016/s2468-2667(21)00006-2 doi: 10.1016/S2468-2667(21)00006-2
|
| [32] |
O. D. Ilie, R. O. Cojocariu, A. Ciobica, S. I. Timofte, I. Mavroudis, B. Doroftei, Forecasting the spreading of COVID-19 across nine countries from Europe, Asia, and the American continents using the ARIMA models, Microorganisms, 8 (2020), 1158. https://doi.org/10.3390/microorganisms8081158 doi: 10.3390/microorganisms8081158
|
| [33] |
J. Stojanovic, V. G. Boucher, J. Boyle, J. Enticott, K. L. Lavoie, S. L. Bacon, COVID-19 is not the flu: Four graphs from four countries, Front. Public Health, 2021, 628479. https://doi.org/10.3389/fpubh.2021.628479 doi: 10.3389/fpubh.2021.628479
|
| [34] |
C. Carroll, S. Bhattacharjee, Y. Chen, P. Dubey, J. Fan, A. Gajardo, et al., Time dynamics of COVID-19, Sci. Rep., 10 (2020), 21040. https://doi.org/10.1038/s41598-020-77709-4 doi: 10.1038/s41598-020-77709-4
|
| [35] |
A. Srivastava, G. Chowell, Modeling study: Characterizing the spatial heterogeneity of the COVID-19 pandemic through shape analysis of epidemic curves, Res. Square, 2021, 1–27. https://doi.org/10.21203/rs.3.rs-223226/v1 doi: 10.21203/rs.3.rs-223226/v1
|
| [36] |
J. Demongeot, Y. Flet-Berliac, H. Seligmann, Temperature decreases spread parameters of the new COVID-19 cases dynamics, Biology, 9 (2020), 94. https://doi.org/10.3390/biology9050094 doi: 10.3390/biology9050094
|
| [37] |
H. Seligmann, S. Iggui, M. Rachdi, N. Vuillerme, J. Demongeot, Inverted covariate effects for mutated 2nd vs 1st wave COVID-19: High temperature spread biased for young, Biology, 9 (2020), 226. https://doi.org/10.1101/2020.07.12.20151878 doi: 10.3390/biology9080226
|
| [38] |
S. Soubeyrand, J. Demongeot, L. Roques, Towards unified and real-time analyses of outbreaks at country-level during pandemics, One Health, 11 (2020), 100187. https://doi.org/10.1016/j.onehlt.2020.100187 doi: 10.1016/j.onehlt.2020.100187
|
| [39] |
J. Demongeot, H. Seligmann, SARS-CoV-2 and miRNA-like inhibition power, Med. Hypotheses, 144 (2020), 110245. https://doi.org/10.1016/j.mehy.2020.110245 doi: 10.1016/j.mehy.2020.110245
|
| [40] |
H. Seligmann, N. Vuillerme, J. Demongeot, Unpredictable, counter-intuitive geoclimatic and demographic correlations of COVID-19 spread rates, Biology, 10 (2021), 623. https://doi.org/10.3390/biology10070623 doi: 10.3390/biology10070623
|
| [41] |
K. Oshinubi, F. Al-Awadhi, M. Rachdi, J. Demongeot, Data analysis and forecasting of COVID-19 pandemic in Kuwait, MedRxiv, 2021, 1–17. https://doi.org/10.1101/2021.07.24.21261059 doi: 10.1101/2021.07.24.21261059
|
| [42] |
J. Demongeot, K. Oshinubi, M. Rachdi, L. Hobbad, M. Alahiane, S. Iggui, et al., The application of ARIMA model to analyze COVID-19 incidence pattern in several countries, J. Math. Comput. Sci., 12 (2022), 1–23. https://doi.org/10.28919/jmcs/6541 doi: 10.28919/jmcs/6541
|
| [43] |
K. Oshinubi, M. Rachdi, J. Demongeot, Analysis of reproduction number R0 of COVID-19 using current health expenditure as gross domestic product percentage (CHE/GDP) across countries, Healthcare, 9 (2021), 1247. https://doi.org/10.3390/healthcare9101247 doi: 10.3390/healthcare9101247
|
| [44] |
J. Demongeot, K. Oshinubi, M. Rachdi, H. Seligmann, F. Thuderoz, J. Waku, Estimation of daily reproduction rates in COVID-19 outbreak, MedRxiv, 9 (2021), 109. https://doi.org/10.1101/2020.12.30.20249010 doi: 10.1101/2020.12.30.20249010
|
| [45] |
J. Demongeot, A. Laksaci, F. Madani, M. Rachdi, Functional data: Local linear estimation of the conditional density and its application, Statistics, 47 (2013), 26–44. https://doi.org/10.1080/02331888.2011.568117 doi: 10.1080/02331888.2011.568117
|
| [46] |
M. Rachdi, A. Laksaci, J. Demongeot, A. Abdali, F. Madani, Theoretical and practical aspects on the quadratic error in the local linear estimation of the conditional density for functional data, Comput. Stat. Data Anal., 73 (2014), 53–68. https://doi.org/10.1016/j.csda.2013.11.011 doi: 10.1016/j.csda.2013.11.011
|
| [47] |
J. Demongeot, A. Laksaci, M. Rachdi, S. Rahmani, On the local linear modelization of the conditional distribution for functional data, Sankhya A, 76 (2014), 328–355. https://doi.org/10.1007/s13171-013-0050-z doi: 10.1007/s13171-013-0050-z
|
| [48] |
J. Demongeot, A. Hamie, A. Laksaci, M. Rachdi, Relative-error prediction in nonparametric functional statistics: Theory and practice, J. Multivar. Anal., 146 (2016), 261–268. https://doi.org/10.1016/j.jmva.2015.09.019 doi: 10.1016/j.jmva.2015.09.019
|
| [49] |
J. Demongeot, A. Laksaci, A. Naceri, M. Rachdi, Local linear regression modelization when all variables are curves, Stat. Probab. Lett., 121 (2017), 37–44. https://doi.org/10.1016/j.spl.2016.09.021 doi: 10.1016/j.spl.2016.09.021
|
| [50] |
A. Belkis, J. Demongeot, A. Laksaci, M. Rachdi, Functional data analysis: Estimation of the relative error in functional regression under random left-truncation, J. Nonparametr. Stat., 30 (2018), 472–490. https://doi.org/10.1080/10485252.2018.1438609 doi: 10.1080/10485252.2018.1438609
|
| [51] |
A. Henien, L. Ait-Hennani, J. Demongeot, A. Laksaci, M. Rachdi, Heteroscedasticity test when the covariables are functionals, C. R. Math., 356 (2018), 571–574. https://doi.org/10.1016/j.crma.2018.02.010 doi: 10.1016/j.crma.2018.02.010
|
| [52] |
J. Demongeot, O. Hansen, H. Hessami, A. S. Jannot, J. Mintsa, M. Rachdi, et al., Random modelling of contagious diseases, Acta Biotheor., 61 (2013), 141–172. https://doi.org/10.1007/s10441-013-9176-6 doi: 10.1007/s10441-013-9176-6
|
| [53] |
C. J. Rhodes, L. Demetrius, Evolutionary entropy determines invasion success in emergent epidemics, PLoS One, 5 (2010), e12951. https://doi.org/10.1371/journal.pone.0012951 doi: 10.1371/journal.pone.0012951
|
| [54] |
S. Triambak, D. P. Mahapatra, A random walk Monte Carlo simulation study of COVID-19-like infection spread, Physica A: Stat. Mech. Appl., 574 (2021), 126014. https://doi.org/10.1016/j.physa.2021.126014 doi: 10.1016/j.physa.2021.126014
|
| [55] | Wikipedia, Available online: https://www.wikipedia.org/wiki/Departments_of_France. |
Figures(16) / Tables(4)

Kayode Oshinubi, Firas Ibrahim, Mustapha Rachdi, Jacques Demongeot. Functional data analysis: Application to daily observation of COVID-19 prevalence in France[J]. AIMS Mathematics, 2022, 7(4): 5347-5385. doi: 10.3934/math.2022298







 DownLoad:
DownLoad: