Twitter represents a growing aspect of the social media experience and is a widely used tool for public education in the 21st century. In the last few years, there has been concern about the dissemination of false health information on social media. It is therefore important that we assess the influencers of this health information in the field of cardiology.
We sought to identify the top 100 Twitter influencers within cardiology, characterize them, and examine the relationship between their social media activity and academic influence.
Twitter topic scores for the topic search “cardiology” were queried on May 01, 2020 using the Right Relevance application programming interface (API). Based on their scores, the top 100 influencers were identified. Among the cardiologists, their academic h-indices were acquired from Scopus and these scores were compared to the Twitter topic scores.
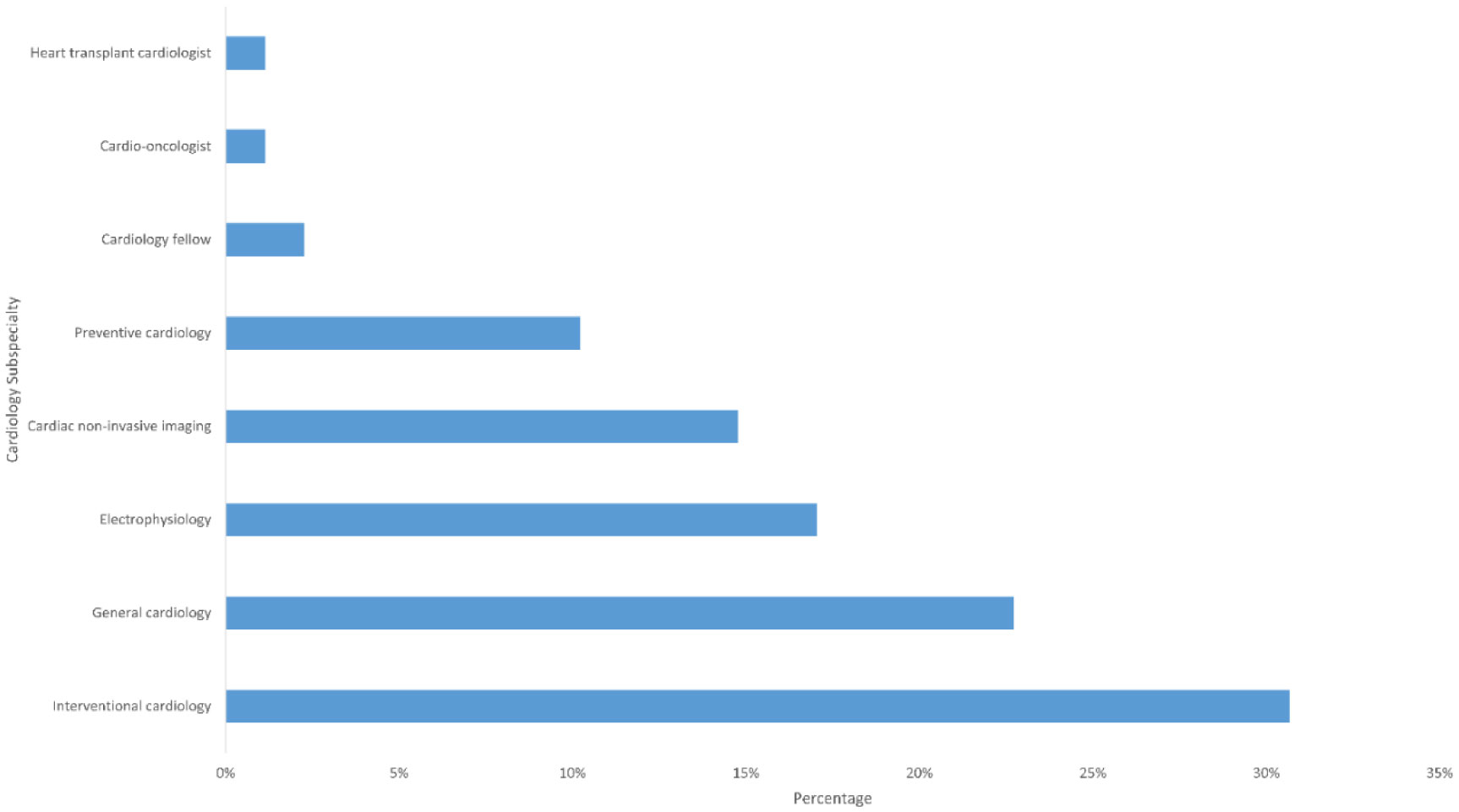
We found out that 88/100 (88%) of the top 100 social media influencers on Twitter were cardiologists. Of these, 63/88 (72%) were males and they practiced mostly in the United States with 50/87 (57%) practicing primarily in an academic hospital. There was a moderately positive correlation between the h-index and the Twitter topic score, r = +0.32 (p-value 0.002).
Our study highlights that the top ranked cardiology social media influencers on Twitter are board-certified male cardiologists practicing in academic settings in the US. The most influential on Twitter have a moderate influence in academia. Further research should evaluate the relationship between other academic indices and social media influence.
Citation: Onoriode Kesiena, Henry K Onyeaka, Setri Fugar, Alexis K Okoh, Annabelle Santos Volgman. The top 100 Twitter influencers in cardiology[J]. AIMS Public Health, 2021, 8(4): 743-753. doi: 10.3934/publichealth.2021058
Twitter represents a growing aspect of the social media experience and is a widely used tool for public education in the 21st century. In the last few years, there has been concern about the dissemination of false health information on social media. It is therefore important that we assess the influencers of this health information in the field of cardiology.
We sought to identify the top 100 Twitter influencers within cardiology, characterize them, and examine the relationship between their social media activity and academic influence.
Twitter topic scores for the topic search “cardiology” were queried on May 01, 2020 using the Right Relevance application programming interface (API). Based on their scores, the top 100 influencers were identified. Among the cardiologists, their academic h-indices were acquired from Scopus and these scores were compared to the Twitter topic scores.
We found out that 88/100 (88%) of the top 100 social media influencers on Twitter were cardiologists. Of these, 63/88 (72%) were males and they practiced mostly in the United States with 50/87 (57%) practicing primarily in an academic hospital. There was a moderately positive correlation between the h-index and the Twitter topic score, r = +0.32 (p-value 0.002).
Our study highlights that the top ranked cardiology social media influencers on Twitter are board-certified male cardiologists practicing in academic settings in the US. The most influential on Twitter have a moderate influence in academia. Further research should evaluate the relationship between other academic indices and social media influence.

| [1] | Lokot T, Diakopoulos N (2016) News Bots: Automating news and information dissemination on Twitter. Digit Journal 4: 682-699. |
| [2] |
Arora A, Bansal S, Kandpal C, et al. (2019) Measuring social media influencer index- insights from facebook, Twitter and Instagram. J Retail Consum Serv 49: 86-101. doi: 10.1016/j.jretconser.2019.03.012

|
| [3] |
Lou C, Yuan S (2019) Influencer Marketing: How Message Value and Credibility Affect Consumer Trust of Branded Content on Social Media. J Interact Advert 19: 58-73. doi: 10.1080/15252019.2018.1533501
|
| [4] |
Featherstone JD, Ruiz JB, Barnett GA, et al. (2020) Exploring childhood vaccination themes and public opinions on Twitter: A semantic network analysis. Telemat Inform 54: 101474. doi: 10.1016/j.tele.2020.101474
|
| [5] |
McNeill A, Harris PR, Briggs P (2016) Twitter influence on UK vaccination and antiviral uptake during the 2009 H1N1 pandemic. Front Public Health 4: 26. doi: 10.3389/fpubh.2016.00026
|
| [6] |
Borgmann H, Loeb S, Salem J, et al. (2016) Activity, content, contributors, and influencers of the twitter discussion on urologic oncology. Urol Oncol 34: 377-383. doi: 10.1016/j.urolonc.2016.02.021
|
| [7] |
Waszak PM, Kasprzycka-Waszak W, Kubanek A (2018) The spread of medical fake news in social media – The pilot quantitative study. Health Policy Technol 7: 115-118. doi: 10.1016/j.hlpt.2018.03.002
|
| [8] |
Yusuf S, Rangarajan S, Teo K, et al. (2014) Cardiovascular Risk and Events in 17 Low-, Middle-, and High-Income Countries. N Engl J Med 371: 818-827. doi: 10.1056/NEJMoa1311890
|
| [9] |
Xu WW, Chiu IH, Chen Y, et al. (2015) Twitter hashtags for health: applying network and content analyses to understand the health knowledge sharing in a Twitter-based community of practice. Qual Quant 49: 1361-1380. doi: 10.1007/s11135-014-0051-6
|
| [10] |
Park H, Reber BH, Chon MG (2016) Tweeting as Health Communication: Health Organizations' Use of Twitter for Health Promotion and Public Engagement. J Health Commun 21: 188-198. doi: 10.1080/10810730.2015.1058435
|
| [11] |
Bornmann L, Daniel HD (2005) Does the h-index for ranking of scientists really work? Scientometrics 65: 391-392. doi: 10.1007/s11192-005-0281-4
|
| [12] |
Chandawarkar AA, Gould DJ, Grant Stevens W (2018) The Top 100 Social Media Influencers in Plastic Surgery on Twitter: Who Should You Be Following? Aesthet Surg J 38: 913-917. doi: 10.1093/asj/sjy024
|
| [13] |
Varady NH, Chandawarkar AA, Kernkamp WA, et al. (2019) Who should you be following? The top 100 social media influencers in orthopaedic surgery. World J Orthop 10: 327-338. doi: 10.5312/wjo.v10.i9.327
|
| [14] |
Pulido CM, Villarejo-Carballido B, Redondo-Sama G, et al. (2020) COVID-19 infodemic: More retweets for science-based information on coronavirus than for false information. Int Sociol 35: 377-392. doi: 10.1177/0268580920914755
|
| [15] |
Chou WYS, Oh A, Klein WMP (2018) Addressing Health-Related Misinformation on Social Media. JAMA 320: 2417-2418. doi: 10.1001/jama.2018.16865
|
| [16] |
Mehta LS, Fisher K, Rzeszut AK, et al. (2019) Current Demographic Status of Cardiologists in the United States. JAMA Cardiol 4: 1029-1033. doi: 10.1001/jamacardio.2019.3247
|
| [17] |
Mehta LS, Fisher K, Rzeszut AK, et al. (2019) Current Demographic Status of Cardiologists in the United States. JAMA Cardiol 4: 1029-1033. doi: 10.1001/jamacardio.2019.3247
|
| [18] |
Panhwar MS, Kalra A (2019) Breaking Down the Hierarchy of Medicine. Eur Heart J 40: 1482-1483. doi: 10.1093/eurheartj/ehz264
|
| [19] | Aaltonen S, Kakderi C, Hausmann V, et al. (2013) Social media in Europe: Lessons from an online survey. Proceedings of the 18th UKAIS Conference Available from: http://usir.salford.ac.uk/id/eprint/28500/. |
| [20] |
Java A, Song X, Finin T, et al. (2007) Why we twitter: understanding microblogging usage and communities. Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 Workshop on Web Mining and Social Network Analysis - WebKDD/SNA-KDD '07 ACM Press, 56-65. doi: 10.1145/1348549.1348556
|
| [21] |
Moreno A, Navarro C, Tench R, et al. (2015) Does social media usage matter? An analysis of online practices and digital media perceptions of communication practitioners in Europe. Public Relat Rev 41: 242-253. doi: 10.1016/j.pubrev.2014.12.006
|
| [22] |
Bert F, Zeegers Paget D, Scaioli G (2016) A social way to experience a scientific event: Twitter use at the 7th European Public Health Conference. Scand J Public Health 44: 130-133. doi: 10.1177/1403494815612932
|
| [23] |
Hudson S, Mackenzie G (2019) ‘Not your daughter's Facebook’: Twitter use at the European Society of Cardiology Conference 2018. Heart 105: 169-170. doi: 10.1136/heartjnl-2018-314163
|
| [24] |
Uhl A, Kolleck N, Schiebel E (2017) Twitter data analysis as contribution to strategic foresight-The case of the EU Research Project “Foresight and Modelling for European Health Policy and Regulations” (FRESHER). Eur J Futur Res 5: 1. doi: 10.1007/s40309-016-0102-4
|
| [25] | Kapoor R, Sachdeva S, Zacks JS (2015) An Analysis of Global Research Trends in Cardiology Over the Last two Decades. J Clin Diagn Res JCDR 9: OC06-OC09. |
| [26] |
Tanoue MT, Chatterjee D, Nguyen HL, et al. (2018) Tweeting the Meeting: Rapid Growth in the Use of Social Media at Major Cardiovascular Scientific Sessions from 2014–2016. Circ Cardiovasc Qual Outcomes 11: e005018. doi: 10.1161/CIRCOUTCOMES.118.005018
|
| [27] |
Tanoue M, Nguyen H, Sekimura T, et al. (2018) To Tweet or Not to Tweet: Rapid Growth in the Use of Social Media at Major Cardiovascular Meetings. J Am Coll Cardiol 71: A2633. d. doi: 10.1016/S0735-1097(18)33174-7
|
| [28] | Lee G, Choi AD, Michos ED (2019) Social Media as a Means to Disseminate and Advocate Cardiovascular Research: Why, How, and Best Practices. Curr Cardiol Rev 15. |
| [29] |
Ladeiras-Lopes R, Clarke S, Vidal-Perez R, et al. (2020) Twitter promotion predicts citation rates of cardiovascular articles: a preliminary analysis from the ESC Journals Randomized Study. Eur Heart J 41: 3222-3225. doi: 10.1093/eurheartj/ehaa211
|
| [30] |
Bornmann L, Mutz R, Hug SE, et al. (2011) A multilevel meta-analysis of studies reporting correlations between the h index and 37 different h index variants. J Informetr 5: 346-359. doi: 10.1016/j.joi.2011.01.006
|

Figures(2) / Tables(2)

Onoriode Kesiena, Henry K Onyeaka, Setri Fugar, Alexis K Okoh, Annabelle Santos Volgman. The top 100 Twitter influencers in cardiology[J]. AIMS Public Health, 2021, 8(4): 743-753. doi: 10.3934/publichealth.2021058







 DownLoad:
DownLoad: