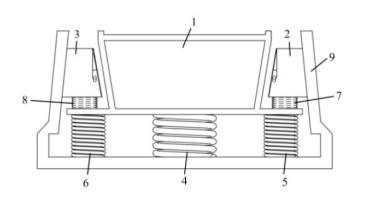
Aiming at the wedge friction damper for freight train bogie, considering Dankowicz dynamic friction, the mechanical model of a three-degree-of-freedom inclined impact vibration system with gap and dynamic friction, is simplified. The mechanical model of the system is established, the motion equation of the system is obtained, and the motion state and conditions of the system are analyzed. The Poincare map is constructed by selecting a fixed collision section, and the response of the system is solved by the fourth-order Runge-Kutta numerical method with variable step size. The transition process of the system motion and the phenomenon of sticking and chatter are analyzed by numerical simulation when the external excitation frequency changes. The results show that: 1) Under certain parameters, with the change of excitation frequency, the system undergoes periodic doubling bifurcation, inverse periodic doubling bifurcation, Grazing bifurcation and Hopf bifurcation, and there is a "periodic bubble" phenomenon in the system motion. When the system excitation frequency is between 3.35–3.55, 4.425–6.12, and 7.34–7.758, the system motion has chatter and sticking phenomena; when the system excitation frequency is between 1.75–3.24 and 3.92–4.425, the sticking phenomenon disappears, and only the chatter phenomenon exists. 2) When other parameters remain unchanged, and the mass ratio decreases from 1.15 to 0.85, nonlinear dynamic phenomena such as the transition between periodic bubbles and chaotic bubbles will be found. In this paper, the bifurcation and chaos characteristics of the impact vibration system of the wedge friction damper are studied, and the rich friction-induced vibration forms such as chatter and sticking are revealed, which provides a reference for improving the stability of vehicle operation and the selection of parameters in vehicle vibration reduction design in engineering practice.
Citation: Yanlong Zhang, Rui Zhang, Li Wang. Oblique impact dynamic analysis of wedge friction damper with Dankowicz dynamic friction[J]. Electronic Research Archive, 2024, 32(2): 962-978. doi: 10.3934/era.2024047
Aiming at the wedge friction damper for freight train bogie, considering Dankowicz dynamic friction, the mechanical model of a three-degree-of-freedom inclined impact vibration system with gap and dynamic friction, is simplified. The mechanical model of the system is established, the motion equation of the system is obtained, and the motion state and conditions of the system are analyzed. The Poincare map is constructed by selecting a fixed collision section, and the response of the system is solved by the fourth-order Runge-Kutta numerical method with variable step size. The transition process of the system motion and the phenomenon of sticking and chatter are analyzed by numerical simulation when the external excitation frequency changes. The results show that: 1) Under certain parameters, with the change of excitation frequency, the system undergoes periodic doubling bifurcation, inverse periodic doubling bifurcation, Grazing bifurcation and Hopf bifurcation, and there is a "periodic bubble" phenomenon in the system motion. When the system excitation frequency is between 3.35–3.55, 4.425–6.12, and 7.34–7.758, the system motion has chatter and sticking phenomena; when the system excitation frequency is between 1.75–3.24 and 3.92–4.425, the sticking phenomenon disappears, and only the chatter phenomenon exists. 2) When other parameters remain unchanged, and the mass ratio decreases from 1.15 to 0.85, nonlinear dynamic phenomena such as the transition between periodic bubbles and chaotic bubbles will be found. In this paper, the bifurcation and chaos characteristics of the impact vibration system of the wedge friction damper are studied, and the rich friction-induced vibration forms such as chatter and sticking are revealed, which provides a reference for improving the stability of vehicle operation and the selection of parameters in vehicle vibration reduction design in engineering practice.

| [1] |
J. Duan, Q. Ding, Dynamics and vibration reduction of oblique collision vibration of three masses (in Chinese), J. Vib. Eng., 26 (2013), 68–74. https://doi.org/10.16385/j.cnki.issn.1004-4523.2013.01.002 doi: 10.16385/j.cnki.issn.1004-4523.2013.01.002

|
| [2] |
L. Ling, M. Dhanasekar, D. P. Thambiratnam, Frontal collision of trains onto obliquely stuck road trucks at level crossings: derailment mechanisms and simulation, Int. J. Impact Eng., 100 (2017), 154–165. https://doi.org/10.1016/j.ijimpeng.2016.11.002 doi: 10.1016/j.ijimpeng.2016.11.002
|
| [3] |
M. J. Dong, Q. Ding, Study on vibration localization of oblique impact of whole-circle bladed disk with tips system (in Chinese), J. Aerosp. Power, 29 (2014), 2914–2923. https://doi.org/10.13224/j.cnki.jasp.2014.12.018 doi: 10.13224/j.cnki.jasp.2014.12.018
|
| [4] |
M. J. Wu, S. Y. Zhao, I. Azim, J. Zhu, X. H. Huang, A novel oblique impact model for elastic solids, Int. J. Impact Eng., 180 (2023), 104699. https://doi.org/10.1016/j.ijimpeng.2023.104699 doi: 10.1016/j.ijimpeng.2023.104699
|
| [5] |
M. Ji, Y. Sekiguchi, K Inaba, M. Naito, C. Sato, Forward and inverse analysis of transient responses for a cantilevered rectangular plate under normal and oblique impact loadings, Int. J. Impact Eng., 174 (2023), 104514. https://doi.org/10.1016/j.ijimpeng.2023.104514 doi: 10.1016/j.ijimpeng.2023.104514
|
| [6] |
J. P. Li, J. J. Fan, Discontinuous dynamics of a 3-DOF oblique-impact system with dry friction and single pendulum device, Nonlinear Dyn., 111 (2023), 4977–5021. https://doi.org/10.1007/s11071-022-08062-6 doi: 10.1007/s11071-022-08062-6
|
| [7] |
R. H. Davis, J. W. Sitison, Oblique collisions of two wetted spheres, Phys. Rev. Fluids, 5 (2020), 054305. https://doi.org/10.1103/PhysRevFluids.5.054305 doi: 10.1103/PhysRevFluids.5.054305
|
| [8] |
A. Kira, H. Hamashima, K. Hokamoto, M. Fujita, Numerical simulation of oblique collision of flier plate, Mater. Sci. Forum, 767 (2013), 192–195. https://doi.org/10.4028/www.scientific.net/MSF.767.192 doi: 10.4028/www.scientific.net/MSF.767.192
|
| [9] |
Z. S. Liu, M. Zhang, G. H. Zhang, Z. X. Liu, Characteristics of impact-contact and friction between tips of blades based on LuGre model (in Chinese), J. Vib. Shock, 31 (2012), 172–178. https://doi.org/10.13465/j.cnki.jvs.2012.12.036 doi: 10.13465/j.cnki.jvs.2012.12.036
|
| [10] |
A. Saha, M. Wiercigroch, K. Jankowski, P. Wahi, A. Stefanski, Investigation of two different friction models from the perspective of friction-induced vibrations, Tribol. Int., 90 (2015), 185–197. https://doi.org/10.1016/j.triboint.2015.04.029 doi: 10.1016/j.triboint.2015.04.029
|
| [11] |
Y. L. Zhang, B. B. Tang, L. Wang, S. S. Du, Dynamic analysis for a vibro-impact system with clearance under kinetic friction (in Chinese), J. Vib. Shock, 36 (2017), 58–63. https://doi.org/10.13465/j.cnki.jvs.2017.24.009 doi: 10.13465/j.cnki.jvs.2017.24.009
|
| [12] |
H. L. Li, F. Li, M. H. Fu, X. Yang, D. C. Zhang, Dynamic modeling and simulation of wedges friction damper (in Chinese), J. Railway Sci. Eng., 12 (2015), 1191–1199. https://doi.org/10.19713/j.cnki.43-1423/u.2015.05.031 doi: 10.19713/j.cnki.43-1423/u.2015.05.031
|
| [13] | Y. W. Li, Study on the Vibration Chatacteristics of 100t Load Heavy Haul Freight Car, MA thesis, Southwest Jiaotong University, 2018. |
| [14] |
Z. Y. Song, M. H. Fu, S. Chen, Effects of wedge friction angle on dynamic performance of three-angle bogie (in Chinese), Mach. Build. Autom., 50 (2021), 62–66. https://doi.org/10.19344/j.cnki.issn1671-5276.2021.02.017 doi: 10.19344/j.cnki.issn1671-5276.2021.02.017
|
| [15] | Z. M. Liu, Analysis and design suggestions on relative friction coefficient of freight car bogie, Railway Locomot. Car, 43 (2023), 122–127. |
| [16] |
J. F. Shi, X. F. Gou, Y. L. Zhang, Erosion and bifurcation of the safe basin of a two-degree-of-freedom damping boring bar system (in Chinese), J. Vib. Shock, 37 (2018), 238–244. https://doi.org/10.13465/j.cnki.jvs.2018.22.036 doi: 10.13465/j.cnki.jvs.2018.22.036
|
| [17] |
Y. L. Zhang, C. Wei, L. Wang, Z. L. Wang, Dynamic analysis of the impact vibration system with Dankowicz dynamic friction, Noise Vib. Control, 41 (2021), 14–20. https://doi.org/10.3969/j.issn.1006-1355.2021.03.003 doi: 10.3969/j.issn.1006-1355.2021.03.003
|







Figures(8)
Yanlong Zhang, Rui Zhang, Li Wang. Oblique impact dynamic analysis of wedge friction damper with Dankowicz dynamic friction[J]. Electronic Research Archive, 2024, 32(2): 962-978. doi: 10.3934/era.2024047







 DownLoad:
DownLoad: