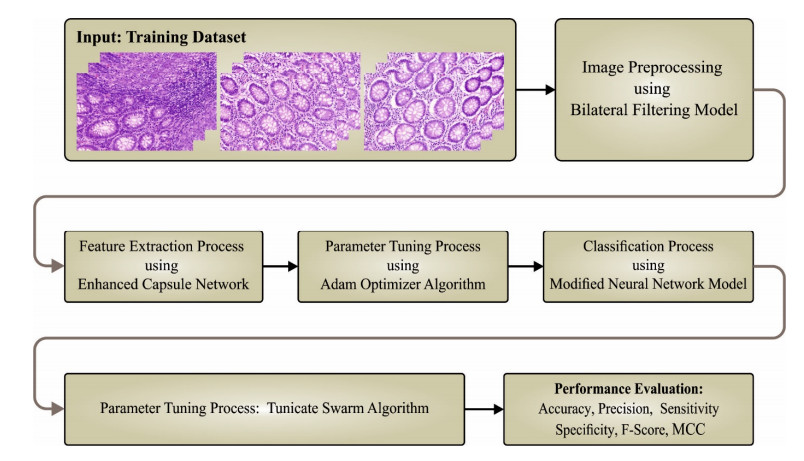
Colorectal cancer (CRC) is one of the most popular cancers among both men and women, with increasing incidence. The enhanced analytical load data from the pathology laboratory, integrated with described intra- and inter-variabilities through the calculation of biomarkers, has prompted the quest for robust machine-based approaches in combination with routine practice. In histopathology, deep learning (DL) techniques have been applied at large due to their potential for supporting the analysis and forecasting of medically appropriate molecular phenotypes and microsatellite instability. Considering this background, the current research work presents a metaheuristics technique with deep convolutional neural network-based colorectal cancer classification based on histopathological imaging data (MDCNN-C3HI). The presented MDCNN-C3HI technique majorly examines the histopathological images for the classification of colorectal cancer (CRC). At the initial stage, the MDCNN-C3HI technique applies a bilateral filtering approach to get rid of the noise. Then, the proposed MDCNN-C3HI technique uses an enhanced capsule network with the Adam optimizer for the extraction of feature vectors. For CRC classification, the MDCNN-C3HI technique uses a DL modified neural network classifier, whereas the tunicate swarm algorithm is used to fine-tune its hyperparameters. To demonstrate the enhanced performance of the proposed MDCNN-C3HI technique on CRC classification, a wide range of experiments was conducted. The outcomes from the extensive experimentation procedure confirmed the superior performance of the proposed MDCNN-C3HI technique over other existing techniques, achieving a maximum accuracy of 99.45%, a sensitivity of 99.45% and a specificity of 99.45%.
Citation: Abdullah S. AL-Malaise AL-Ghamdi, Mahmoud Ragab. Tunicate swarm algorithm with deep convolutional neural network-driven colorectal cancer classification from histopathological imaging data[J]. Electronic Research Archive, 2023, 31(5): 2793-2812. doi: 10.3934/era.2023141
Colorectal cancer (CRC) is one of the most popular cancers among both men and women, with increasing incidence. The enhanced analytical load data from the pathology laboratory, integrated with described intra- and inter-variabilities through the calculation of biomarkers, has prompted the quest for robust machine-based approaches in combination with routine practice. In histopathology, deep learning (DL) techniques have been applied at large due to their potential for supporting the analysis and forecasting of medically appropriate molecular phenotypes and microsatellite instability. Considering this background, the current research work presents a metaheuristics technique with deep convolutional neural network-based colorectal cancer classification based on histopathological imaging data (MDCNN-C3HI). The presented MDCNN-C3HI technique majorly examines the histopathological images for the classification of colorectal cancer (CRC). At the initial stage, the MDCNN-C3HI technique applies a bilateral filtering approach to get rid of the noise. Then, the proposed MDCNN-C3HI technique uses an enhanced capsule network with the Adam optimizer for the extraction of feature vectors. For CRC classification, the MDCNN-C3HI technique uses a DL modified neural network classifier, whereas the tunicate swarm algorithm is used to fine-tune its hyperparameters. To demonstrate the enhanced performance of the proposed MDCNN-C3HI technique on CRC classification, a wide range of experiments was conducted. The outcomes from the extensive experimentation procedure confirmed the superior performance of the proposed MDCNN-C3HI technique over other existing techniques, achieving a maximum accuracy of 99.45%, a sensitivity of 99.45% and a specificity of 99.45%.

| [1] |
A. Mitsala, C. Tsalikidis, M. Pitiakoudis, C. Simopoulos, A. K. Tsaroucha, Artificial intelligence in colorectal cancer screening, diagnosis and treatment. A new era, Curr. Oncol., 28 (2021), 1581–1607. https://doi.org/10.3390/curroncol28030149 doi: 10.3390/curroncol28030149

|
| [2] |
C. Ho, Z. Zhao, X. F. Chen, J. Sauer, S. A. Saraf, R. Jialdasani, et al., A promising deep learning-assistive algorithm for histopathological screening of colorectal cancer, Sci. Rep., 12 (2022), 1–9. https://doi.org/10.1038/s41598-022-06264-x doi: 10.1038/s41598-022-06264-x
|
| [3] |
D. Sarwinda, R. H. Paradisa, A. Bustamam, P. Anggia, Deep learning in image classification using residual network (ResNet) variants for detection of colorectal cancer, Procedia Comput. Sci., 179 (2021), 423–431. https://doi.org/10.1016/j.procs.2021.01.025 doi: 10.1016/j.procs.2021.01.025
|
| [4] |
S. Javed, A. Mahmood, M. M. Fraz, N. A. Koohbanani, K. Benes, Y. W. Tsang, et al., Cellular community detection for tissue phenotyping in colorectal cancer histology images, Med. Image Anal., 63 (2020), 101696. https://doi.org/10.1016/j.media.2020.101696 doi: 10.1016/j.media.2020.101696
|
| [5] |
M. Masud, N. Sikder, A. A. Nahid, A. K. Bairagi, M. A. AlZain, A machine learning approach to diagnosing lung and colon cancer using a deep learning-based classification framework, Sensors, 21 (2021), 748. https://doi.org/10.3390/s21030748 doi: 10.3390/s21030748
|
| [6] |
N. Lorenzovici, E. H. Dulf, T. Mocan, L. Mocan, Artificial intelligence in colorectal cancer diagnosis using clinical data: Non-invasive approach, Diagnostics, 11 (2021), 514. https://doi.org/10.3390/diagnostics11030514 doi: 10.3390/diagnostics11030514
|
| [7] |
C. Zhou, Y. Jin, Y. Chen, S. Huang, R. Huang, Y. Wang, et al., Histopathology classification and localization of colorectal cancer using global labels by weakly supervised deep learning, Comput. Med. Imaging Graphics, 88 (2021), 101861. https://doi.org/10.1016/j.compmedimag.2021.101861 doi: 10.1016/j.compmedimag.2021.101861
|
| [8] |
M. J. Tsai, Y. H. Tao, Deep learning techniques for the classification of colorectal cancer tissue, Electronics, 10 (2021), 1662. https://doi.org/10.3390/electronics10141662 doi: 10.3390/electronics10141662
|
| [9] |
M. Ragab, W. H. Aljedaibi, A. F. Nahhas, I. R. Alzahrani, Computer aided diagnosis of diabetic retinopathy grading using spiking neural network, Comput. Electr. Eng., 101 (2022), 108014. https://doi.org/10.1016/j.compeleceng.2022.108014 doi: 10.1016/j.compeleceng.2022.108014
|
| [10] |
M. Mulenga, S. A. Kareem, A. Q. M. Sabri, M. Seera, S. Govind, C. Samudi, et al., Feature extension of gut microbiome data for deep neural network-based colorectal cancer classification, IEEE Access, 9 (2021), 23565–23578. https://doi.org/10.1109/ACCESS.2021.3050838 doi: 10.1109/ACCESS.2021.3050838
|
| [11] |
D. Albashish, Ensemble of adapted convolutional neural networks (CNN) methods for classifying colon histopathological images, PeerJ Comput. Sci., 8 (2022), e1031. https://doi.org/10.7717/peerj-cs.1031 doi: 10.7717/peerj-cs.1031
|
| [12] |
S. Mehmood, T. M. Ghazal, M. A. Khan, M. Zubair, M. T. Naseem, T. Faiz, et al., Malignancy detection in lung and colon histopathology images using transfer learning with class selective image processing, IEEE Access, 10 (2022), 25657–25668. https://doi.org/10.1109/ACCESS.2022.3150924 doi: 10.1109/ACCESS.2022.3150924
|
| [13] |
J. Fan, J. Lee, Y. Lee, A transfer learning architecture based on a support vector machine for histopathology image classification, Appl. Sci., 11 (2021), 6380. https://doi.org/10.3390/app11146380 doi: 10.3390/app11146380
|
| [14] |
M. Ragab, A. F. Nahhas, Optimal deep transfer learning model for histopathological breast cancer classification, CMC-Comput. Mater. Continua, 73 (2022), 2849–2864. https://doi.org/10.32604/cmc.2022.028855 doi: 10.32604/cmc.2022.028855
|
| [15] |
E. F. Ohata, J. V. S. D. Chagas, G. M. Bezerra, M. M. Hassan, V. H. C. de Albuquerque, A novel transfer learning approach for the classification of histological images of colorectal cancer, J. Supercomput., 77 (2021), 9494–9519. https://doi.org/10.1007/s11227-020-03575-6 doi: 10.1007/s11227-020-03575-6
|
| [16] |
E. Trivizakis, G. S. Ioannidis, I. Souglakos, A. H. Karantanas, M. Tzardi, K. Marias, A neural pathomics framework for classifying colorectal cancer histopathology images based on wavelet multi-scale texture analysis, Sci. Rep., 11 (2021), 1–10. https://doi.org/10.1038/s41598-021-94781-6 doi: 10.1038/s41598-021-94781-6
|
| [17] |
K. S. Wang, G. Yu, C. Xu, X. H. Meng, J. Zhou, C. Zheng, et al., Accurate diagnosis of colorectal cancer based on histopathology images using artificial intelligence, BMC Med., 19 (2021), 1–12. https://doi.org/10.1186/s12916-021-01942-5 doi: 10.1186/s12916-021-01942-5
|
| [18] |
S. Singh, H. Singh, A. Gehlot, IR and visible image fusion using DWT and bilateral filter, Microsyst. Technol., 2022 (2022), 1–11. https://doi.org/10.1007/s00542-022-05315-7 doi: 10.1007/s00542-022-05315-7
|
| [19] |
B. Jia, Q. Huang, DE-CapsNet: A diverse enhanced capsule network with disperse dynamic routing, Appl. Sci., 10 (2020), 884. https://doi.org/10.3390/app10030884 doi: 10.3390/app10030884
|
| [20] |
K. K. Chandriah, R. V. Naraganahalli, RNN/LSTM with modified Adam optimizer in deep learning approach for automobile spare parts demand forecasting, Multimedia Tools Appl., 80 (2021), 26145–26159. https://doi.org/10.1007/s11042-021-10913-0 doi: 10.1007/s11042-021-10913-0
|
| [21] |
B. Muthu, S. Cb, P. M. Kumar, S. N. Kadry, C. H. Hsu, O. Sanjuan, et al., A framework for extractive text summarization based on deep learning modified neural network classifier, ACM Trans. Asian Low-Resour. Lang. Inf. Process., 20 (2021), 1–20. https://doi.org/10.1145/3392048 doi: 10.1145/3392048
|
| [22] |
E. H. Houssein, B. E. D. Helmy, A. A. Elngar, D. S. Abdelminaam, H. Shaban, An improved tunicate swarm algorithm for global optimization and image segmentation, IEEE Access, 9 (2021), 56066–56092. https://doi.org/10.1109/ACCESS.2021.3072336 doi: 10.1109/ACCESS.2021.3072336
|
| [23] | Warwick Tissue Image Analytics (TIA) Centre. Available from: www.warwick.ac.uk/fac/sci/dcs/research/tia/glascontest/download. |
| [24] |
K. Sirinukunwattana, D. R. J. Snead, N. M. Rajpoot, A stochastic polygons model for glandular structures in colon histology images, IEEE Trans. Med. Imaging, 34 (2015), 2366–2378. https://doi.org/10.1109/TMI.2015.2433900 doi: 10.1109/TMI.2015.2433900
|
| [25] |
J. Escorcia-Gutierrez, M. Gamarra, P. P. Ariza-Colpas, G. B. Roncallo, N. Leal, R. Soto-Diaz, et al., Galactic swarm optimization with deep transfer learning driven colorectal cancer classification for image guided intervention, Comput. Electr. Eng., 104 (2022), 108462. https://doi.org/10.1016/j.compeleceng.2022.108462 doi: 10.1016/j.compeleceng.2022.108462
|









Figures(10) / Tables(3)
Abdullah S. AL-Malaise AL-Ghamdi, Mahmoud Ragab. Tunicate swarm algorithm with deep convolutional neural network-driven colorectal cancer classification from histopathological imaging data[J]. Electronic Research Archive, 2023, 31(5): 2793-2812. doi: 10.3934/era.2023141







 DownLoad:
DownLoad: