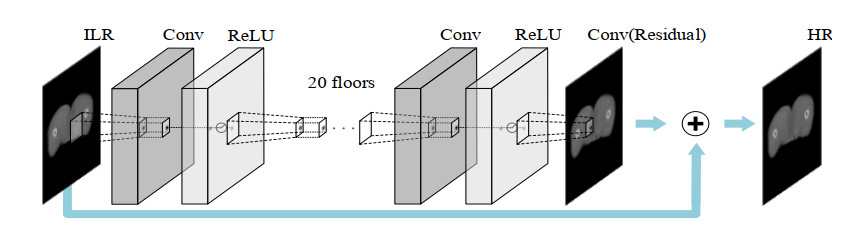
In order to enhance cone-beam computed tomography (CBCT) image information and improve the registration accuracy for image-guided radiation therapy, we propose a super-resolution (SR) image enhancement method. This method uses super-resolution techniques to pre-process the CBCT prior to registration. Three rigid registration methods (rigid transformation, affine transformation, and similarity transformation) and a deep learning deformed registration (DLDR) method with and without SR were compared. The five evaluation indices, the mean squared error (MSE), mutual information, Pearson correlation coefficient (PCC), structural similarity index (SSIM), and PCC + SSIM, were used to validate the results of registration with SR. Moreover, the proposed method SR-DLDR was also compared with the VoxelMorph (VM) method. In rigid registration with SR, the registration accuracy improved by up to 6% in the PCC metric. In DLDR with SR, the registration accuracy was improved by up to 5% in PCC + SSIM. When taking the MSE as the loss function, the accuracy of SR-DLDR is equivalent to that of the VM method. In addition, when taking the SSIM as the loss function, the registration accuracy of SR-DLDR is 6% higher than that of VM. SR is a feasible method to be used in medical image registration for planning CT (pCT) and CBCT. The experimental results show that the SR algorithm can improve the accuracy and efficiency of CBCT image alignment regardless of which alignment algorithm is used.
Citation: Liwei Deng, Yuanzhi Zhang, Jingjing Qi, Sijuan Huang, Xin Yang, Jing Wang. Enhancement of cone beam CT image registration by super-resolution pre-processing algorithm[J]. Mathematical Biosciences and Engineering, 2023, 20(3): 4403-4420. doi: 10.3934/mbe.2023204
In order to enhance cone-beam computed tomography (CBCT) image information and improve the registration accuracy for image-guided radiation therapy, we propose a super-resolution (SR) image enhancement method. This method uses super-resolution techniques to pre-process the CBCT prior to registration. Three rigid registration methods (rigid transformation, affine transformation, and similarity transformation) and a deep learning deformed registration (DLDR) method with and without SR were compared. The five evaluation indices, the mean squared error (MSE), mutual information, Pearson correlation coefficient (PCC), structural similarity index (SSIM), and PCC + SSIM, were used to validate the results of registration with SR. Moreover, the proposed method SR-DLDR was also compared with the VoxelMorph (VM) method. In rigid registration with SR, the registration accuracy improved by up to 6% in the PCC metric. In DLDR with SR, the registration accuracy was improved by up to 5% in PCC + SSIM. When taking the MSE as the loss function, the accuracy of SR-DLDR is equivalent to that of the VM method. In addition, when taking the SSIM as the loss function, the registration accuracy of SR-DLDR is 6% higher than that of VM. SR is a feasible method to be used in medical image registration for planning CT (pCT) and CBCT. The experimental results show that the SR algorithm can improve the accuracy and efficiency of CBCT image alignment regardless of which alignment algorithm is used.

| [1] |
A. K. Jain, Y. Zhong, S. Lakshmanan, Object matching using deformable templates, IEEE Trans. Pattern. Anal. Mach. Intell., 18 (1996), 267–278. https://doi.org/10.1109/34.485555 doi: 10.1109/34.485555

|
| [2] | D. P. Kingma, M, Welling, Auto-Encoding variational bayes, preprint, arXiv: 1312/6114. |
| [3] | A. Ahmadi, I. Patras, Unsupervised convolutional neural networks for motion estimation, in IEEE International Conference on Image Processing, IEEE, (2016), 1629–1633. https://doi.org/10.1109/ICIP.2016.7532634 |
| [4] | S. Joshi, B. Davis, M. Jomier, G. Gerig, Unbiased diffeomorphic atlas construction for computational anatomy, NeuroImage, 23 (2004), S151–S160. https://doi.org/10.1016/j.neuroimage.2004.07.068 |
| [5] |
M. A. Viergevera, J. B. Antoine-Maintzb, S. Kleinc, K. Murphyd, M. Staringe, J. P. W. Pluimfa, A survey of medical image registration-under review, Med. Image Anal., 33 (2016), 140–144. https://doi.org/10.1016/j.media.2016.06.030 doi: 10.1016/j.media.2016.06.030
|
| [6] |
Y. Fu, N. M. Brown, S. U. Saeed, A. Casamitjana, Y. Hu, DeepReg: a deep learning toolkit for medical image registration, J Open Source Softw., 5 (2020), 2705. https://doi.org/10.21105/joss.02705 doi: 10.21105/joss.02705
|
| [7] | D. FAIM, A ConvNet Method for Unsupervised 3D Medical Image Registration, in International Workshop on Machine Learning in Medical Imaging, Springer, (2019), 646–654. https://doi.org/10.1007/978-3-030-32692-0_74 |
| [8] |
Y. Fu, Y. Lei, T. Wang, W. J. Curran, T. Liu, X. Yang, Deep learning in medical image registration: A review, Phys. Med. Biol., 65 (2019), 20TR01. https://doi.org/10.1088/1361-6560/ab843e doi: 10.1088/1361-6560/ab843e
|
| [9] |
Y. Fu, S. Liu, H. H. Li, D. Yang, Automatic and hierarchical segmentation of the human skeleton in CT images, Phys. Med. Biol., 62 (2017), 2812–2833. https://doi.org/10.1088/1361-6560/aa6055 doi: 10.1088/1361-6560/aa6055
|
| [10] |
X. Yang, N. Wu, G. Cheng, Z. Zhou, D. S.Yu, J. J. Beitler, et al., Automated segmentation of the parotid gland based on atlas registration and machine learning: a longitudinal MRI study in head-and-neck radiation therapy, Int. J. Radiat. Oncol. Biol. Phys., 90 (2014), 1225–1233. https://doi.org/10.1016/j.ijrobp.2014.08.350 doi: 10.1016/j.ijrobp.2014.08.350
|
| [11] |
X. Huang, Y. Zhang, J. Wang, A biomechanical modeling guided simultaneous motion estimation and image reconstruction technique (SMEIR-Bio) for 4D-CBCT reconstruction, Phys. Med. Biol., 63 (2018), 045002. https://doi.org/10.1088/1361-6560/aaa730 doi: 10.1088/1361-6560/aaa730
|
| [12] | J. Boda-Heggemann, F. Lohr, F. Wenz, M. Flentje, M. Guckenberger, Cone-Beam CT-Based IGRT, Strahlenther Onkol., 187 (2011), 284–291. https://doi.org/10.1007/s00066-011-2236-4 |
| [13] |
X. Zhen, X. Gu, H. Yan, L. Zhou, X. Jia, S. B. Jiang, CT to Cone-beam CT deformable registration with simultaneous intensity correction, Phys. Med. Biol., 57 (2012), 6807–6826. https://doi.org/10.1088/0031-9155/57/21/6807 doi: 10.1088/0031-9155/57/21/6807
|
| [14] |
C. Veiga, J. Mcclelland, S. Moinuddin, A. Lourenço, K. Ricketts, J. Annkah, et al., Toward adaptive radiotherapy for head and neck patients: Feasibility study on using CT-to-CBCT deformable registration for "dose of the day" calculations, Med. Phys., 41 (2014), 031703. https://doi.org/10.1118/1.4864240 doi: 10.1118/1.4864240
|
| [15] |
C. Veiga, G. Janssens, C. L. Teng, T. Baudier, B. K. Teo, First clinical investigation of cone beam computed tomography and deformable registration for adaptive proton therapy for lung cancer, Int. J. Radiat. Oncol. Biol. Phys., 95 (2016), 549–559. https://doi.org/10.1016/j.ijrobp.2016.01.055 doi: 10.1016/j.ijrobp.2016.01.055
|
| [16] |
B. Zhou, Z. Augenfeld, J. Chapiro, S. K. Zhou, C. Liu, J. S. Duncan, Anatomy-guided multimodal registration by learning segmentation without ground truth: Application to intraprocedural CBCT/MR liver segmentation and registration, Med Image Anal, 71 (2021), 102041. https://doi.org/10.1016/j.media.2021.102041 doi: 10.1016/j.media.2021.102041
|
| [17] | B. Zhou, C. Liu, J. S. Duncan, Anatomy-Constrained contrastive learning for synthetic segmentation without ground-truth, in International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, (2021), 47–56. https://doi.org/10.1007/978-3-030-87193-2_5 |
| [18] |
X. Liang, Y. Jiang, Y. Xie, T. Niu, Quantitative cone-beam CT imaging in radiotherapy: Parallel computation and comprehensive evaluation on the TrueBeam system, IEEE Access, 7 (2019), 66226–66233. https://doi.org/10.1109/ACCESS.2019.2902168 doi: 10.1109/ACCESS.2019.2902168
|
| [19] |
K. Srinivasan, M. Mohammadi, J. Shepherd, Investigation of effect of reconstruction filters on cone-beam computed tomography image quality, Australas. Phys. Eng. Sci. Med., 37 (2014), 607–614. https://doi.org/10.1007/s13246-014-0291-8 doi: 10.1007/s13246-014-0291-8
|
| [20] |
L. Ouyang, T. Solberg, J. Wang, Noise reduction in low‐dose cone beam CT by incorporating prior volumetric image information, Med. Phys., 39 (2012), 2569–2577. https://doi.org/10.1118/1.3702592 doi: 10.1118/1.3702592
|
| [21] | W. Kang, M. Patwari, Low Dose Helical CBCT denoising by using domain filtering with deep reinforcement learning, preprint, arXiv: 2104/00889. |
| [22] | J. Zheng, D. Zhang, K. Huang, Y. Sun, Cone-Beam computed tomography image pretreatment and segmentation, in 2018 11th International Symposium on Computational Intelligence and Design (ISCID), IEEE, (2018), 25–28. https://doi.org/10.1109/ISCID.2018.00012 |
| [23] |
X. Liang, L. Chen, D. Nguyen, Z. Zhou, X. Gu, et al., Generating synthesized computed tomography (CT) from cone-beam computed tomography (CBCT) using CycleGAN for adaptive radiation therapy, Phys. Med. Biol., 64 (2019), 125002. https://doi.org/10.1088/1361-6560/ab22f9 doi: 10.1088/1361-6560/ab22f9
|
| [24] |
D. C. Hansen, G. Landry, F. Kamp, M. Li, C. Belka, K. Parodi, et al., ScatterNet: A convolutional neural network for cone‐beam CT intensity correction, Med. Phys., 45 (2019), 4916–4926. https://doi.org/10.1002/mp.13175 doi: 10.1002/mp.13175
|
| [25] | G. Wu, M. Kim, Q. Wang, Y. Gao, D. Shen, Unsupervised deep feature learning for deformable registration of MR brain images, in International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, (2013), 649–656. https://doi.org/10.1007/978-3-642-40763-5_80 |
| [26] | M. Simonovsky, B. Gutiérrez-Becker, D. Mateus, N. Navab, N. Komodakis, A deep metric for multimodal registration, in International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, (2016). https://doi.org/10.1007/978-3-319-46726-9_2 |
| [27] | C. Hao, D. Qi, N. Dong, J. Z. Cheng, P. A. Heng, Automatic fetal ultrasound standard plane detection using knowledge transferred recurrent neural networks, in International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, (2015). https://doi.org/10.1007/978-3-319-24553-9_62 |
| [28] |
S. Miao, Z. J. Wang, L. Rui, A CNN regression approach for Real-Time 2D/3D registration, IEEE Trans. Med. Imaging, 35 (2016), 1352–1363. https://doi.org/10.1109/TMI.2016.2521800 doi: 10.1109/TMI.2016.2521800
|
| [29] | X. Yang, R. Kwitt, M. Niethammer, Fast rredictive image registration, in Deep Learning and Data Labeling for Medical Applications, Springer, (2016), 48–57. https://doi.org/10.1007/978-3-319-46976-8_6 |
| [30] | D. Detone, T. Malisiewicz, A. Rabinovich, Deep image homography estimation, preprint, arXiv: 1606/03798. |
| [31] | T. Carvalho, E. Rezende, M. Alves, F. Balieiro, R. B. Sovat, Exposing computer generated images by eye's region classification via transfer learning of VGG19 CNN, in 16th IEEE International Conference On Machine Learning And Applications, IEEE, (2017). https://doi.org/10.1109/ICMLA.2017.00-47 |
| [32] | J. Krebs, T. Mansi, H. DelingetteZ. Li, F. Ghesu, S. Miao, et al., Robust non-rigid registration through agent-based action learning, in International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, (2017), 344–352. https://doi.org/10.1007/978-3-319-66182-7_40 |
| [33] | J. Zhang, C. Wang, S. Liu, L. Jia, J. Sun, Content-Aware unsupervised deep homography estimation, in European Conference on Computer Vision, Springer, (2020), 653–669. https://doi.org/10.1007/978-3-030-58452-8_38 |
| [34] | M. Bevilacqua, A. Roumy, C. Guillemot, M. L. A. Morel, Super-resolution using neighbor embedding of back-projection residuals, in 2013 18th International Conference on Digital Signal Processing (DSP), 2013.07, IEEE, (2013), 1–8. https://doi.org/10.1109/ICDSP.2013.6622796 |
| [35] | M. Bevilacqua, A. Roumy, C. Guillemot, M. L. A. Morel, Low-Complexity single-image super-resolution based on nonnegative neighbor embedding, in Proceedings of the British Machine Vision Conference 2012, (2012), 1–10. https://doi.org/10.5244/C.26.135 |
| [36] | R. Timofte, V. De, L. V. Gool, Anchored Neighborhood Regression for Fast Example-Based Super-Resolution, in IEEE International Conference on Computer Vision, IEEE, (2014), 1920–1927. https://doi.org/10.1109/ICCV.2013.241 |
| [37] | J. Kim, J. K. Lee, K. M. Lee, Accurate image super-resolution using very deep convolutional networks, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2016), 1646–1654. https://doi.org/10.1109/Cvpr.2016.182 |
| [38] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409/1556. |
| [39] |
C. Dong, C. C. Loy, K. He, X. Tang, Image super-resolution using deep convolutional networks, IEEE Trans. Pattern. Anal. Mach. Intell., 38 (2016), 295–307. https://doi.org/10.1109/TPAMI.2015.2439281 doi: 10.1109/TPAMI.2015.2439281
|
| [40] | J. Chen, Y. Li, Y. Du, E. C. Frey, Generating anthropomorphic phantoms using fully unsupervised deformable image registration with convolutional neural networks, Med. Phys., 47 (2020). https://doi.org/10.1002/mp.14545 |
| [41] | R. Sandkühler, C. Jud, S. Andermatt, P. C. Cattin, AirLab: Autograd image registration laboratory, preprint, arXiv: 1806/09907. |
| [42] | O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional networks for biomedical image segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |
| [43] |
D. Rueckert, L. I. Sonoda, C. Hayes, D. Hill, M. O. Leach, Nonrigid registration using free-form deformations: application to breast MR images, IEEE Trans. Med. Imaging, 18 (2012), 712–721. https://doi.org/10.1109/42.796284 doi: 10.1109/42.796284
|
| [44] |
T. Fechter, D. Baltas, One shot learning for deformable medical image registration and periodic motion tracking, IEEE Trans. Med. Imaging, 39 (2019), 12. https://doi.org/10.1109/TMI.2020.2972616 doi: 10.1109/TMI.2020.2972616
|
| [45] | A. V. Dalca, M. Rakic, J. Guttag, M. R. Sabuncu, Learning conditional deformable templates with convolutional networks, in NIPS'19: Proceedings of the 33rd International Conference on Neural Information Processing Systems, Curran Associates Inc., (2019), 806–818. |
| [46] |
P. Viola, W. Iii, Alignment by maximization of mutual information, Int. J. Comput. Vision, 24 (2008), 137v154. https://doi.org/10.1023/A:1007958904918 doi: 10.1023/A:1007958904918
|
| [47] |
Z. S. Saad, D. R. Glen, G. Chen, M. S. Beauchamp, R. Desai, R. W. Cox, A new method for improving functional-to-structural MRI alignment using local Pearson correlation, Neuroimage, 44 (2009), 839–848. https://doi.org/10.1016/j.neuroimage.2008.09.037 doi: 10.1016/j.neuroimage.2008.09.037
|
| [48] | Z. Shen, X. Han, Z. Xu, M. Niethammer, Networks for joint affine and Non-parametric image registration, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, (2019), 4224–4233. https://doi.org/10.1109/CVPR.2019.00435 |
| [49] |
M. Staring, S. Klein, J. Pluim, A rigidity penalty term for nonrigid registration, Med. Phys., 34 (2007), 4098–4108. https://doi.org/10.1118/1.2776236 doi: 10.1118/1.2776236
|
| [50] | L. Hui, P. Du, W. Zhao, L. Zhang, H. Sun, Image registration based on corner detection and affine transformation, in International Congress on Image & Signal Processing, IEEE, (2010), 2184–2188. https://doi.org/10.1109/CISP.2010.5647722 |
| [51] | C. Papazov, D. Burschka, Deformable 3D shape registration based on local similarity transforms, in Computer Graphics Forum, Wiley Online Library, (2011), 1493–1502. https://doi.org/10.1111/j.1467-8659.2011.02023.x |





Figures(6) / Tables(3)

Liwei Deng, Yuanzhi Zhang, Jingjing Qi, Sijuan Huang, Xin Yang, Jing Wang. Enhancement of cone beam CT image registration by super-resolution pre-processing algorithm[J]. Mathematical Biosciences and Engineering, 2023, 20(3): 4403-4420. doi: 10.3934/mbe.2023204







 DownLoad:
DownLoad: