Citation: Roy H. Goodman, Maurizio Porfiri. Topological features determining the error in the inference of networks using transfer entropy[J]. Mathematics in Engineering, 2020, 2(1): 34-54. doi: 10.3934/mine.2020003

| [1] | Albert R, Barabási AL (2002) Statistical mechanics of complex networks. Rev Mod Phys 74: 47-97. |
| [2] | Anderson RP, Jimenez G, Bae JY, et al. (2016) Understanding policy diffusion in the us: An information-theoretical approach to unveil connectivity structures in slowly evolving complex systems. SIAM J Appl Dyn Syst 15: 1384-1409. |
| [3] | Bernstein DS (2018) Scalar, Vector, and Matrix Mathematics: Theory, Facts, and Formulas-Revised and Expanded Edition, Princeton University Press. |
| [4] | Boccaletti S, Latora V, Moreno Y, et al. (2006) Complex networks: Structure and dynamics. Phys Rep 424: 175-308. |
| [5] | Bollt EM, Sun J, Runge J (2018) Introduction to focus issue: Causation inference and information flow in dynamical systems: Theory and applications. Chaos 28: 075201. |
| [6] | Bossomaier T, Barnett L, Harré M, et al. (2016) An Introduction to Transfer Entropy: Information Flow in Complex Systems, Springer International Publishing. |
| [7] | Brémaud P (2013) Markov Chains: Gibbs Fields, Monte Carlo Simulation, and Queues, Springer Science & Business Media. |
| [8] | Bullmore E, Sporns O (2009) Complex brain networks: Graph theoretical analysis of structural and functional systems. Nat Rev Neurosci 10: 186. |
| [9] | Cover T, Thomas J (2012) Elements of Information Theory, Wiley. |
| [10] | Dunne JA, Williams RJ, Martinez ND (2002) Food-web structure and network theory: The role of connectance and size. Proc Natl Acad Sci USA 99: 12917-12922. |
| [11] | Erdös P, Rényi A (1959) On random graphs, I. Publ Math Debrecen 6: 290-297. |
| [12] | Godsil C, Royle GF (2013) Algebraic Graph Theory, Springer Science & Business Media. |
| [13] | Grabow C, Macinko J, Silver D, et al. (2016) Detecting causality in policy diffusion processes. Chaos 26: 083113. |
| [14] | Keeling MJ, Eames KT (2005) Networks and epidemic models. J R Soc Interface 2: 295-307. |
| [15] | Khinchin A (1957) Mathematical Foundations of Information Theory, Dover Publications. |
| [16] | Nayfeh AH (2011) Introduction to Perturbation Techniques, John Wiley & Sons. |
| [17] | Paninski L (2003) Estimation of entropy and mutual information. Neural Comput 15: 1191-1253. |
| [18] | Pecora LM, Carroll TL (1990) Synchronization in chaotic systems, Phys Rev Lett 64: 821. |
| [19] | Porfiri M, Ruiz Marín M (2018) Inference of time-varying networks through transfer entropy, the case of a Boolean network model. Chaos 28: 103123. |
| [20] | Porfiri M, Ruiz Marín M (2018) Information flow in a model of policy diffusion: An analytical study. IEEE Trans Network Sci Eng 5: 42-54. |
| [21] | Prettejohn BJ, Berryman MJ, McDonnell MD, et al. (2011) Methods for generating complex networks with selected structural properties for simulations: A review and tutorial for neuroscientists. Front Comput Neurosci 5: 11. |
| [22] | Ramos AM, Builes-Jaramillo A, Poveda G, et al. (2017) Recurrence measure of conditional dependence and applications. Phys Rev E 95: 052206. |
| [23] | Roxin A, Hakim V, Brunel N (2008) The statistics of repeating patterns of cortical activity can be reproduced by a model network of stochastic binary neurons. J Neurosci 28: 10734-10745. |
| [24] | Runge J (2018) Causal network reconstruction from time series: From theoretical assumptions to practical estimation. Chaos 28: 075310. |
| [25] | Schreiber T (2000) Measuring information transfer. Phys Rev Lett 85: 461-464. |
| [26] | Squartini T, Caldarelli G, Cimini G, et al. (2018) Reconstruction methods for networks: The case of economic and financial systems. Phys Rep 757: 1-47. |
| [27] | Staniek M, Lehnertz K (2008) Symbolic transfer entropy. Phys Rev Lett 100: 158101. |
| [28] | Sun J, Taylor D, Bollt EM (2015) Causal network inference by optimal causation entropy. SIAM J Appl Dyn Syst 14: 73-106. |
| [29] | Wibral M, Pampu N, Priesemann V, et al. (2013) Measuring information-transfer delays. PLoS One 8: e55809. |
| [30] | Wibral M, Vicente R, Lizier JT (2014) Directed Information Measures in Neuroscience, Springer. |
| [31] | Yule GU (1925) II.-A mathematical theory of evolution, based on the conclusions of Dr. JC Willis, FRS. Philos Trans R Soc London Ser B 213: 21-87. |
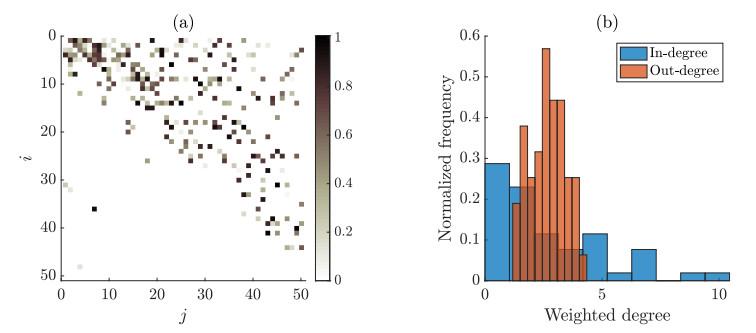
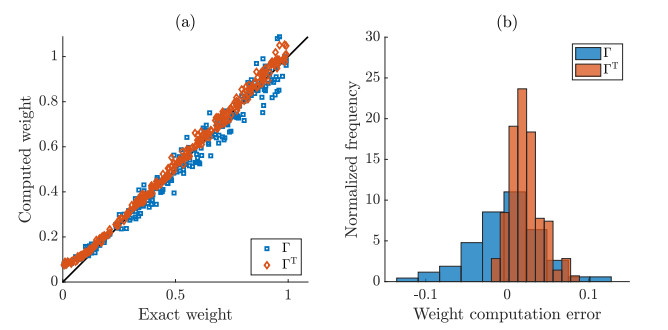
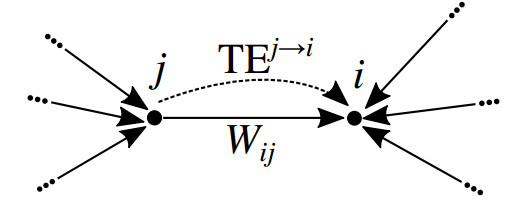

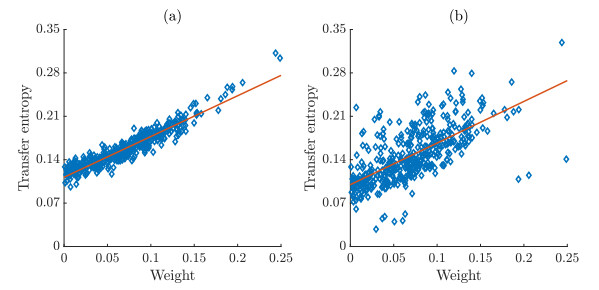
Figures(5)

Roy H. Goodman, Maurizio Porfiri. Topological features determining the error in the inference of networks using transfer entropy[J]. Mathematics in Engineering, 2020, 2(1): 34-54. doi: 10.3934/mine.2020003







 DownLoad:
DownLoad: