Citation: Alexander P. Moscalets, Leonid I. Nazarov, Mikhail V. Tamm. Towards a robust algorithm to determine topological domains from colocalization data[J]. AIMS Biophysics, 2015, 2(4): 503-516. doi: 10.3934/biophy.2015.4.503

| [1] | de Gennes PG (1979) Scaling Concepts in Polymer Physics, Cornell University Press. |
| [2] | Grosberg AY, Khokhlov AR (1994) Statistical Physics of Macromolecules, AIP Press. |
| [3] | Rubinstein M, Colby RH (2003) Polymer Physics, Oxford:OUP. |
| [4] | Grosberg AY, Nechaev SK, Shakhnovich EI (1988) The role of topological constraints in the kinetics of collapse of macromolecules. J Phys France 49(12):2095-2100. |
| [5] | Grosberg A, Rabin Y, Havlin S, et al. (1993) Crumpled globule model of the three-dimensional structure of DNA. EPL-Europhys Lett 23(5):373. |
| [6] | Rosa A, Everaers R (2008) Structure and dynamics of interphase chromosomes. PLoS Comput Biol 4(8):e1000153. |
| [7] | Lieberman-Aiden E, van Berkum NL, Williams L, et al. (2009) Comprehensive mapping of longrange interactions reveals folding principles of the human genome. Science 326(5950):289-293. |
| [8] | Mirny LA (2011) The fractal globule as a model of chromatin architecture in the cell. Chromosome Res 19(1):37-51. |
| [9] | Halverson JD, Smrek J, Kremer K, et al. (2014) From a melt of rings to chromosome territories: the role of topological constraints in genome folding. Rep Prog Phys 77(2):022601. |
| [10] |
Grosberg AY (2014) Annealed lattice animal model and Flory theory for the melt of nonconcatenated rings: towards the physics of crumpling. Soft Matter 10:560-565. doi: 10.1039/C3SM52805G

|
| [11] |
Rosa A, Everaers R (2014) Ring polymers in the melt state: The physics of crumpling. Phys Rev Lett 112:118302. doi: 10.1103/PhysRevLett.112.118302
|
| [12] | Nazarov LI, TammMV, Avetisov VA, et al. (2015) A statistical model of intra-chromosome contact maps. Soft Matter 11(5):1019-1025. |
| [13] |
Tamm MV, Nazarov LI, Gavrilov AA, et al. (2015) Anomalous diffusion in fractal globules. Phys Rev Lett 114:178102. doi: 10.1103/PhysRevLett.114.178102
|
| [14] |
Bunin G, Kardar M (2015) Coalescence model for crumpled globules formed in polymer collapse. Phys Rev Lett 115:088303. doi: 10.1103/PhysRevLett.115.088303
|
| [15] | Sachs RK, van den Engh G, Trask B, et al. (1995) A random-walk/giant-loop model for interphase chromosomes. P Natl Acad Sci 92(7):2710-2714. |
| [16] |
Münkel C, Langowski J (1998) Chromosome structure predicted by a polymer model. Phys Rev E 57:5888-5896. doi: 10.1103/PhysRevE.57.5888
|
| [17] | Ostashevsky J (1998) A polymer model for the structural organization of chromatin loops and minibands in interphase chromosomes. Mol Biol Cell 9(11):3031-3040. |
| [18] | Mateos-Langerak J, Bohn M, de Leeuw W, et al. (2009) Spatially confined folding of chromatin in the interphase nucleus. P Natl Acad Sci 106(10):3812-3817. |
| [19] | Iyer BVS, Arya G (2012) Lattice animal model of chromosome organization. Phys Rev E86:011911. |
| [20] | Barbieri M, Chotalia M, Fraser J, et al. (2012) Complexity of chromatin folding is captured by the strings and binders switch model. P Natl Acad Sci 109(40):16173-16178. |
| [21] | Fritsch CC, Langowski J (2010) Anomalous diffusion in the interphase cell nucleus: The effect of spatial correlations of chromatin. J Chem Phys 133(2):025101. |
| [22] | Fritsch CC, Langowski J (2011) Chromosome dynamics, molecular crowding, and diffusion in the interphase cell nucleus: a monte carlo lattice simulation study. Chromosome Res 19(1):63-81. |
| [23] | Dekker J, Rippe K, Dekker M, et al. (2002) Capturing chromosome conformation. Science 295(5558):1306-1311. |
| [24] | Naumova N, Imakaev M, Fudenberg G, et al. (2013) Organization of the mitotic chromosome. Science 342(6161):948-953. |
| [25] | Nagano T, Lubling Y, Stevens TJ, et al. (2013) Single-cell Hi-C reveals cell-to-cell variability in chromosome structure. Nature 502(7469):59-64. |
| [26] |
Newman MEJ (2004) Analysis of weighted networks. Phys Rev E 70:056131. doi: 10.1103/PhysRevE.70.056131
|
| [27] |
Lancichinetti A, Fortunato S (2011) Limits of modularity maximization in community detection. Phys Rev E 84:066122. doi: 10.1103/PhysRevE.84.066122
|
| [28] | Granell C, Gomez S, Arenas A (2012) Hierarchical multiresolution method to overcome the resolution limit in complex networks. Int J Bifurcat Chaos 22(07):1250171. |
| [29] | Arenas A, Fernandez A, Gomez S (2008) Analysis of the structure of complex networks at different resolution levels. New J Phys 10(5):053039. |
| [30] | Fortunato S (2010) Community detection in graphs. Phys Rep 486(3-5):75-174. |
| [31] | Newman MEJ (2006) Modularity and community structure in networks. P Natl Acad Sci 103(23):8577-8582. |
| [32] | Krzakala F, Moore C, Mossel E, et al. (2013) Spectral redemption in clustering sparse networks. P Natl Acad Sci 110(52):20935-20940. |
| [33] | Arenas A, Diaz-Guilera A, Kurths J, et al. (2008) Synchronization in complex networks. Phys Rep 469(3):93-153. |
| [34] | Sethna JP (2006) Statistical Mechanics: Entropy, Order Parameters and Complexity, Oxford:OUP. |
| [35] | Mezard M, Montanari A, (2009) Information, Physics, and Computation, Oxford:OUP. |
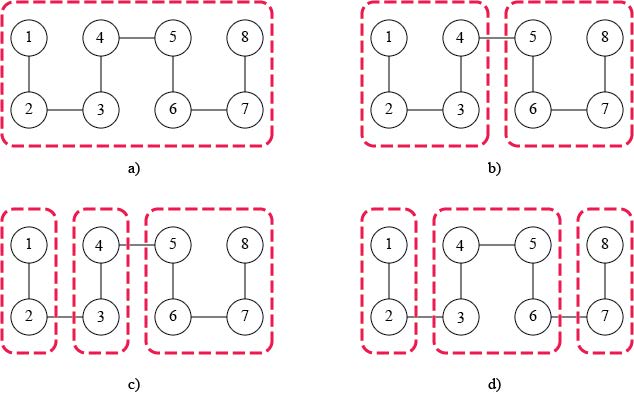
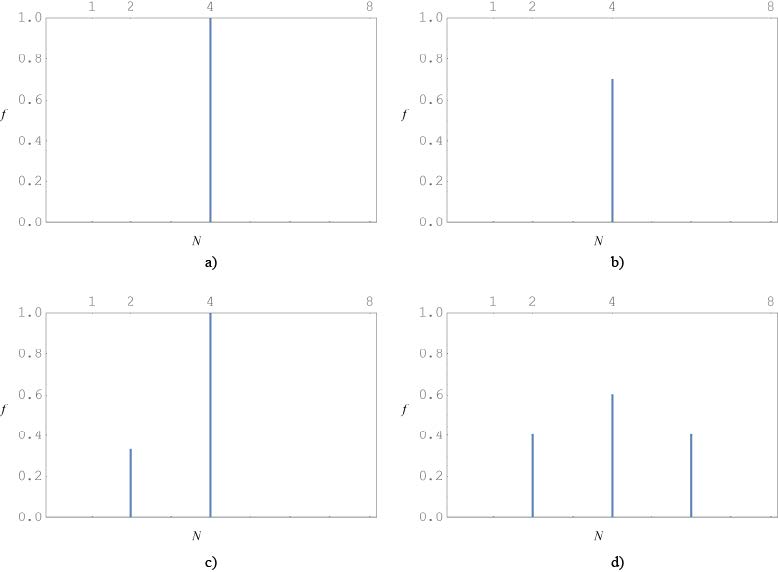
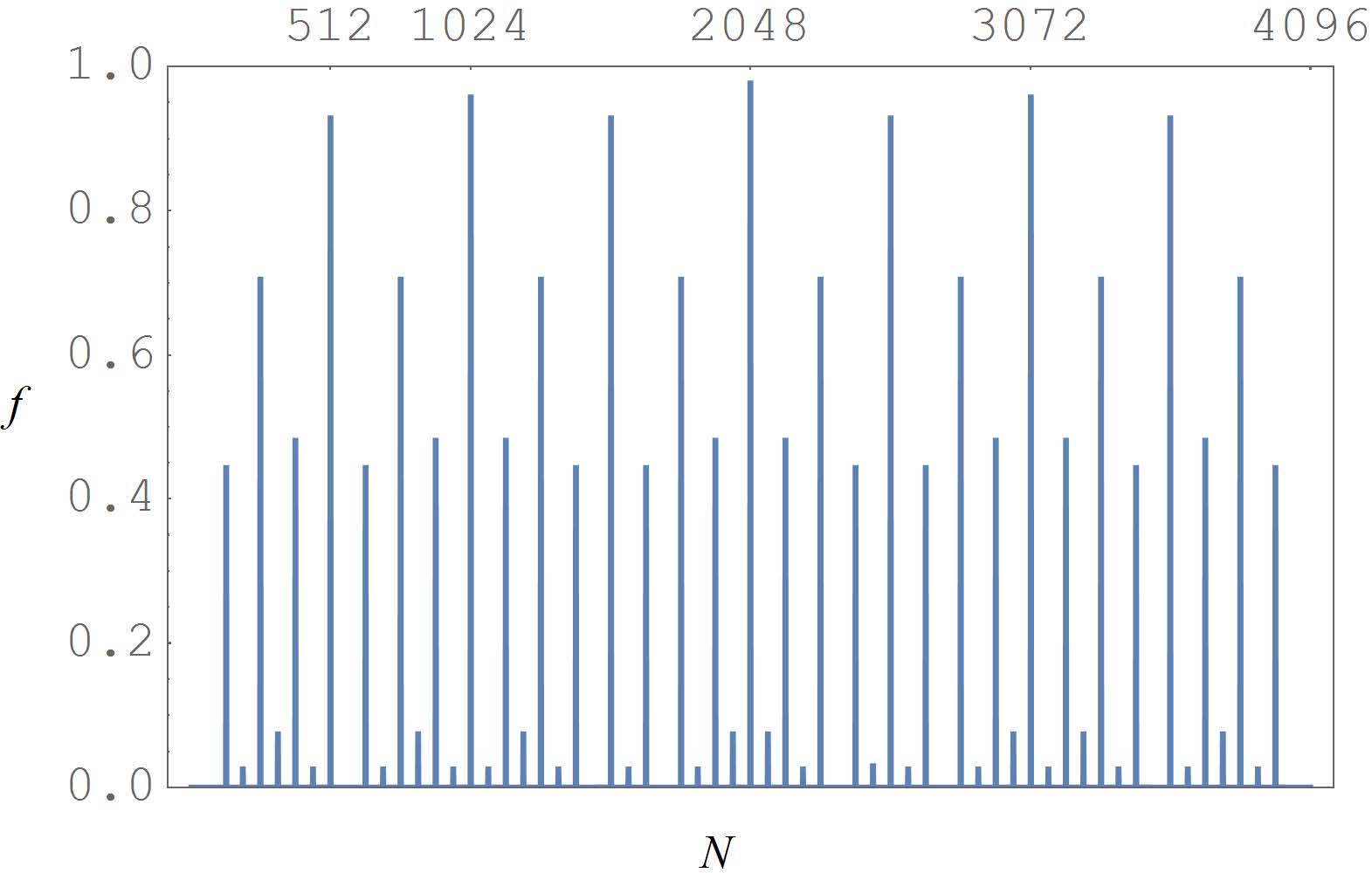
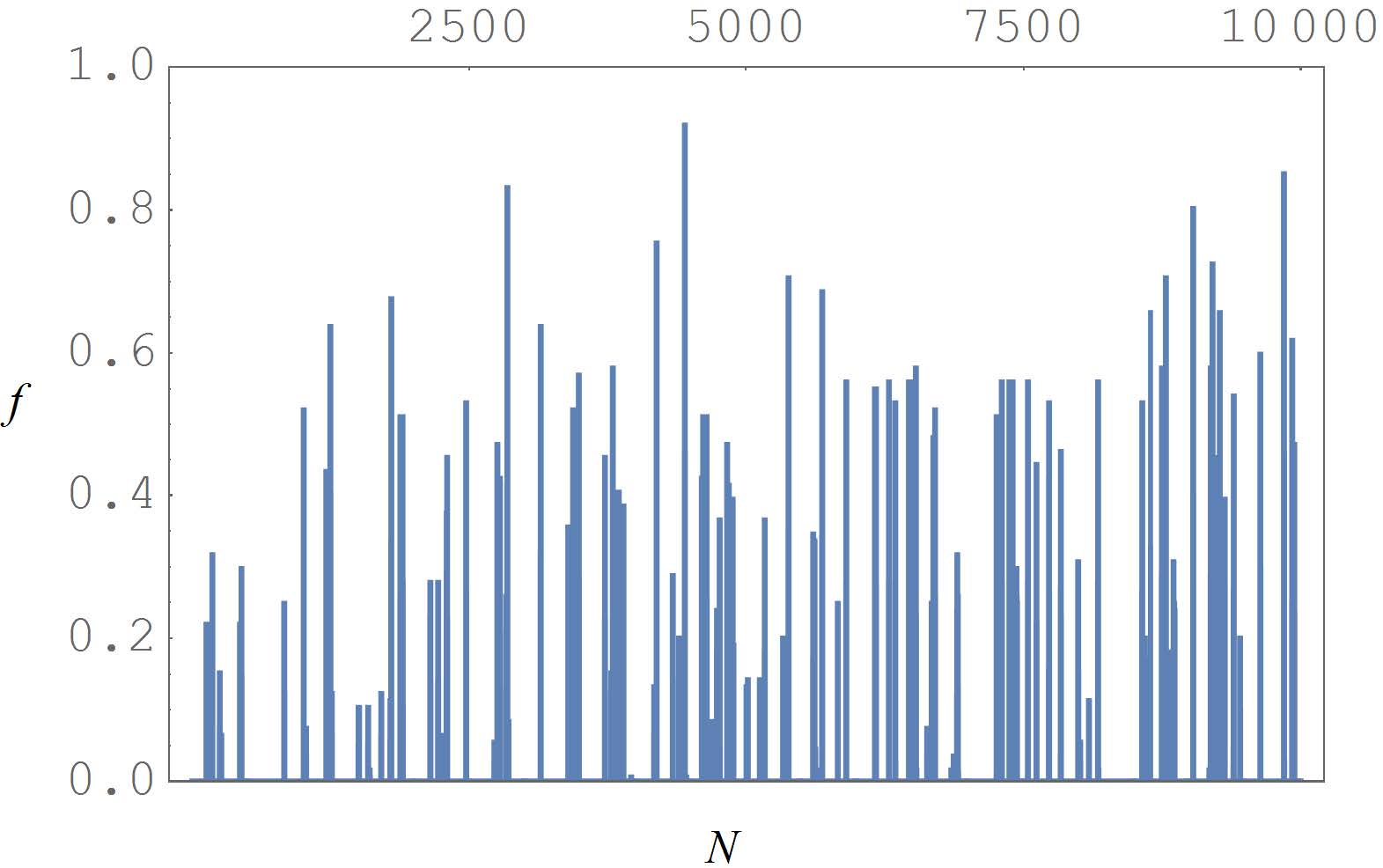
Figures(8)

Alexander P. Moscalets, Leonid I. Nazarov, Mikhail V. Tamm. Towards a robust algorithm to determine topological domains from colocalization data[J]. AIMS Biophysics, 2015, 2(4): 503-516. doi: 10.3934/biophy.2015.4.503







 DownLoad:
DownLoad: