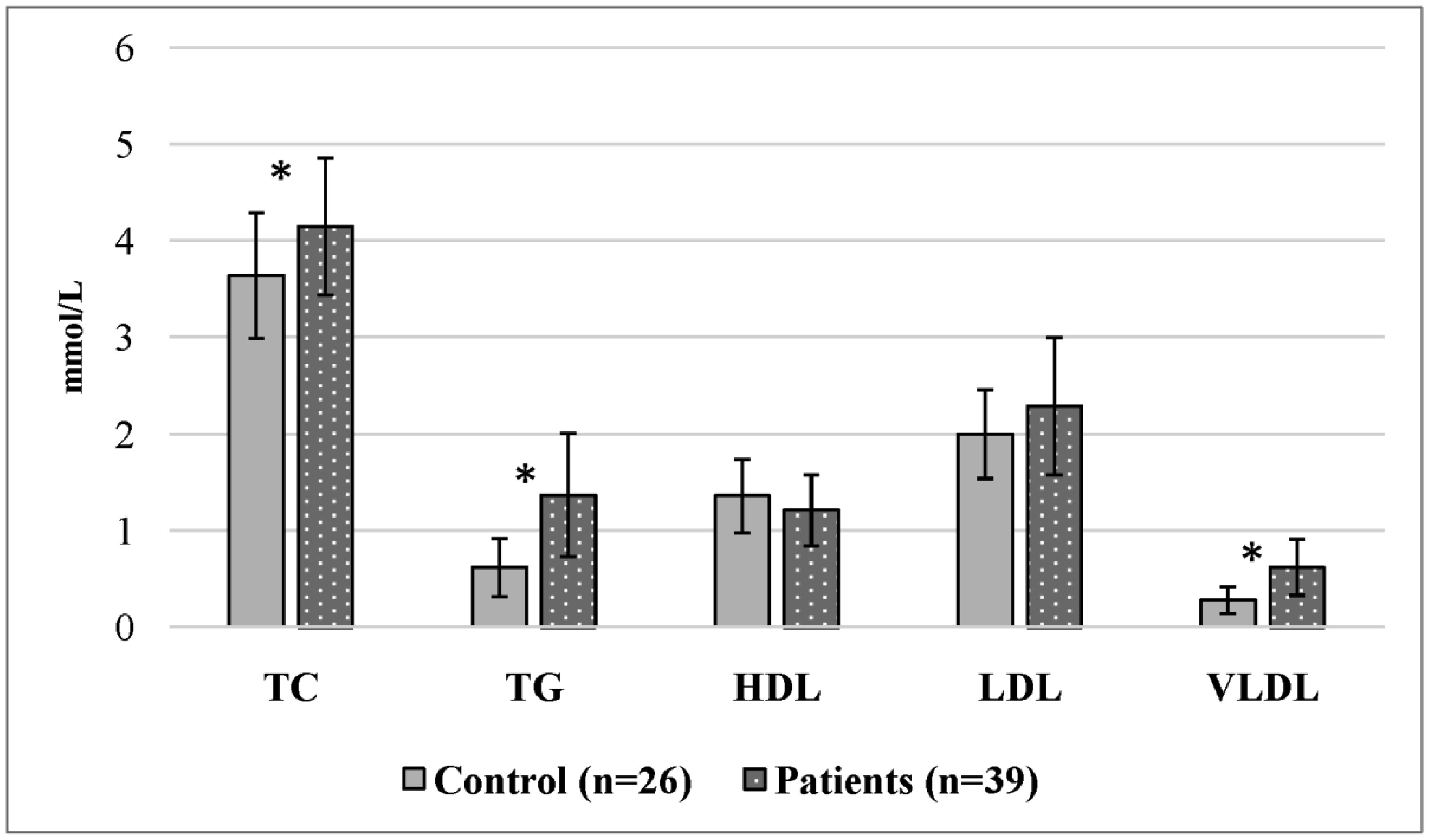
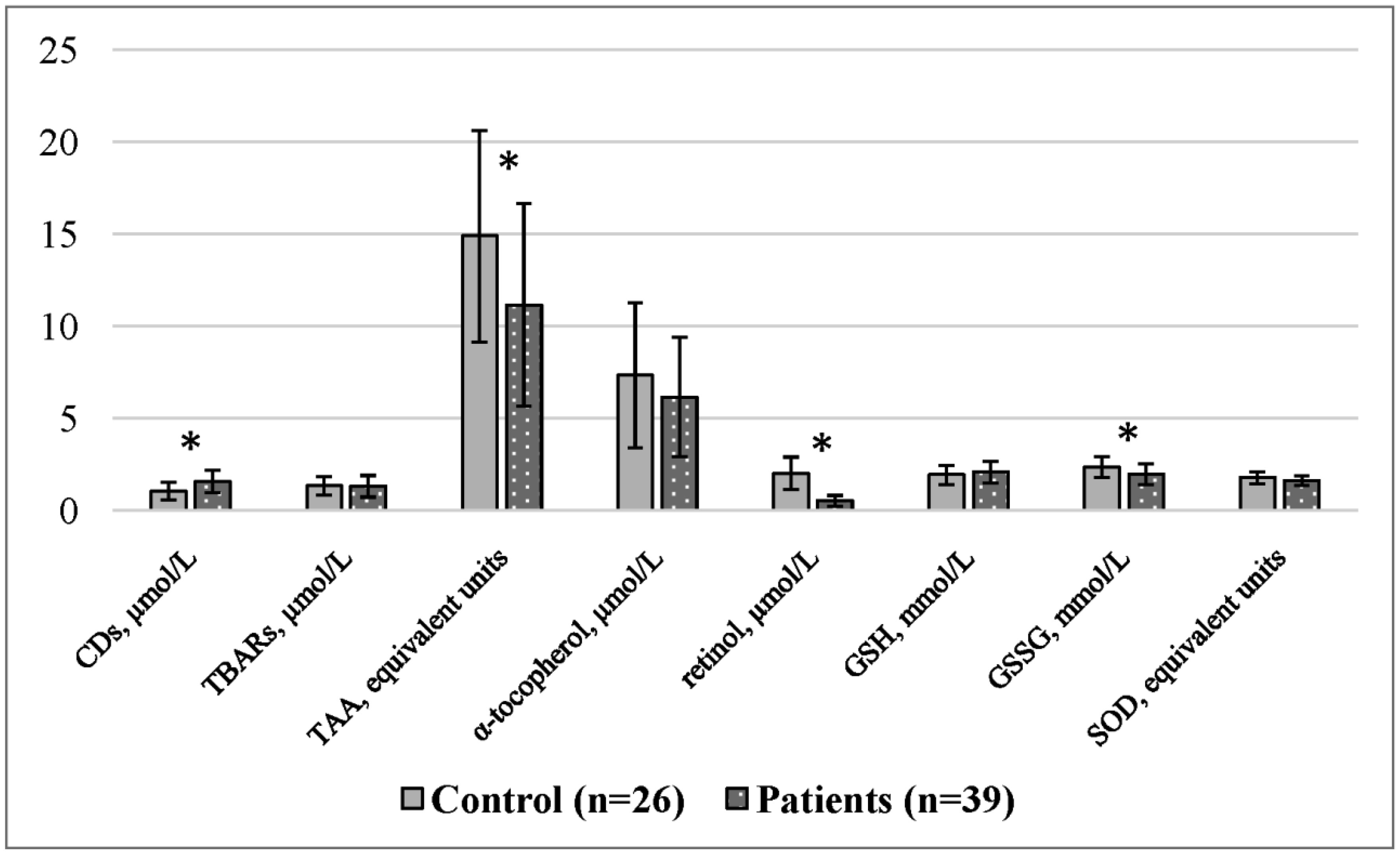
The study of the molecular mechanisms involved in adolescent obesity formation is important due to the severe and prolonged complications in adulthood. Here, we analyzed the lipid metabolism and peroxidation systems and the relationships between them in girls with constitutional obesity. Thirty-nine adolescent girls 14–16 age with constitutional obesity and twenty-six girls with a normal body mass index (control group) of the same age were examined. Spectrophotometric and fluorometric research methods were used. Constitutional obesity in adolescent girls is accompanied by the development of dyslipidemia (increased concentrations of total cholesterol, triacylglycerols, and very-low-density lipoproteins), as well as by reduced antioxidant defense components (total antioxidant activity, retinol, and the oxidized form of glutathione). In addition, adolescent girls with constitutional obesity had an increased number of correlations in the lipid peroxidation–antioxidant defense system and intersystem correlations, which indicates the insufficient activity of the antioxidant defense system. These results increase our understanding of the pathogenic mechanisms involved in adolescent.
Citation: Marina A. Darenskaya, Liubov I. Kolesnikova, Liubov V. Rychkova, Olga V. Kravtsova, Natalya V. Semenova, Sergei I. Kolesnikov. Relationship between lipid metabolism state, lipid peroxidation and antioxidant defense system in girls with constitutional obesity[J]. AIMS Molecular Science, 2021, 8(2): 117-126. doi: 10.3934/molsci.2021009
The study of the molecular mechanisms involved in adolescent obesity formation is important due to the severe and prolonged complications in adulthood. Here, we analyzed the lipid metabolism and peroxidation systems and the relationships between them in girls with constitutional obesity. Thirty-nine adolescent girls 14–16 age with constitutional obesity and twenty-six girls with a normal body mass index (control group) of the same age were examined. Spectrophotometric and fluorometric research methods were used. Constitutional obesity in adolescent girls is accompanied by the development of dyslipidemia (increased concentrations of total cholesterol, triacylglycerols, and very-low-density lipoproteins), as well as by reduced antioxidant defense components (total antioxidant activity, retinol, and the oxidized form of glutathione). In addition, adolescent girls with constitutional obesity had an increased number of correlations in the lipid peroxidation–antioxidant defense system and intersystem correlations, which indicates the insufficient activity of the antioxidant defense system. These results increase our understanding of the pathogenic mechanisms involved in adolescent.
antioxidant defense
body mass index
conjugated
diastolic blood pressure
reduced glutathione
oxidized glutathione
high-density lipoproteins
low-density lipoproteins
lipid peroxidation
oxidative stress
polyunsaturated fatty acids
systolic blood pressure
standard deviation
standard deviation score of body mass index
superoxide dismutase
total antioxidant activity
thiobarbituric acid
low-density lipoproteins
World Health Organization

| [1] |
Spinelli A, Buoncristiano M, Kovacs VA, et al. (2019) Prevalence of severe obesity among primary school children in 21 European countries. Obes Facts 12: 244-258. doi: 10.1159/000500436

|
| [2] |
Filgueiras MS, Rocha NP, Novaes JF, et al. (2020) Vitamin D status, oxidative stress, and inflammation in children and adolescents: a systematic review. Crit Rev Food Sci Nutr 60: 660-669. doi: 10.1080/10408398.2018.1546671
|
| [3] |
Kirk S, Armstrong S, King E, et al. (2017) Establishment of the pediatric obesity weight evaluation registry: a national research collaborative for identifying the optimal assessment and treatment of pediatric obesity. Child Obes 13: 9-17. doi: 10.1089/chi.2016.0060
|
| [4] |
Ng M, Fleming T, Robinson M, et al. (2014) Global, regional, and national prevalence of overweight and obesity in children and adults during 1980–2013: a systematic analysis for the Global Burden of Disease Study 2013. Lancet 384: 766-781. doi: 10.1016/S0140-6736(14)60460-8
|
| [5] |
Heymsfield SB, Wadden TA (2017) Mechanisms, pathophysiology, and management of obesity. N Engl J Med 376: 254-266. doi: 10.1056/NEJMra1514009
|
| [6] |
O'Connor TG, Williams J, Blair C, et al. (2020) Predictors of developmental patterns of obesity in young children. Front Pediatr 8: 109. doi: 10.3389/fped.2020.00109
|
| [7] | Tutelyan VA, Baturin AK, Kon IYa, et al. (2014) Prevalence of obesity and overweight among the child population of the Russian Federation: a multicenter study. J Pediatria 93: 28-31. |
| [8] |
Darenskaya MA, Rychkova LV, Semenova NV, et al. (2020) Parameters of lipid metabolism and antioxidant status in adolescent mongoloids with exogenous-constitutional obesity. Free Radic Biol Med 159: S66-S67. doi: 10.1016/j.freeradbiomed.2020.10.176
|
| [9] |
Darenskaya MA, Rychkova LV, Zhdanova LA, et al. (2019) Oxidative stress assessment in different ethnic groups of girls with exogenous constitutional obesity complicated by non-alcoholic fatty liver disease. Int J Biomed 9: 223-227. doi: 10.21103/Article9(3)_OA7
|
| [10] |
Kolesnikova LI, Darenskaya MA, Rychkova LV, et al. (2018) Antioxidant status in adolescents of small Siberian ethnoses. J Evol Biochem Physiol 54: 130-136. doi: 10.1134/S0022093018020060
|
| [11] |
Kolesnikova LI, Darenskaya MA, Kolesnikov SI (2017) Free radical oxidation: a pathophysiologist's view. Bull Sib Med 16: 16-29. doi: 10.20538/1682-0363-2017-4-16-29
|
| [12] |
Zuo L, Prather ER, Stetskiv M, et al. (2019) Inflammaging and oxidative stress in human diseases: from molecular mechanisms to novel treatments. Inter J Mol Sci 20: 4472. doi: 10.3390/ijms20184472
|
| [13] |
Kolesnikova LI, Semyonova NV, Grebenkina LA, et al. (2014) Integral indicator of oxidative stress in human blood. Bull Exp Biol Med 157: 715-717. doi: 10.1007/s10517-014-2649-z
|
| [14] |
Marseglia L, Manti S, D'Angelo G, et al. (2015) Oxidative stress in obesity: a critical component in human diseases. Inter J Mol Sci 16: 378-400. doi: 10.3390/ijms16010378
|
| [15] |
Magdalena A, Pop PA (2015) The role of antioxidants in the chemistry of oxidative stress: a review. Eur J Med Chem 97: 55-74. doi: 10.1016/j.ejmech.2015.04.040
|
| [16] |
Ershova OA, Bairova TA, Kolesnikov SI, et al. (2016) Oxidative stress and catalase gene. Bull Exp Biol Med 161: 400-403. doi: 10.1007/s10517-016-3424-0
|
| [17] |
Rani V, Deep G, Singh RK, et al. (2016) Oxidative stress and metabolic disorders: pathogenesis and therapeutic strategies. Life Sci 148: 183-193. doi: 10.1016/j.lfs.2016.02.002
|
| [18] |
Styne DM, Arslanian SA, Connor EL, et al. (2017) Pediatric obesity—assessment, treatment, and prevention: an Endocrine Society Clinical Practice guideline. J Clin Endocrinol Metab 102: 709-757. doi: 10.1210/jc.2016-2573
|
| [19] | Aleksandrov AA, Bubnova MG, Kislyak OA, et al. (2012) Prevention of cardiovascular diseases in childhood and adolescence. Russ J Cardiol 17: 4-39. |
| [20] |
Corongiu FP, Banni S (1994) Detection of conjugated dienes by second derivative ultraviolet spectrophotometry. Methods Enzymol 23: 303-310. doi: 10.1016/S0076-6879(94)33033-6
|
| [21] |
Asakava T, Matsushita S (1980) Coloring conditions of thiobarbituricacid test, for detecting lipid hydroperoxides. Lipids 15: 137-140. doi: 10.1007/BF02540959
|
| [22] |
Rice-Evans C, Miller NJ (1994) Total antioxidant status in plasma and body fluids. Methods Enzymol 234: 279-293. doi: 10.1016/0076-6879(94)34095-1
|
| [23] | Chernyauskene RCh, Varshkyavichene ZZ, Gribauskas S (1984) Simultaneous determination of the concentrations of vitamins E and A in the serum. Lab Delo 6: 362-365. |
| [24] |
Hisin PJ, Hilf R (1976) Fluorоmetric method for determination of oxidized and reduced glutathione in tissues. Anal Biochem 74: 214-226. doi: 10.1016/0003-2697(76)90326-2
|
| [25] |
Misra HP, Fridovich I (1972) The role of superoxide anion in the autoxidation of epinephrine and a simple assay for superoxide dismutase. J Biol Chem 247: 3170-3175. doi: 10.1016/S0021-9258(19)45228-9
|
| [26] |
Camacho S, Ruppel A (2017) Is the calorie concept a real solution to the obesity epidemic? Global Health Action 10: 1289650. doi: 10.1080/16549716.2017.1289650
|
| [27] |
Leffa PS, Hoffman DJ, Rauber F, et al. (2020) Longitudinal associations between ultra-processed foods and blood lipids in childhood. Br J Nutr 124: 341-348. doi: 10.1017/S0007114520001233
|
| [28] |
Zhou H, Urso CJ, Jadeja V (2020) Saturated fatty acids in obesity-associated inflammation. J Inflammation Res 13: 1. doi: 10.2147/JIR.S229691
|
| [29] |
Akshaj P, Manjari D, Goberdhan PD (2016) Oxidative stress, cellular senescence and ageing. AIMS Mol Sci 3: 300-324. doi: 10.3934/molsci.2016.3.300
|
| [30] |
Bianchi VE, Falcioni G (2016) Reactive oxygen species, health and longevity. AIMS Mol Sci 3: 479-504. doi: 10.3934/molsci.2016.4.479
|
| [31] |
Fischer-Posovszky P, Möller P (2020) The immune system of adipose tissue: obesity-associated inflammation. Pathologe 41: 224-229. doi: 10.1007/s00292-020-00782-z
|
| [32] |
Sies H (2015) Oxidative stress: a concept in redox biology and medicine. Redox Biol 14: 180-183. doi: 10.1016/j.redox.2015.01.002
|
| [33] |
Olsen T, Blomhoff R (2020) Retinol, retinoic acid, and retinol-binding protein 4 are differentially associated with cardiovascular disease, type 2 diabetes, and obesity: an overview of human studies. Adv Nutr 11: 644-666. doi: 10.1093/advances/nmz131
|
| [34] |
Mohd Mutalip S, Ab-Rahim S, Rajikin M (2018) Vitamin E as an antioxidant in female reproductive health. Antioxidants 7: 22. doi: 10.3390/antiox7020022
|
| [35] |
Kolesnikova LI, Rychkova LV, Darenskaya MA, et al. (2020) Peculiarities of pro- and antioxidant status in adolescents, representatives of two ethnic groups with exogenous-constitutional 1st-degree obesity. J Pediatria 99: 201-206. doi: 10.24110/0031-403X-2020-99-5-201-206
|
Figures(2) / Tables(2)

Marina A. Darenskaya, Liubov I. Kolesnikova, Liubov V. Rychkova, Olga V. Kravtsova, Natalya V. Semenova, Sergei I. Kolesnikov. Relationship between lipid metabolism state, lipid peroxidation and antioxidant defense system in girls with constitutional obesity[J]. AIMS Molecular Science, 2021, 8(2): 117-126. doi: 10.3934/molsci.2021009







 DownLoad:
DownLoad: