We developed a new mathematical model for yellow fever under three types of intervention strategies: vaccination, hospitalization, and fumigation. Additionally, the side effects of the yellow fever vaccine were also considered in our model. To analyze the best intervention strategies, we constructed our model as an optimal control model. The stability of the equilibrium points and basic reproduction number of the model are presented. Our model indicates that when yellow fever becomes endemic or disappears from the population, it depends on the value of the basic reproduction number, whether it larger or smaller than one. Using the Pontryagin maximum principle, we characterized our optimal control problem. From numerical experiments, we show that the optimal levels of each control must be justified, depending on the strategies chosen to optimally control the spread of yellow fever.
Citation: Bevina D. Handari, Dipo Aldila, Bunga O. Dewi, Hanna Rosuliyana, Sarbaz H. A. Khosnaw. Analysis of yellow fever prevention strategy from the perspective of mathematical model and cost-effectiveness analysis[J]. Mathematical Biosciences and Engineering, 2022, 19(2): 1786-1824. doi: 10.3934/mbe.2022084
We developed a new mathematical model for yellow fever under three types of intervention strategies: vaccination, hospitalization, and fumigation. Additionally, the side effects of the yellow fever vaccine were also considered in our model. To analyze the best intervention strategies, we constructed our model as an optimal control model. The stability of the equilibrium points and basic reproduction number of the model are presented. Our model indicates that when yellow fever becomes endemic or disappears from the population, it depends on the value of the basic reproduction number, whether it larger or smaller than one. Using the Pontryagin maximum principle, we characterized our optimal control problem. From numerical experiments, we show that the optimal levels of each control must be justified, depending on the strategies chosen to optimally control the spread of yellow fever.

| [1] |
J. Florczak-Wyspianska, E. Nawotczynska, W. Kozubski, Yellow fever vaccine-associated neurotropic disease (yel-and)–a case report, Neurol. Neurochir., 51 (2017), 101–105. doi: 10.1016/j.pjnns.2016.09.002. doi: 10.1016/j.pjnns.2016.09.002

|
| [2] | United Nations, Prevention of Yellow Fever, 2019. Available from: https://www.cdc.gov/yellowfever/prevention/index.html. |
| [3] | United Nations, Yellow Fever, 2019. Available from: https://www.who.int/news-room/fact-sheets/detail/yellow-fever. |
| [4] |
J. E. Staples, A. D. Barrett, A. Wilder-Smith, J. Hombach, Review of data and knowledge gaps regarding yellow fever vaccine-induced immunity and duration of protection, Vaccines, 5 (2020), 1–7. doi: 10.1038/s41541-020-0205-6. doi: 10.1038/s41541-020-0205-6
|
| [5] |
D. Aldila, Analyzing the impact of the media campaign and rapid testing for covid-19 as an optimal control problem in east java, Indonesia, Chaos, Solitons Fractals, 141 (2020), 110364. doi: 10.1016/j.chaos.2020.110364. doi: 10.1016/j.chaos.2020.110364
|
| [6] |
D. Aldila, Optimal control for dengue eradication program under the media awareness effect, Int. J. Nonlinear Sci. Numer. Simul., 2021. doi: 10.1515/ijnsns-2020-0142. doi: 10.1515/ijnsns-2020-0142
|
| [7] | D. Aldila, Mathematical model for HIV spreads control program with ART treatment, in Journal of physics: Conference series, 974 (2018), 012035. |
| [8] |
C. A. G. Engelhard, A. P. Hodgkins, E. E. Pearl, P. K. Spears, J. Rychtar, D. Taylor, A mathematical model of Guinea worm disease in Chad with fish as intermediate transport hosts, J. Theor. Biol., 521 (2021), 110683. doi: 10.1016/j.jtbi.2021.110683. doi: 10.1016/j.jtbi.2021.110683
|
| [9] |
Z. Guo, G. Sun, Z. Wang, Z. Jin, L. Li, C. Li, Spatial dynamics of an epidemic model with nonlocal infection, Appl. Math. Comput., 377 (2020), 125158. doi: 10.1016/j.amc.2020.125158. doi: 10.1016/j.amc.2020.125158
|
| [10] |
G. Sun, M. Li, J. Zhang, W. Zhang, X. Pei, Z. Jin, Transmission dynamics of brucellosis: Mathematical modelling and applications in China, Comput. Struct. Biotechnol. J., 18 (2020), 3843–3860. doi: 10.1016/j.csbj.2020.11.014. doi: 10.1016/j.csbj.2020.11.014
|
| [11] |
M. Chapwanya, A. Matusse, Y. Dumont, On synergistic co-infection in crop diseases. The case of the Maize Lethal Necrosis Disease, Appl. Math. Modell., 90 (2021), 912–942. doi: 10.1016/j.apm.2020.09.036. doi: 10.1016/j.apm.2020.09.036
|
| [12] | Y. Belgaid, M. Helal, A. Lakmeche, E. Venturino, On the stability of periodic solutions of an impulsive system arising in the control of agroecosystems, in International Symposium on Mathematical and Computational Biology, (2020), 183–199. |
| [13] |
M. Kung'aro, L. Luboobi, F. Shahada, Modelling and stability analysis of SVEIRS yellow fever two host model, Gulf J. Math., 3 (2015), 106–129. doi: 10.1016/j.ces.2015.02.038. doi: 10.1016/j.ces.2015.02.038
|
| [14] |
S. Raimundo, M. Amaku, E. Massad, Equilibrium analysis of a yellow fever dynamical model with vaccination, Comput. Math. Methods Med., 2015 (2015), 482091. doi: 10.1155/2015/482091. doi: 10.1155/2015/482091
|
| [15] |
U. Danbaba, S. Garba, Stability analysis and optimal control for yellow fever model with vertical transmission, Int. J. Appl. Comput. Math, 6 (2020), 1–34. doi: 10.1007/s40819-020-00860-z. doi: 10.1007/s40819-020-00860-z
|
| [16] |
S. Zhao, L. Stone, D. Gao, D. He, Modelling the large-scale yellow fever outbreak in luanda, angola, and the impact of vaccination, PLoS Negl. Trop. Dis., 12 (2018), e0006158. doi: 10.1371/journal.pntd.0006158. doi: 10.1371/journal.pntd.0006158
|
| [17] |
F. Agusto, M. Leite, Optimal control and cost-effective analysis of the 2017 meningitis outbreak in Nigeria, Infect. Dis. Modell., 4 (2019), 161–187. doi: 10.1016/j.idm.2019.05.003. doi: 10.1016/j.idm.2019.05.003
|
| [18] |
M. Bruyand, M. Receveur, T. Pistone, C. Verdiere, R. Thiebaut, D. Malvy, Yellow fever vaccination in non-immunocompetent patients, Med. Mal. Infect., 38 (2008), 524–532. doi: 10.1016/j.medmal.2008.06.031. doi: 10.1016/j.medmal.2008.06.031
|
| [19] |
S. M. Raimundo, M. Amaku, E. Massad, Equilibrium analysis of a yellow fever dynamical model with vaccination, Comput. Math. Methods Med., 2015 (2015), 482091. doi: 10.1155/2015/482091. doi: 10.1155/2015/482091
|
| [20] | Pan American Health Organization/World Health Organization, Epidemiological update: yellow fever, 2018. Available from: https://reliefweb.int/report/brazil/epidemiological-update-yellow-fever-20-march-2018. |
| [21] |
F. M. Shearer, C. L. Moyes, D. M. Pigott, O. J. Brady, F. Marinho, A. Deshpande, et al., Global yellow fever vaccination coverage from 1970 to 2016: an adjusted retrospective analysis, Lancet Infect. Dis., 17 (2017), 1209–1217. doi: 10.1016/S1473-3099(17)30419-X. doi: 10.1016/S1473-3099(17)30419-X
|
| [22] |
K. W. Blayneh, A. B. Gumel, S. Lenhart, T. Clayton, Backward bifurcation and optimal control in transmission dynamics of West Nile virus, Bull. Math. Biol., 72 (2010), 1006–1028. doi: 10.1007/s11538-009-9480-0. doi: 10.1007/s11538-009-9480-0
|
| [23] |
B. Buonomo, R. D. Marca, Optimal bed net use for a dengue disease model with mosquito seasonal pattern, Math. Methods Appl. Sci., 41 (2018), 573–592. doi: 10.1002/mma.4629. doi: 10.1002/mma.4629
|
| [24] |
M. Andraud, N. Hens, C. Marais, P. Beutels, Dynamic epidemiological models for dengue transmission: a systematic review of structural approaches, PLoS ONE, 7 (2012), e49085. doi: 10.1371/journal.pone.0049085. doi: 10.1371/journal.pone.0049085
|
| [25] |
P. Cottin, M. Niedrig, C. Domingo, Safety profile of the yellow fever vaccine stamaril: a 17-year review, Expert Rev. Vaccines, 12 (2013), 1351–1368. doi: 10.1586/14760584.2013.836320. doi: 10.1586/14760584.2013.836320
|
| [26] |
D. Aldila, T. Götz, E. Soewono, An optimal control problem arising from a dengue disease transmission model, Math. Biosci., 242 (2013), 9–16. doi: 10.1016/j.mbs.2012.11.014. doi: 10.1016/j.mbs.2012.11.014
|
| [27] |
T. T. Yusuf, D. O. Daniel, Mathematical modelling of yellow fever transmission dynamics with multiple control measures, Asian Res. J. Math., 13 (2019), 1–15. doi: 10.9734/arjom/2019/v13i430112. doi: 10.9734/arjom/2019/v13i430112
|
| [28] |
D. Aldila, M. Angelina, Optimal control problem and backward bifurcation on malaria transmission with vector bias, Heliyon, 7 (2021), e06824. doi: 10.1016/j.heliyon.2021.e06824. doi: 10.1016/j.heliyon.2021.e06824
|
| [29] |
B. Handari, F. Vitra, R. Ahya, T. N. S, D. Aldila, Optimal control in a malaria model: intervention of fumigation and bed nets, Adv. Differ. Equations, 2019 (2019), 497. doi: 10.1186/s13662-019-2424-6. doi: 10.1186/s13662-019-2424-6
|
| [30] | M. S. Indriyono Tantoro, Pedoman Pencegahan Penyakit Yellow Fever, in Kementerian Kesehatan Republik Indonesia Direktorat Jenderal Pencegahan dan Pengendalian Penyakit, 2017. |
| [31] |
D. Aldila, B. M. Samiadji, G. M. Simorangkir, S. H. A. Khosnaw, M. Shahzad, Impact of early detection and vaccination strategy in covid-19 eradication program in jakarta, indonesia, BMC Res. Notes, 14 (2021), 132. doi: 10.1186/s13104–021–05540–9. doi: 10.1186/s13104–021–05540–9
|
| [32] |
I. M. Wangaria, S. Davisa, L. Stone, Backward bifurcation in epidemic models: Problems arisingwith aggregated bifurcation parameters, Appl. Math. Modell., 40 (2016), 1669–1675. doi: 10.1016/j.apm.2015.07.022. doi: 10.1016/j.apm.2015.07.022
|
| [33] |
O. Diekmann, J. A. P. Heesterbeek, M. G. Roberts, The construction of next-generation matrices for compartmental epidemic models, J. R. Soc. Interface, 7 (2010), 873–885. doi: 10.1098/rsif.2009.0386. doi: 10.1098/rsif.2009.0386
|
| [34] |
P. van den Driessche, J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Math. Biosci., 180 (2002), 29–48. doi: 10.1016/S0025-5564(02)00108-6. doi: 10.1016/S0025-5564(02)00108-6
|
| [35] |
G. Simorangkir, D. Aldila, A. Rizka, H. Tasman, E. Nugraha, Mathematical model of tuberculosis considering observed treatment and vaccination interventions, J. Interdiscip. Math., 24 (2021), 1717–1737. doi: 10.1080/09720502.2021.1958515. doi: 10.1080/09720502.2021.1958515
|
| [36] | D. Aldila, K. Rasyiqah, G. Ardaneswari, H. Tasman, A mathematical model of zika disease by considering transition from the asymptomatic to symptomatic phase, in Journal of Physics: Conference Series, 1821 (2021), 012001. doi: 10.1088/1742-6596/1821/1/012001. |
| [37] | D. Aldila, B. Handari, Effect of healthy life campaigns on controlling obesity transmission: A mathematical study, in Journal of Physics: Conference Series, 1747 (2021), 012003. doi: 10.1088/1742-6596/1747/1/012003. |
| [38] |
J. Li, Y. Zhao, S. Li, Fast and slow dynamics of malaria model with relapse, Math. Biosci., 246 (2013), 94–104. doi: 10.1098/rspb.2016.0048. doi: 10.1098/rspb.2016.0048
|
| [39] |
K. Nudee, S. Chinviriyasit, W. Chinviriyasit, The effect of backward bifurcation in controlling measles transmission by vaccination, Chaos Solitons Fractals, 123 (2018), 400–412. doi: 10.1016/j.chaos.2019.04.026. doi: 10.1016/j.chaos.2019.04.026
|
| [40] |
O. Sharomi, C. Podder, A. Gumel, E. Elbasha, J. Watmough, Role of incidence function in vaccine-induced backward bifurcation in some HIV models, Math. Biosci., 210 (2007), 436–463. doi: 10.1016/j.mbs.2007.05.012. doi: 10.1016/j.mbs.2007.05.012
|
| [41] |
C. Castillo–Chavez, B. Song, Dynamical models of tuberculosis and their applications, Math. Biosci. Eng., 1 (2014), 361–404. doi: 10.3934/mbe.2004.1.361. doi: 10.3934/mbe.2004.1.361
|
| [42] |
N. Chitnis, J. Hyman, J. Cushing, Determining important parameters in the spread of malaria through the sensitivity analysis of a mathematical model, Bull. Math. Biol., 70 (2008), 1272–1296. doi: 10.1007/s11538-008-9299-0. doi: 10.1007/s11538-008-9299-0
|
| [43] |
S. H. A. Khosnaw, M. Shahzad, M. Ali, F. Sultan, A quantitative and qualitative analysis of the covid–19 pandemic model, Chaos, Solitons Fractals, 138 (2020), 109932. doi: 10.1016/j.chaos.2020.109932. doi: 10.1016/j.chaos.2020.109932
|
| [44] |
S. H. A. Khosnaw, M. Shahzad, M. Ali, F. Sultan, Mathematical modelling for coronavirus disease (covid-19) in predicting future behaviours and sensitivity analysis, Math. Model. Nat. Phenom., 15 (2020), 33. doi: 10.1016/j.chaos.2020.109932. doi: 10.1016/j.chaos.2020.109932
|
| [45] |
A. Abidemi, N. Aziz, Optimal control strategies for dengue fever spread in Johor, Malaysia, Comput. Methods Programs Biomed., 196 (2020), 105585. doi: 10.1016/j.cmpb.2020.105585. doi: 10.1016/j.cmpb.2020.105585
|
| [46] |
D. Aldila, M. Ndii, B. Samiadji, Optimal control on covid-19 eradication program in Indonesia under the effect of community awareness, Math. Biosci. Eng., 17 (2021), 6355–6389. doi: 10.3934/mbe.2020335. doi: 10.3934/mbe.2020335
|
| [47] |
N. Sharma, R. Singh, J. Singh, E. Castillo, Modeling assumptions, optimal control strategies and mitigation through vaccination to zika virus, Chaos, Solitons Fractals, 150 (2021), 111137. doi: 10.1016/j.chaos.2021.111137. doi: 10.1016/j.chaos.2021.111137
|
| [48] |
N. Sweilam, S. Al-Mekhlafi, Optimal control for a fractional tuberculosis infection model including the impact of diabetes and resistant strains, J. Adv. Res., 17 (2019), 125–137. doi: 10.3934/mbe.2020335. doi: 10.3934/mbe.2020335
|
| [49] | L. Pontryagin, V. Boltyanskii, R. Gamkrelidze, E. Mishchenko, The Mathematical Theory of Optimal Processes, Interscience Publishers John Wiley & Sons, Inc., New York-London. |
| [50] | S. Lenhart, J. Workman, Optimal Control Applied to Biological Models, Chapman and Hall, London/Boca Raton, 2007. |
| [51] | K. Okosun, O. Rachid, N. Marcus, Optimal control strategies and cost-effectiveness analysis of a malaria model, BioSystems, 111 (2013), 83–101. doi: 0.1016/j.biosystems.2012.09.008. |
| [52] |
F. Agusto, I. ELmojtaba, Optimal control and cost-effective analysis of malaria/visceral leishmaniasis co–infection, PLoS ONE, 12 (2017), 1–31. doi: 10.1371/journal.pone.0171102. doi: 10.1371/journal.pone.0171102
|
| [53] |
J. Akanni, F. Akinpelu, S. Olaniyi, A. Oladipo, A. Ogunsola, Modelling financial crime population dynamics: optimal control and cost-effectiveness analysis, Int. J. Dyn. Control, 2019 (2019), 1–14. doi: 10.1007/s40435-019-00572-3. doi: 10.1007/s40435-019-00572-3
|
| [54] | E. Q. Lima, M. L. Nogueira, Viral hemorrhagic fever-induced acute kidney injury, in Seminars in Nephrology, 28 (2008), 409–415. doi: 10.1016/j.semnephrol.2008.04.009. |
| [55] |
R. Klitting, E. A. Gould, C. Paupy, X. De Lamballerie, What does the future hold for yellow fever virus?, Genes, 9 (2018), 291. doi: 10.3390/genes9060291. doi: 10.3390/genes9060291
|
| [56] |
I. McGuinness, J. D. Beckham, K. L. Tyler, D. M. Pastula, An overview of yellow fever virus disease, Neurohospitalist, 7 (2017), 157. doi: 10.1177/1941874417708129. doi: 10.1177/1941874417708129
|
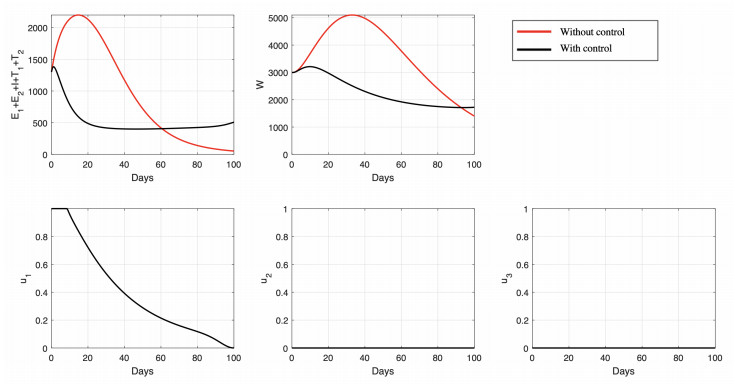
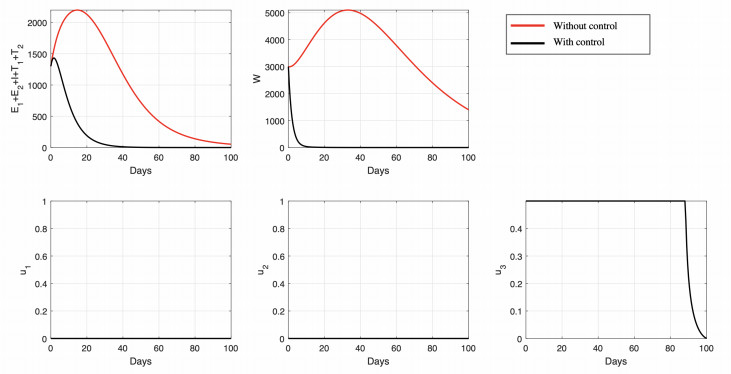
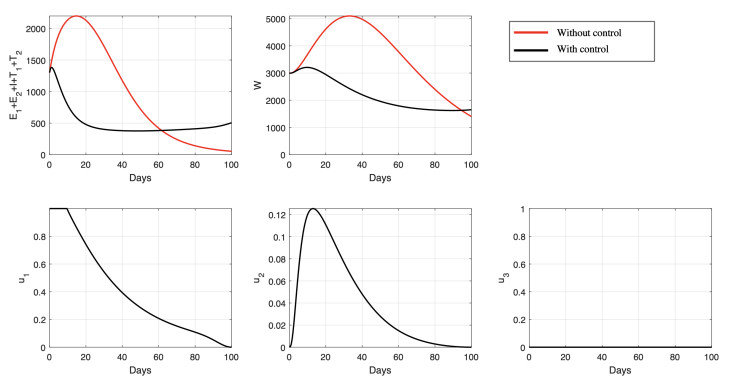
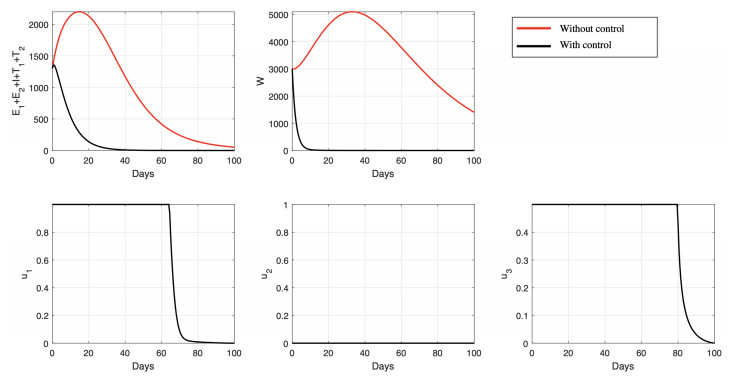
Figures(15) / Tables(6)

Bevina D. Handari, Dipo Aldila, Bunga O. Dewi, Hanna Rosuliyana, Sarbaz H. A. Khosnaw. Analysis of yellow fever prevention strategy from the perspective of mathematical model and cost-effectiveness analysis[J]. Mathematical Biosciences and Engineering, 2022, 19(2): 1786-1824. doi: 10.3934/mbe.2022084







 DownLoad:
DownLoad: