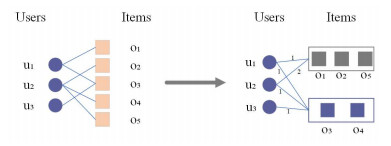
Collaborative filtering (CF) algorithm is one of the most widely used recommendation algorithms in recommender systems. However, there is a data sparsity problem in the traditional CF algorithm, which may reduce the recommended efficiency of recommender systems. This paper proposes an improved collaborative filtering personalized recommendation (ICF) algorithm, which can effectively improve the data sparsity problem by reducing item space. By using the k-means clustering method to secondarily extract the similarity information, ICF algorithm can obtain the similarity information of users more accurately, thus improving the accuracy of recommender systems. The experiments using MovieLens and Netflix data set show that the ICF algorithm has a significant improvement in the accuracy and quality of recommendation.
Citation: Jiaquan Huang, Zhen Jia, Peng Zuo. Improved collaborative filtering personalized recommendation algorithm based on k-means clustering and weighted similarity on the reduced item space[J]. Mathematical Modelling and Control, 2023, 3(1): 39-49. doi: 10.3934/mmc.2023004
Collaborative filtering (CF) algorithm is one of the most widely used recommendation algorithms in recommender systems. However, there is a data sparsity problem in the traditional CF algorithm, which may reduce the recommended efficiency of recommender systems. This paper proposes an improved collaborative filtering personalized recommendation (ICF) algorithm, which can effectively improve the data sparsity problem by reducing item space. By using the k-means clustering method to secondarily extract the similarity information, ICF algorithm can obtain the similarity information of users more accurately, thus improving the accuracy of recommender systems. The experiments using MovieLens and Netflix data set show that the ICF algorithm has a significant improvement in the accuracy and quality of recommendation.

| [1] |
Z. Zheng, X. Wu, Y. Zhang, M. R. Lyu, J. Wang, QoS ranking prediction for cloud services. IEEE T. parall. distr., 24 (2012), 1213–1222. https://doi:10.1109/TPDS.2012.285 doi: 10.1109/TPDS.2012.285

|
| [2] |
T. Liu, Z. He, A novel personalized recommendation algorithm by exploiting individual trust and item's similarities, Appl. Intell., 52 (2022), 6007–6021. https://doi.org/10.1007/s10489-021-02655-1 doi: 10.1007/s10489-021-02655-1
|
| [3] |
L. Lü, M. Medo, C. H. Yeung, Y. C. Zhang, Z. K. Zhang, T. Zhou, Recommender systems, Physics reports, 519 (2012), 1–49. https://doi.org/10.1016/j.physrep.2012.02.006 doi: 10.1016/j.physrep.2012.02.006
|
| [4] |
Z. H. Deng, Z. H. Wang, J. Zhang, ROBIN: A novel personal recommendation model based on information propagation, Expert syst. appl., 40 (2013), 5306–5313. https://doi.org/10.1016/j.eswa.2013.03.039 doi: 10.1016/j.eswa.2013.03.039
|
| [5] |
T, Zhou, J. Ren, M. Medo, Y. C. Zhang, Bipartite network projection and personal recommendation, Phys. rev. E, 76 (2007), 046115. https://doi.org/10.1103/PhysRevE.76.046115 doi: 10.1103/PhysRevE.76.046115
|
| [6] |
R. Goyal, S. J. Goyal, Recommender system: An analytical report on decision making for large scale online social networks, Materials Today: Proceedings, 47 (2021), 7145–7148. https://doi.org/10.1016/j.matpr.2021.06.311 doi: 10.1016/j.matpr.2021.06.311
|
| [7] |
I. Belkhadir, D. E. Omar, J. Boumhidi, An intelligent recommender system using social trust path for recommendations in web-based social networks, Procedia computer science, 148 (2019), 181–190. https://doi.org/10.1016/j.procs.2019.01.035 doi: 10.1016/j.procs.2019.01.035
|
| [8] |
G. Linden, B. Smith, J. York, Amazon. com recommendations: Item-to-item collaborative filtering, IEEE Internet comput., 7 (2003), 76–80. https://doi.org/10.1109/MIC.2003.1167344 doi: 10.1109/MIC.2003.1167344
|
| [9] |
S. Ding, C. Xia, C. Wang, D. Wu, Y. Zhang, Multi-objective optimization based ranking prediction for cloud service recommendation, Decis. Support Syst., 101 (2017), 106–114. https://doi:10.1016/j.dss.2017.06.00 doi: 10.1016/j.dss.2017.06.00
|
| [10] |
S. Yu, M. Yang, Q. Qu, Y. Shen, Contextual-boosted deep neural collaborative filtering model for interpretable recommendation, Expert Syst. Appl., 136 (2019), 365–375. https://doi.org/10.1016/j.eswa.2019.06.051 doi: 10.1016/j.eswa.2019.06.051
|
| [11] |
T. Mohammadpour, A. M. Bidgoli, R. Enayatifar, H. H. Javadi, Efficient clustering in collaborative filtering recommender system: Hybrid method based on genetic algorithm and gravitational emulation local search algorithm, Genomics, 111 (2019), 1902–1912. https://doi.org/10.1016/j.ygeno.2019.01.001 doi: 10.1016/j.ygeno.2019.01.001
|
| [12] |
T. M. Phuong, N. D. Phuong, Graph-based context-aware collaborative filtering, Expert Syst. Appl., 126 (2019), 9–19. https://doi.org/10.1016/j.eswa.2019.02.015 doi: 10.1016/j.eswa.2019.02.015
|
| [13] |
C. Feng, J. Liang, P. Song, Z. Wang, A fusion collaborative filtering method for sparse data in recommender systems, Inform. Sciences, 521 (2020), 365–379. https://doi.org/10.1016/j.ins.2020.02.052 doi: 10.1016/j.ins.2020.02.052
|
| [14] |
Y. Lv, Y. Zheng, F. Wei, C. Wang, C. Wang, AICF: Attention-based item collaborative filtering, Adv. Eng. Inform., 44 (2020), 101090. https://doi.org/10.1016/j.aei.2020.101090 doi: 10.1016/j.aei.2020.101090
|
| [15] |
A. Gazdar, L. Hidri, A new similarity measure for collaborative filtering based recommender systems, Knowledge-Based Systems, 188 (2020), 105058. https://doi.org/10.1016/j.knosys.2019.105058 doi: 10.1016/j.knosys.2019.105058
|
| [16] |
B. Alhijawi, G. Al-Naymat, N. Obeid, A. Awajan, Novel predictive model to improve the accuracy of collaborative filtering recommender systems, Inform. Syst., 96 (2020), 101670. https://doi.org/10.1016/j.is.2020.101670 doi: 10.1016/j.is.2020.101670
|
| [17] |
D. Sánchez-Moreno, A. B. G. González, M. D. M. Vicente, V. F. Batista, M. N. García, A collaborative filtering method for music recommendation using playing coefficients for artists and users, Expert Syst. Appl., 66 (2016), 234–244. https://doi.org/10.1016/j.eswa.2016.09.019 doi: 10.1016/j.eswa.2016.09.019
|
| [18] |
A. Hernando, J. Bobadilla, F. Ortega, A non negative matrix factorization for collaborative filtering recommender systems based on a Bayesian probabilistic model, Knowledge-Based Systems, 97 (2016), 188–202. https://doi.org/10.1016/j.knosys.2015.12.018 doi: 10.1016/j.knosys.2015.12.018
|
| [19] |
M. Singh, M. Mehrotra, Impact of biclustering on the performance of biclustering based collaborative filtering, Expert Syst. Appl., 113 (2018), 443–456. https://doi.org/10.1016/j.eswa.2018.06.001 doi: 10.1016/j.eswa.2018.06.001
|
| [20] |
S. Kant, T. Mahara, V. K. Jain, D. K. Jain, A. K. Sangaiah, LeaderRank based k-means clustering initialization method for collaborative filtering, Comput. Electr. Eng., 69 (2018), 598–609. https://doi.org/10.1016/j.compeleceng.2017.12.001 doi: 10.1016/j.compeleceng.2017.12.001
|
| [21] |
J. Chen, L. Wei, L. Zhang, Dynamic evolutionary clustering approach based on time weight and latent attributes for collaborative filtering recommendation, Chaos, Solitons & Fractals, 114 (2018), 8–18. https://doi.org/10.1016/j.chaos.2018.06.011 doi: 10.1016/j.chaos.2018.06.011
|
| [22] |
N. Vara, M. Mirzabeigi, H. Sotudeh, S. M. Fakhrahmad, Application of k-means clustering algorithm to improve effectiveness of the results recommended by journal recommender system, Scientometrics, 127 (2022), 3237–3252. https://doi.org/10.1007/s11192-022-04397-4 doi: 10.1007/s11192-022-04397-4
|
| [23] |
F. O. Isinkaye, Y. O. Folajimi, B. A. Ojokoh, Recommendation systems: Principles, methods and evaluation, Egypt. inform. j., 16 (2015), 261–273. https://doi.org/10.1016/j.eij.2015.06.005 doi: 10.1016/j.eij.2015.06.005
|
| [24] |
F. H. Del Olmo, E. Gaudioso, Evaluation of recommender systems: A new approach, Expert Syst. Appl., 35 (2008), 790–804. https://doi.org/10.1016/j.eswa.2007.07.047 doi: 10.1016/j.eswa.2007.07.047
|
| [25] |
M. Nilashi, O. Ibrahim, N. Ithnin, Hybrid recommendation approaches for multi-criteria collaborative filtering, Expert Syst. Appl., 41 (2014), 3879–3900. https://doi.org/10.1016/j.eswa.2013.12.023 doi: 10.1016/j.eswa.2013.12.023
|
| [26] |
R. Real, J. M. Vargas, The probabilistic basis of Jaccard's index of similarity. Syst. biol., 45 (1996), 380–385. https://doi.org/10.1093/sysbio/45.3.380 doi: 10.1093/sysbio/45.3.380
|



Figures(4) / Tables(2)
Jiaquan Huang, Zhen Jia, Peng Zuo. Improved collaborative filtering personalized recommendation algorithm based on k-means clustering and weighted similarity on the reduced item space[J]. Mathematical Modelling and Control, 2023, 3(1): 39-49. doi: 10.3934/mmc.2023004







 DownLoad:
DownLoad: