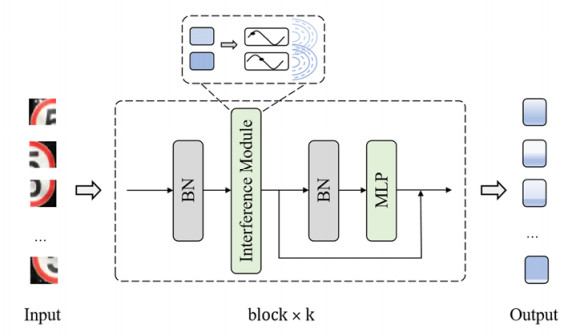
In this paper, we successfully combine convolution with a wave function to build an effective and efficient classifier for traffic signs, named the wave interference network (WiNet). In the WiNet, the feature map extracted by the convolutional filters is refined into many entities from an input image. Each entity is represented as a wave. We utilize Euler's formula to unfold the wave function. Based on the wave-like information representation, the model modulates the relationship between the entities and the fixed weights of convolution adaptively. Experiment results on the Chinese Traffic Sign Recognition Database (CTSRD) and the German Traffic Sign Recognition Benchmark (GTSRB) demonstrate that the performance of the presented model is better than some other models, such as ResMLP, ResNet50, PVT and ViT in the following aspects: 1) WiNet obtains the best accuracy rate with 99.80% on the CTSRD and recognizes all images exactly on the GTSRB; 2) WiNet gains better robustness on the dataset with different noises compared with other models; 3) WiNet has a good generalization on different datasets.
Citation: Qiang Weng, Dewang Chen, Yuandong Chen, Wendi Zhao, Lin Jiao. Wave interference network with a wave function for traffic sign recognition[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 19254-19269. doi: 10.3934/mbe.2023851
In this paper, we successfully combine convolution with a wave function to build an effective and efficient classifier for traffic signs, named the wave interference network (WiNet). In the WiNet, the feature map extracted by the convolutional filters is refined into many entities from an input image. Each entity is represented as a wave. We utilize Euler's formula to unfold the wave function. Based on the wave-like information representation, the model modulates the relationship between the entities and the fixed weights of convolution adaptively. Experiment results on the Chinese Traffic Sign Recognition Database (CTSRD) and the German Traffic Sign Recognition Benchmark (GTSRB) demonstrate that the performance of the presented model is better than some other models, such as ResMLP, ResNet50, PVT and ViT in the following aspects: 1) WiNet obtains the best accuracy rate with 99.80% on the CTSRD and recognizes all images exactly on the GTSRB; 2) WiNet gains better robustness on the dataset with different noises compared with other models; 3) WiNet has a good generalization on different datasets.

| [1] |
A. Gudigar, S. Chokkadi, U. Raghavendra, U. Rajendra Acharya, An efficient traffic sign recognition based on graph embedding features, Neural Comput. Appl., 31 (2019), 395–407. https://doi.org/10.1007/s00521-017-3063-z doi: 10.1007/s00521-017-3063-z

|
| [2] |
Z. Liang, J. Shao, D. Zhang, L. Gao, Traffic sign detection and recognition based on pyramidal convolutional networks, Neural Comput. Appl., 32 (2020), 6533–6543. https://doi.org/10.1007/s00521-019-04086-z doi: 10.1007/s00521-019-04086-z
|
| [3] |
R. Abdel-Salam, R. Mostafa, A. H. Abdel-Gawad, RIECNN: real-time image enhanced CNN for traffic sign recognition, Neural Comput. Appl., 34 (2022), 6085–6096. https://doi.org/10.1007/s00521-021-06762-5 doi: 10.1007/s00521-021-06762-5
|
| [4] |
M. Lu, K. Wevers, R. V. D. Heijden, Technical feasibility of advanced driver assistance systems (ADAS) for road traffic safety, Transp. Plann. Technol., 28 (2005), 167–187. https://doi.org/10.1080/03081060500120282 doi: 10.1080/03081060500120282
|
| [5] | J. C. McCall, M. M. Trivedi, Video-based lane estimation and tracking for driver assistance: survey, system, and evaluation, IEEE Trans. Intell. Transp. Syst., 7 (2006), 20–37. https://doi.org/10.1109/TITS.2006.869595 |
| [6] | M. Haloi, D. B. Jayagopi, A robust lane detection and departure warning system, in 2015 IEEE Intelligent Vehicles Symposium (IV), (2015), 126–131. https://doi.org/10.1109/IVS.2015.7225674 |
| [7] |
R. Ayachi, Y. Said, A. B. Abdelaali, Pedestrian detection based on light-weighted separable convolution for advanced driver assistance systems, Neural Process. Lett., 52 (2020), 2655–2668. https://doi.org/10.1007/s11063-020-10367-9 doi: 10.1007/s11063-020-10367-9
|
| [8] |
Y. Gu, B. Si, A novel lightweight real-time traffic sign detection integration framework based on YOLOv4, Entropy, 24 (2022), 487. https://doi.org/10.3390/e24040487 doi: 10.3390/e24040487
|
| [9] | T. Liang, H. Bao, W. Pan, F. Pan, Traffic sign detection via improved sparse R-CNN for autonomous vehicles, J. Adv. Transp., (2022), 1–16. https://doi.org/10.1155/2022/3825532 |
| [10] |
J. Wang, Y. Chen, Z. Dong, M. Gao, Improved YOLOv5 network for real-time multi-scale traffic sign detection, Neural Comput. Appl., 35 (2023), 7853–7865. https://doi.org/10.1007/s00521-022-08077-5 doi: 10.1007/s00521-022-08077-5
|
| [11] | M Swathi, K. V. Suresh, Automatic traffic sign detection and recognition: A review, in 2017 International Conference on Algorithms, Methodology, Models and Applications in Emerging Technologies (ICAMMAET), (2017), 1–6. https://doi.org/10.1109/ICAMMAET.2017.8186650 |
| [12] | C. Liu, S. Li, F. Chang, Y. Wang, Machine vision based traffic sign detection methods: Review, analyses and perspectives, IEEE Access, 7 (2019), 86578–86596. https://doi.org/10.1109/ACCESS.2019.2924947 |
| [13] |
S. Maldonado-Bascon, S. Lafuente-Arroyo, P. Gil-Jimenez, H. Gomez-Moreno, F. Lopez-Ferreras, Road-sign detection and recognition based on support vector machines, IEEE Trans. Intell. Transp. Syst., 8 (2007), 264–278. https://doi.org/10.1109/TITS.2007.895311 doi: 10.1109/TITS.2007.895311
|
| [14] |
V. Cherkassky, Y. Ma, Practical selection of SVM parameters and noise estimation for SVM regression, Neural Networks, 17 (2004), 113–126. https://doi.org/10.1016/S0893-6080(03)00169-2 doi: 10.1016/S0893-6080(03)00169-2
|
| [15] |
A. Ellahyani, M. E. Ansari, I. E. Jaafari, S. Charfi, Traffic sign detection and recognition using features combination and random forests, Int. J. Adv. Comput. Sci. Appl., 7 (2016), 686–693. https://doi.org/10.14569/IJACSA.2016.070193 doi: 10.14569/IJACSA.2016.070193
|
| [16] |
K. Lu, Z. Ding, S. Ge, Sparse-representation-based graph embedding for traffic sign recognition, IEEE Trans. Intell. Transp. Syst., 13 (2021), 1515–1524. https://doi.org/10.1109/TITS.2012.2220965 doi: 10.1109/TITS.2012.2220965
|
| [17] | Y. Tang, K. Han, J. Guo, C. Xu, Y. Li, C. Xu, et al., An image patch is a wave: Phase-aware vision MLP, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2022), 10935–10944. https://doi.org/10.48550/arXiv.2111.12294 |
| [18] |
E. J. Heller, M. F. Crommie, C. P. Lutz, D. M. Eigler, Scattering and absorption of surface electron waves in quantum corrals, Nature, 369 (1994), 464–466. https://doi.org/10.1038/369464a0 doi: 10.1038/369464a0
|
| [19] |
H. Touvron, P. Bojanowski, M. Caron, M. Cord, A. El-Nouby, E. Grave, et al., ResMLP: Feedforward networks for image classification with data-efficient training, IEEE Trans. Pattern Anal. Mach. Intell., 45 (2023), 5314–5321. https://doi.org/10.1109/TPAMI.2022.3206148 doi: 10.1109/TPAMI.2022.3206148
|
| [20] | W. Wang, E. Xie, X. Li, D. Fan, K. Song, D. Liang, et al., Pyramid vision transformer: A versatile backbone for dense prediction without convolutions, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 568–578. https://doi.org/10.48550/arXiv.2102.12122 |
| [21] | A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, An image is worth 16x16 Words: Transformers for image recognition at scale, preprint, arXiv: 2010.11929. |
| [22] | O. N. Manzari, A. Boudesh, S. B. Shokouhi, Pyramid transformer for traffic sign detection, in 2022 12th International Conference on Computer and Knowledge Engineering (ICCKE), (2022), 112–116. https://doi.org/10.1109/ICCKE57176.2022.9960090 |
| [23] |
Y. Zheng, W. Jiang, Evaluation of vision transformers for traffic sign classification, Wireless Commun. Mobile Comput., 2022 (2022), 14. https://doi.org/10.1155/2022/3041117 doi: 10.1155/2022/3041117
|
| [24] |
D. Pei, F. Sun, H. Liu, Supervised low-rank matrix recovery for traffic sign recognition in image sequences, IEEE Signal Process. Lett., 20 (2013), 241–244. https://doi.org/10.1109/LSP.2013.2241760 doi: 10.1109/LSP.2013.2241760
|
| [25] | S. Ardianto, C. Chen, H. Hang, Real-time traffic sign recognition using color segmentation and SVM, in 2017 International Conference on Systems, Signals and Image Processing (IWSSIP), (2017), 1–5. https://doi.org/10.1109/IWSSIP.2017.7965570 |
| [26] | D. Cireşan, U. Meier, J. Masci, J. Schmidhuber, A committee of neural networks for traffic sign classification, in the 2011 International Joint Conference on Neural Networks, (2011), 1918–1921. https://doi.org/10.1109/IJCNN.2011.6033458. |
| [27] | P. Sermanet, Y. LeCun, Traffic sign recognition with multi-scale convolutional networks, in the 2011 International Joint Conference on Neural Networks, (2011), 2809–2813. https://doi.org/10.1109/IJCNN.2011.6033589 |
| [28] | M. Haloi, Traffic sign classification using deep inception based convolutional networks, preprint, arXiv: 1511.02992. |
| [29] | M. Jaderberg, K. Simonyan, A. Zisserman, K. kavukcuoglu, Spatial transformer networks, in Advances in Neural Information Processing Systems 28 (NIPS 2015), 28 (2015). |
| [30] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, et al., Going deeper with convolutions, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 1–9. https://doi.org/10.1109/CVPR.2015.7298594 |
| [31] | J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 7132–7141. https://doi.org/10.48550/arXiv.1709.01507 |
| [32] |
Y. Yuan, Z. Xiong, Q. Wang, VSSA-NET: Vertical spatial sequence attention network for traffic sign detection, IEEE Trans. Image Process., 28 (2019), 3423–3434. https://doi.org/10.1109/TIP.2019.2896952 doi: 10.1109/TIP.2019.2896952
|
| [33] | Y. Liu, Z. Shao, N. Hoffmann, Global attention mechanism: Retain information to enhance channel-spatial interactions, preprint, arXiv: 2112.05561. |
| [34] |
S. Liu, J. Li, C. Hu, W. Wang, Traffic sign recognition based on convolutional neural network and ensemble learning, Comput. Mod., 12 (2019), 67. https://doi.org/10.3969/j.issn.1006-2475.2019.12.013 doi: 10.3969/j.issn.1006-2475.2019.12.013
|
| [35] |
K. Zhou, Y. Zhan, D. Fu, Learning region-based attention network for traffic sign recognition, Sensors, 21 (2021), 686. https://doi.org/10.3390/s21030686 doi: 10.3390/s21030686
|
| [36] |
M. Guo, C. Lu, Z. Liu, M. Cheng, S. Hu, Visual attention network, Visual Media, 9 (2023), 733–752. https://doi.org/10.1007/s41095-023-0364-2 doi: 10.1007/s41095-023-0364-2
|
| [37] |
S. Gao, M. Cheng, K. Zhao, X. Zhang, M. Yang, P. Torr, Res2Net: A new multi-scale backbone architecture, IEEE Trans. Pattern Anal. Mach. Intell., 43 (2019), 652–662. https://doi.org/10.1109/TPAMI.2019.2938758 doi: 10.1109/TPAMI.2019.2938758
|
| [38] | K. He, X. Zhang, S. Ren, J. Sun, Deep Residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [39] | L. Chen, H. Zhang, J. Xiao, L. Nie, J. Shao, W. Liu, SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 5659–5667. |
| [40] |
Z. Zhu, J. Lu, R. R. Martin, S. Hu, An optimization approach for localization refinement of candidate traffic signs, IEEE Trans. Intell. Transp. Syst., 18 (2017), 3006–016. https://doi.org/10.1109/TITS.2017.2665647 doi: 10.1109/TITS.2017.2665647
|
| [41] | S. Mehta, C. Paunwala, B. Vaidya, CNN based traffic sign classification using Adam optimizer, in 2019 International Conference on Intelligent Computing and Control Systems (ICCS), (2019), 1293–1298. https://doi.org/10.1109/ICCS45141.2019.9065537 |
| [42] |
A. Staravoitau, Traffic sign classification with a convolutional network, Pattern Recognit. Image Anal., 28 (2018), 155–162. https://doi.org/10.1134/S1054661818010182 doi: 10.1134/S1054661818010182
|
| [43] |
J. Greenhalgh, M. Mirmehdi, Real-time detection and recognition of road traffic signs, IEEE Trans. Intell. Transp. Syst., 13 (2012), 1498–1506. https://doi.org/10.1109/TITS.2012.2208909 doi: 10.1109/TITS.2012.2208909
|
| [44] | G. Overett, L. Petersson, Large scale sign detection using HOG feature variants, in 2011 IEEE Intelligent Vehicles Symposium (IV), (2011), 326–331. https://doi.org/10.1109/IVS.2011.5940549 |
| [45] |
A. Mogelmose, M. M. Trivedi, T. B. Moeslund, Vision-based traffic sign detection and analysis for intelligent driver assistance systems: Perspectives and survey, IEEE Trans. Intell. Transp. Syst., 13 (2012), 1484–1497. https://doi.org/10.1109/TITS.2012.2209421 doi: 10.1109/TITS.2012.2209421
|
| [46] | F. Larsson, M. Felsberg, Using fourier descriptors and spatial models for traffic sign recognition, in SCIA 2011: Image Analysis, 6688 (2011), 238–249. https://doi.org/10.1007/978-3-642-21227-7_23 |
| [47] |
J. Stallkamp, M. Schlipsing, J. Salmen, C. Igel, Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition, Neural Networks, 32 (2012), 323–332. https://doi.org/10.1016/j.neunet.2012.02.016 doi: 10.1016/j.neunet.2012.02.016
|
| [48] | X. Mao, S. Hijazi, R. Casas, P. Kaul, R. Kumar, C. Rowen, Hierarchical CNN for traffic sign recognition, in 2016 IEEE Intelligent Vehicles Symposium (IV), (2016), 130–135. https://doi.org/10.1109/IVS.2016.7535376 |
| [49] | X. Peng, Y. Li, X. Wei, J. Luo, Y. Murphey, Traffic sign recognition with transfer learning, in 2017 IEEE Symposium Series on Computational Intelligence (SSCI), (2017), 1–7. https://doi.org/10.1109/SSCI.2017.8285332 |
| [50] |
Y. Jin, Y. Fu, W. Wang, J. Guo. C. Ren, X. Xiang, Multi-feature fusion and enhancement single shot detector for traffic sign recognition, IEEE Access, 8 (2020), 38931–38940. https://doi.org/10.1109/ACCESS.2020.2975828 doi: 10.1109/ACCESS.2020.2975828
|
| [51] |
A. Bouti, M. A. Mahraz, J. Riffi, H. Tairi, A robust system for road sign detection and classification using LeNet architecture based on convolutional neural network, Soft Comput., 24 (2020), 6721–6733. https://doi.org/10.1007/s00500-019-04307-6 doi: 10.1007/s00500-019-04307-6
|
| [52] | F. J. Moreno-Barea, F. Strazzera, J. M. Jerez, D. Urda, L. Franco, Forward noise adjustment scheme for data augmentation, in 2018 IEEE Symposium Series on Computational Intelligence (SSCI), (2018), 728–734. https://doi.org/10.1109/SSCI.2018.8628917 |
| [53] | A. Asuncion, D. Newman, UCI Machine Learning Repository, 2007. Available from: http://archive.ics.uci.edu/ml. |






Figures(7) / Tables(6)

Qiang Weng, Dewang Chen, Yuandong Chen, Wendi Zhao, Lin Jiao. Wave interference network with a wave function for traffic sign recognition[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 19254-19269. doi: 10.3934/mbe.2023851







 DownLoad:
DownLoad: