Citation: Maryam Gholamniya Foumani, Narges Sadeghi, Shadi Dehghanzadeh. Self-esteem and self-confidence relationship with religious tendency in families with a child suffering from cancer[J]. AIMS Medical Science, 2019, 6(3): 218-229. doi: 10.3934/medsci.2019.3.218

| [1] | Rahimi S, Fadakar Soghe R, Tabri R, et al. (2014) Related factors with quality of life among preschool children with cancer. J Holist Nurs Midwifery 24: 30–39. |
| [2] | Rezaei Z, Sharifian Sani M, Ostadhashemi L, et al. (2018) Quality of life of mothers of children with cancer in Iran. koomesh 20: 425–431. |
| [3] |
Peris-Bonet R, Salmerón D, Martínez-Beneito M, et al. (2010) Childhood cancer incidence and survival in Spain. Ann Oncol 21: iii103–iii110. doi: 10.1093/annonc/mdq207

|
| [4] |
White MC, Holman DM, Boehm JE, et al. (2014) Age and cancer risk: A potentially modifiable relationship. Am J Prev Med 46: S7–S15. doi: 10.1016/j.amepre.2013.10.029
|
| [5] | Ross JA, Olshan AF (2004) Pediatric cancer in the United States: The Children's Oncology Group Epidemiology Research Program. Cancer Epidemiol Biomarkers Prev 13: 1552–1554. |
| [6] |
Parkin DM, Stiller CA, Draper GJ, et al. (1988) The international incidence of childhood cancer. Int J Cancer 42: 511–520. doi: 10.1002/ijc.2910420408
|
| [7] | Sajjadi H, Roshanfekr P, Asangari B, et al. (2011) Quality of life and satisfaction with services in caregivers of children with cancer. Iran J Nurs 24: 8–17. |
| [8] | Mehranfar M, Younesi J, Banihashem A (2012) Effectiveness of mindfulness-based cognitive therapy on reduction of depression and anxiety symptoms in mothers of children with cancer. Iran J Cancer Prev 5: 1–9. |
| [9] |
Kendall S (2007) Witnessing tragedy: Nurses' perceptions of caring for patients with cancer. Int J Nurs Pract 13: 111–120. doi: 10.1111/j.1440-172X.2007.00615.x
|
| [10] |
McCarthy MC, Clarke NE, Vance A, et al. (2009) Measuring psychosocial risk in families caring for a child with cancer: The psychosocial assessment tool (PAT2. 0). Pediatr Blood Cancer 53: 78–83. doi: 10.1002/pbc.22007
|
| [11] | Allahbakhshian M, Jaffarpour M, Parvizy S, et al. (2010) A Survey on relationship between spiritual wellbeing and quality of life in multiple sclerosis patients. Zahedan J Res Med Sci 12: 29–33. |
| [12] |
Aghazadeh R, Zali MR, Bahari A, et al. (2005) Inflammatory bowel disease in Iran: A review of 457 cases. J Gastroenterol Hepatol 20: 1691–1695. doi: 10.1111/j.1440-1746.2005.03905.x
|
| [13] | Ganji T, Hosseini F (2008) Spirituality and anxiety in nursing students of faculty of nursing and midwifery Iran university of medical science-2006. Int J Ment Health Nurs 17: A8. |
| [14] |
MacDonald MA (2004) From miasma to fractals: the epidemiology revolution and public health nursing. Publ Health Nurs 21: 380–391. doi: 10.1111/j.0737-1209.2004.21412.x
|
| [15] | Reisi-Dehkordi N, Baratian H, Zargham-Boroujeni A (2014) Challenges of children with cancer and their mothers: A qualitative research. Iran J Nurs Midwifery Res 19: 334–339. |
| [16] | English T, Davis J, Wei M, et al. (2016) Homesickness and adjustment across the first year of college: A longitudinal study. Emotion 17: 1–5. |
| [17] | Mousavizadeh S, Torani S, Sohrabi F (2013) Female students becoming assertive as a way of increasing marital satisfaction. J Psychol Stud 9: 131–152. |
| [18] | Bordbar FT, Tabatabaie KR, Falah PA, et al. (2009) Effect of assertiveness training on homesickness in girls students. J Mazandaran Univ Med Sci 19: 28–33. |
| [19] |
Maleki M, Maleki F, Mirzayi S, et al. (2016) Investigating the modelling of psychological wellbeing according to self-expression and selfefficiency in high school students of Imam Khomeini Relief Committee. TOJDAC 6: 156–165. doi: 10.7456/1060ASE/016
|
| [20] | Omidi A, Akbari H, Jaddi-Arani T (2011) Efficacy of educational workshop on self-esteem of students at Kashan university of medical sciences. Feyz 15: 114–119. |
| [21] | Khoshnood G, Shayan N, Babaie AN, et al. (2016) Relationship between religious orientation, happiness, locus of control and coping strategies, and spiritual well-being among nursing students. J Res Dev Nurs Midwifery 12: 9–18. |
| [22] |
Li HW, Lopez V, Chung OJ, et al. (2013) The impact of cancer on the physical, psychological and social well-being of childhood cancer survivors. Eur J Oncol Nurs 17: 214–219. doi: 10.1016/j.ejon.2012.07.010
|
| [23] | Bahreini M, Mohammadi BM, Zare M, et al. (2005) Effect of assertiveness training on self-esteem on nursing students. Armaghane Danesh 10: 89–96. |
| [24] | Mardani HM, Heidari H (2011) The Effect of assertiveness on postpartum depression. Ann Mil Health Sci Res 8: 265–270. |
| [25] | Ranjbarkohn Z, Sajadinejad M (2010) Effect of assertiveness training on self-esteem and depression in students of Isfahan University of Medical Sciences. J Birjand Univ Med Sci 17: 308–315. |
| [26] | Pirbodaghi M, Rasouli M, Ilkhani M, et al. (2015) An investigation of factors associated adaptation of mothers to disease of child with cancer based on roy model testing. Qom Univ Med Sci J 9: 41–50. |
| [27] | Aghayani CA, Talebian D, Tarkhourani H, et al. (2008) Investigating the relationship of prayer with religious orientation and mental health. J Behav Sci 2: 149–156. |
| [28] | Bahrami EH, Tamanaefar S, Bahrami EZ (2005) The ralationship between dimensions of religious orientation, mental health and pyschological disorders. J Dev Psychol 2: 35–42. |
| [29] |
McNulty K, Livneh H, Wilson LM (2004) Perceived uncertainty, spiritual well-being, and psychosocial adaptation in individuals with multiple sclerosis. Rehabil Psychol 49: 91. doi: 10.1037/0090-5550.49.2.91
|
| [30] |
Vachon ML (2008) Meaning, spirituality, and wellness in cancer survivors. Semin Oncol Nurs 24: 218–225. doi: 10.1016/j.soncn.2008.05.010
|
| [31] | Yeganeh T (2013) Role of religious orientations in determination of hope and psychological well-being in female patients with breast cancer. Iran Q J Breast Dis 6: 47–56. |
| [32] |
Tremolada M, Bonichini S, Schiavo S, et al. (2012) Post-traumatic stress symptoms in mothers of children with leukaemia undergoing the first 12 months of therapy: predictive models. Psychology Health 27: 1448–1462. doi: 10.1080/08870446.2012.690414
|
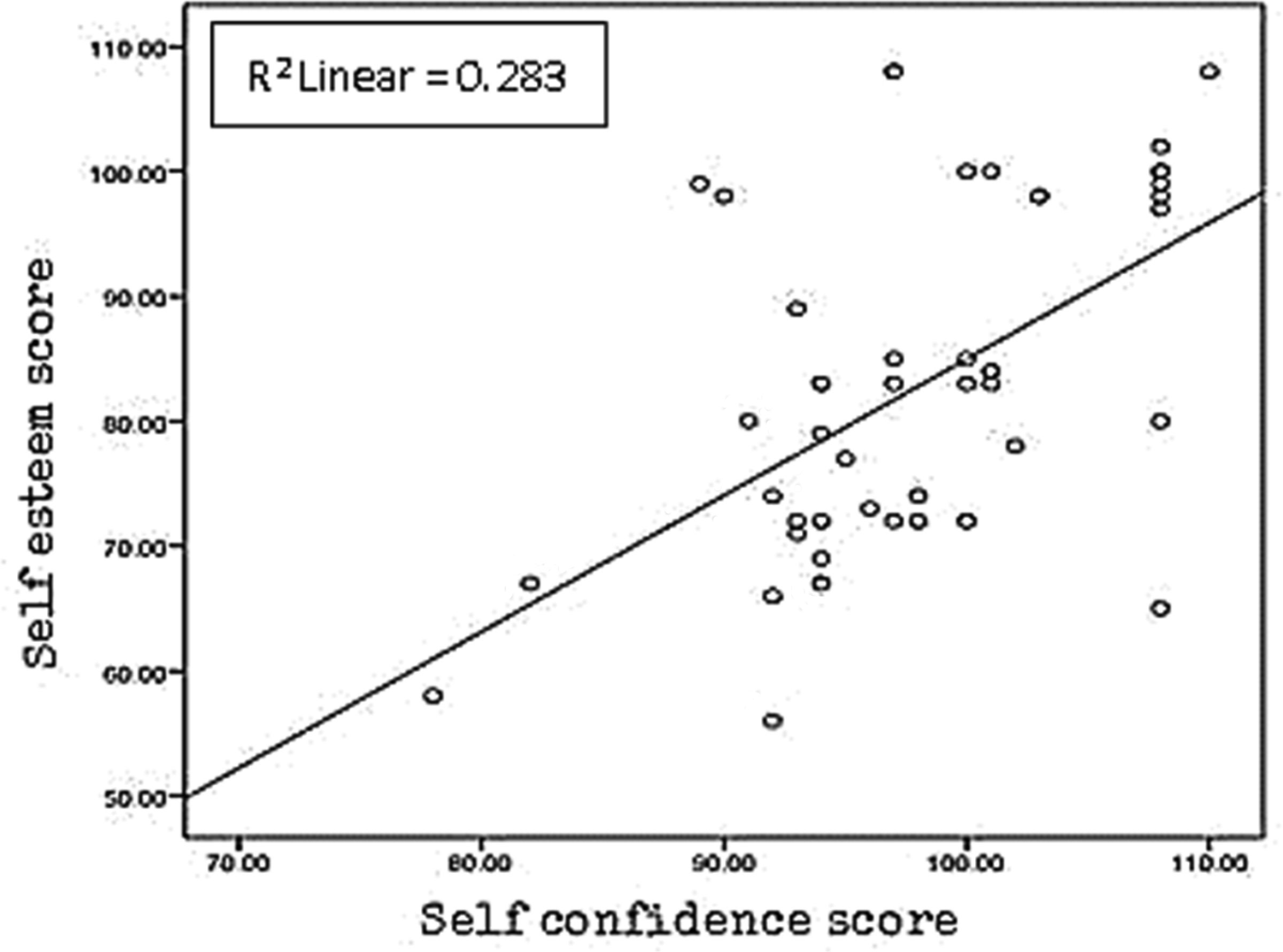
Figures(1) / Tables(5)

Maryam Gholamniya Foumani, Narges Sadeghi, Shadi Dehghanzadeh. Self-esteem and self-confidence relationship with religious tendency in families with a child suffering from cancer[J]. AIMS Medical Science, 2019, 6(3): 218-229. doi: 10.3934/medsci.2019.3.218







 DownLoad:
DownLoad: