Citation: Laiq Zada, Rashid Nawaz, Sumbal Ahsan, Kottakkaran Sooppy Nisar, Dumitru Baleanu. New iterative approach for the solutions of fractional order inhomogeneous partial differential equations[J]. AIMS Mathematics, 2021, 6(2): 1348-1365. doi: 10.3934/math.2021084

| [1] | Podlubny, Fractional Differential Equations, Academic Press, New York, 1999. |
| [2] |
L. Debnath, Recent applications of fractional calculus to science and engineering, Int. J. Math. Math. Sci, 2003 (2003), 3413-3442. doi: 10.1155/S0161171203301486

|
| [3] | K. S. Miller, B. Ross, An Introduction to the Fractional Calculus and Fractional Differential Equations, Wiley, New York, 1993. |
| [4] | K. B. Oldham, J. Spanier, The Fractional Calculus: Integrations and Differentiations of Arbitrary Order, Academic Press, New York, 1974. |
| [5] | G. Adomian, Solving Frontier Problems of Physics: The Decomposition Method, Kluwer Academic Publishers, 1994. |
| [6] | G. Adomian, R. Rach, Modified Adomian polynomials, Math. Comput. Model., 24 (1996), 39-46. |
| [7] | W. H. Deng, Finite element method for the space and time fractional Fokker-Planck equation, SIAM J. Numer. Anal., 47 (2008), 204-226. |
| [8] |
J. H. He, Variational iteration method a kind of non-linear analytical technique: some examples, Int. J. Nonlin. Mech., 34 (1999), 699-708. doi: 10.1016/S0020-7462(98)00048-1
|
| [9] |
N. H. Sweilam, M. M. Khader, Variational iteration method for one dimensional nonlinear thermoelasticity, Chaos, Soliton. Fract., 32 (2007), 145-149. doi: 10.1016/j.chaos.2005.11.028
|
| [10] |
S. Abbasbandy, The application of homotopy analysis method to nonlinear equations arising in heat transfer, Phys. Lett. A, 360 (2006), 109-113. doi: 10.1016/j.physleta.2006.07.065
|
| [11] |
J. H. He, Homotopy perturbation technique, Comput. Method. Appl. M., 178 (1999), 257-262. doi: 10.1016/S0045-7825(99)00018-3
|
| [12] |
V. Daftardar-Gejji, H. Jafari, An iterative method for solving nonlinear functional equations, J. Math. Anal. Appl., 316 (2006), 753-763. doi: 10.1016/j.jmaa.2005.05.009
|
| [13] | V. Daftardar-Gejji, S. Bhalekar, Solving fractional diffusion-wave equations using a new iterative method, Fract. Calc. Appl. Anal., 11 (2008), 193-202. |
| [14] | R. Y. Molliq, M. S. M. Nooorani, Solving the fractional Rosenau-Hyman equation via variational iteration method and homotopy perturbation method, International Journal Differential Equations, 2012 (2012), 1-14. |
| [15] | J. Garralón, F. R. Villatoro, Dissipative perturbations for the K(n, n) Rosenau-Hyman equation, Commun. Nonlinear Sci., 17 (2012), 4642-4648. |
| [16] | M. Dehghan, J. Manafian, A. Saadatmandi, Application of semi-analytical methods for solving the Rosenau-Hyman equation arising in the pattern formation in liquid drops, Int. J. Numer. Method. H., 22 (2013), 777-790. |
| [17] |
H. F. Ahmed, M. S. M. Bahgat, M. Zaki, Numerical approaches to system of fractional partial differential equations, Journal of the Egyptian Mathematical Society, 25 (2017), 141-150. doi: 10.1016/j.joems.2016.12.004
|
| [18] | H. Zhang, X. Jiang, X. Yang, A time-space spectral method for the time-space fractional Fokker-Planck equation and its inverse problem, Appl. Math. Comput., 320 (2018), 302-318. |
| [19] |
B. Yu, X. Jiang, H. Xu, A novel compact numerical method for solving the two-dimensional non-linear fractional reaction-subdiffusion equation, Numer. Algorithms, 68 (2015), 923-950. doi: 10.1007/s11075-014-9877-1
|
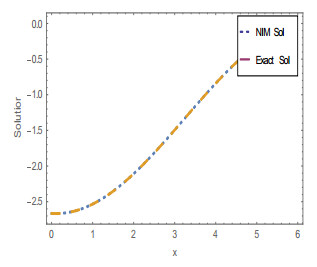
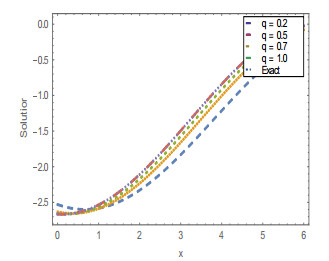
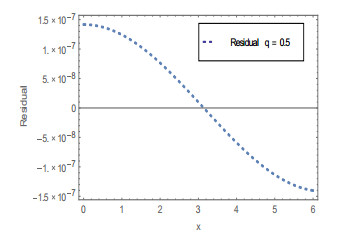
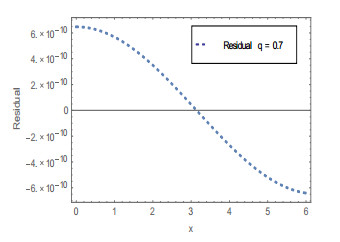
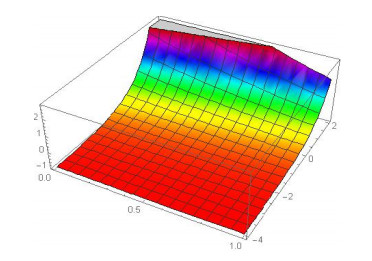
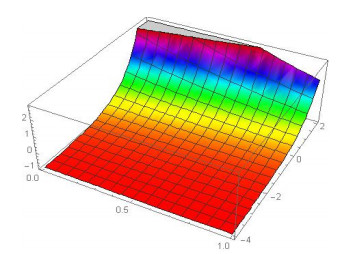
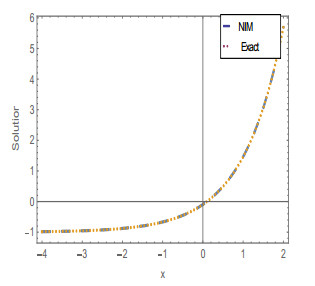
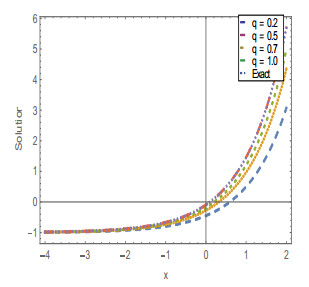
Figures(20) / Tables(4)

Laiq Zada, Rashid Nawaz, Sumbal Ahsan, Kottakkaran Sooppy Nisar, Dumitru Baleanu. New iterative approach for the solutions of fractional order inhomogeneous partial differential equations[J]. AIMS Mathematics, 2021, 6(2): 1348-1365. doi: 10.3934/math.2021084







 DownLoad:
DownLoad: