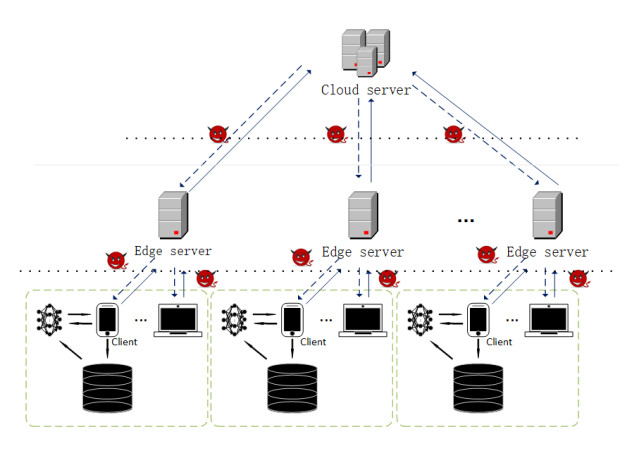
Federated learning (FL) is a framework which is used in distributed machine learning to obtain an optimal model from clients' local updates. As an efficient design in model convergence and data communication, cloud-edge-client hierarchical federated learning (HFL) attracts more attention than the typical cloud-client architecture. However, the HFL still poses threats to clients' sensitive data by analyzing the upload and download parameters. In this paper, to address information leakage effectively, we propose a novel privacy-preserving scheme based on the concept of differential privacy (DP), adding Gaussian noises to the shared parameters when uploading them to edge and cloud servers and broadcasting them to clients. Our algorithm can obtain global differential privacy with adjustable noises in the architecture. We evaluate the performance on image classification tasks. In our experiment on the Modified National Institute of Standards and Technology (MNIST) dataset, we get 91% model accuracy-layer HFL-DP, our design is more secure while as being accurate.
Citation: Youqun Long, Jianhui Zhang, Gaoli Wang, Jie Fu. Hierarchical federated learning with global differential privacy[J]. Electronic Research Archive, 2023, 31(7): 3741-3758. doi: 10.3934/era.2023190
Federated learning (FL) is a framework which is used in distributed machine learning to obtain an optimal model from clients' local updates. As an efficient design in model convergence and data communication, cloud-edge-client hierarchical federated learning (HFL) attracts more attention than the typical cloud-client architecture. However, the HFL still poses threats to clients' sensitive data by analyzing the upload and download parameters. In this paper, to address information leakage effectively, we propose a novel privacy-preserving scheme based on the concept of differential privacy (DP), adding Gaussian noises to the shared parameters when uploading them to edge and cloud servers and broadcasting them to clients. Our algorithm can obtain global differential privacy with adjustable noises in the architecture. We evaluate the performance on image classification tasks. In our experiment on the Modified National Institute of Standards and Technology (MNIST) dataset, we get 91% model accuracy-layer HFL-DP, our design is more secure while as being accurate.

| [1] |
C. Wang, X. Wu, G. Liu, T. Deng, K. Peng, S. Wan, Safeguarding cross-silo federated learning with local differential privacy, Digital Commun. Networks, 8 (2022), 446–454. https://doi.org/10.1016/j.dcan.2021.11.006 doi: 10.1016/j.dcan.2021.11.006

|
| [2] |
J. Shi, P. Cong, L. Zhao, X. Wang, S. Wan, M. Guizani, A two-stage strategy for UAV-enabled wireless power transfer in unknown environments, IEEE Trans. Mob. Comput., 2023 (2023), 1–15. https://doi.org/10.1109/TMC.2023.3240763 doi: 10.1109/TMC.2023.3240763
|
| [3] |
Q. Liu, Z. Zeng, Y. Jin, Distributed machine learning, optimization and applications, Neurocomputing, 489 (2022), 486–487. https://doi.org/10.1016/j.neucom.2021.12.058 doi: 10.1016/j.neucom.2021.12.058
|
| [4] |
M. A. P. Chamikara, P. Bertok, I. Khalil, D. Liu, S. Camtepe, Privacy preserving distributed machine learning with federated learning, Comput. Commun., 171 (2021), 112–125. https://doi.org/10.1016/j.comcom.2021.02.014 doi: 10.1016/j.comcom.2021.02.014
|
| [5] |
M. Sun, R. Yang, L. Hu, A secure distributed machine learning protocol against static semi-honest adversaries, Appl. Soft Comput., 102 (2021), 107095. https://doi.org/10.1016/j.asoc.2021.107095 doi: 10.1016/j.asoc.2021.107095
|
| [6] |
J. Liu, J. Huang, Y. Zhou, X. Li, S. Ji, H. Xiong, et al., From distributed machine learning to federated learning: a survey, Knowl. Inf. Syst., 64 (2022), 885–917. https://doi.org/10.1007/s10115-022-01664-x doi: 10.1007/s10115-022-01664-x
|
| [7] |
C. Zhang, Y. Xie, H. Bai, B. Yu, W. Li, Y. Gao, A survey on federated learning, Knowledge-Based Syst., 216 (2021), 106775. https://doi.org/10.1016/j.knosys.2021.106775 doi: 10.1016/j.knosys.2021.106775
|
| [8] |
X. Wang, Y. Han, C. Wang, Q. Zhao, X. Chen, M. Chen, In-Edge AI: intelligentizing mobile edge computing, caching and communication by federated learning, IEEE Network, 33 (2019), 156–165. https://doi.org/10.1109/MNET.2019.1800286 doi: 10.1109/MNET.2019.1800286
|
| [9] | T. Li, A. K. Sahu, A. Talwalkar, V. Smith, Federated learning: challenges, methods, and future directions, preprint, arXiv: 1908.07873. |
| [10] |
H. Yang, Z. Liu, T. Q. S. Quek, H. V. Poor, Scheduling policies for federated learning in wireless networks, IEEE Trans. Commun., 68 (2019), 317–333. https://doi.org/10.1109/TCOMM.2019.2944169 doi: 10.1109/TCOMM.2019.2944169
|
| [11] | M. Hao, H. Li, G. Xu, S. Liu, H. Yang, Towards efficient and privacy-preserving federated deep learning, in ICC 2019 - 2019 IEEE International Conference on Communications (ICC), Paris, France, 2019. https://doi.org/10.1109/ICC.2019.8761267 |
| [12] |
J. Kang, Z. Xiong, D. Niyato, Y. Zou, Y. Zhang, M. Guizani, Reliable federated learning for mobile networks, IEEE Wireless Commun., 27 (2020), 72–80. https://doi.org/10.1109/MWC.001.1900119 doi: 10.1109/MWC.001.1900119
|
| [13] |
S. Liu, J. Yu, X. Deng, S. Wan, FedCPF: an efficient-communication federated learning approach for vehicular edge computing in 6G communication networks, IEEE Trans. Intell. Transp. Syst., 23 (2022), 1616–1629. https://doi.org/10.1109/TITS.2021.3099368 doi: 10.1109/TITS.2021.3099368
|
| [14] | L. Liu, J. Zhang, S. H. Song, K. B. Letaief, Client-Edge-Cloud hierarchical federated learning, in ICC 2020 - 2020 IEEE International Conference on Communications (ICC), (2020), 1–6. https://doi.org/10.1109/ICC40277.2020.9148862 |
| [15] |
S. Wang, T. Tuor, T. Salonidis, K. K. Leung, C. Makaya, T. He, et al., Adaptive federated learning in resource constrained edge computing systems, IEEE J. Sel. Areas Commun., 37 (2019), 1205–1221. https://doi.org/10.1109/JSAC.2019.2904348 doi: 10.1109/JSAC.2019.2904348
|
| [16] | A. Agarwal, J. C. Duchi, Distributed delayed stochastic optimization, in 2012 IEEE 51st IEEE Conference on Decision and Control (CDC), 2012. https://doi.org/10.1109/CDC.2012.6426626 |
| [17] | X. Lian, Y. Huang, Y. Li, J. Liu, Asynchronous parallel stochastic gradient for nonconvex optimization, ACM NIPS, (2015), 2737–2745. Available from: https://proceedings.neurips.cc/paper/2015/hash/452bf208bf901322968557227b8f6efe-Abstract.html. |
| [18] | T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, V. Smith, Federated optimization in heterogeneous networks, preprint, arXiv: 1812.06127. |
| [19] | A. Wainakh, A. S. Guinea, T. Grube, M. Mühlhäuser, Enhancing privacy via hierarchical federated learning, in 2020 IEEE European Symposium on Security and Privacy Workshops (EuroS & PW), (2020), 344–347. https://doi.org/10.1109/EuroSPW51379.2020.00053 |
| [20] | M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, et al., Deep learning with differential privacy, in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, (2016), 308–318. https://doi.org/10.1145/2976749.2978318 |
| [21] | H. B. McMahan, D. Ramage, K. Talwar, L. Zhang, Learning differentially private recurrent language models, in ICLR 2018, (2018), 1–14. Available from: https://openreview.net/forum?id = BJ0hF1Z0b. |
| [22] | R. C. Geyer, T. Klein, M. Nabi, Differentially private federated learning: a client level perspective, preprint, arXiv: 1712.07557. |
| [23] |
K. Wei, J. Li, M. Ding, C. Ma, H. H. Yang, F. Farokhi, et al., Federated learning with differential privacy: algorithms and performance analysis, IEEE Trans. Inf. Forensics Secur., 15 (2020), 3454–3469. https://doi.org/10.1109/TIFS.2020.2988575 doi: 10.1109/TIFS.2020.2988575
|
| [24] |
X. Huang, Y. Ding, Z. L. Jiang, S. Qi, X. Wang, Q. Liao, DP-FL: a novel differentially private federated learning framework for the unbalanced data, World Wide Web, 23 (2020), 2529–2545. https://doi.org/10.1007/s11280-020-00780-4 doi: 10.1007/s11280-020-00780-4
|
| [25] |
K. Wei, J. Li, M. Ding, C. Ma, H. Su, B. Zhang, et al., User-level privacy-preserving federated learning: analysis and performance optimization, IEEE Trans. Mob. Comput., 21 (2022), 3388–3401. https://doi.org/10.1109/TMC.2021.3056991 doi: 10.1109/TMC.2021.3056991
|
| [26] | A. Girgis, D. Data, S. Diggavi, P. Kairouz, A. T. Suresh, Shuffled model of differential privacy in federated learning, in Proceedings of the 24th International Conference on Artificial Intelligence and Statistics, 130 (2021), 2521–2529. Available from: http://proceedings.mlr.press/v130/girgis21a.html. |
| [27] | L. Shi, J. Shu, W. Zhang, Y. Liu, HFL-DP: hierarchical federated learning with differential privacy, in 2021 IEEE Global Communications Conference (GLOBECOM), (2021), 7–11. https://doi.org/10.1109/GLOBECOM46510.2021.9685644 |
| [28] | T. Zhou, Hierarchical federated learning with gaussian differential privacy, in AISS '22: Proceedings of the 4th International Conference on Advanced Information Science and System, (2022), 61. https://doi.org/10.1145/3573834.3574544 |
| [29] | M. Fredrikson, S. Jha, T. Ristenpart, Model inversion attacks that exploit confidence information and basic countermeasures, in CCS '15: Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, (2015), 1322–1333. https://doi.org/10.1145/2810103.2813677 |
| [30] |
H. Zhu, F. Yin, S. Peng, X. Tang, Differentially private hierarchical tree with high efficiency, Comput. Secur., 118 (2022), 102727. https://doi.org/10.1016/j.cose.2022.102727 doi: 10.1016/j.cose.2022.102727
|





Figures(6) / Tables(3)
Youqun Long, Jianhui Zhang, Gaoli Wang, Jie Fu. Hierarchical federated learning with global differential privacy[J]. Electronic Research Archive, 2023, 31(7): 3741-3758. doi: 10.3934/era.2023190







 DownLoad:
DownLoad: