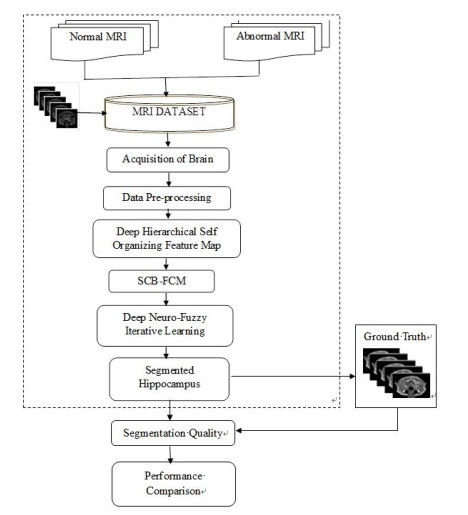
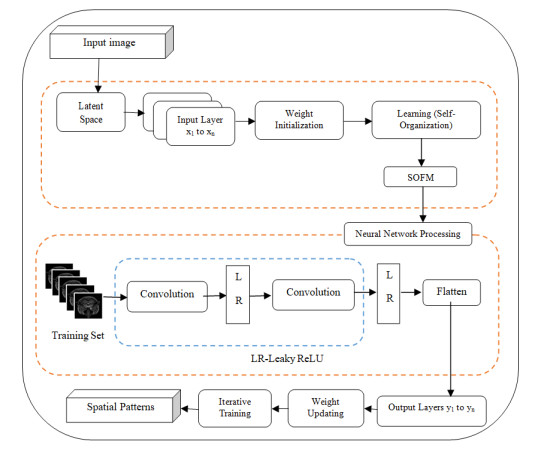
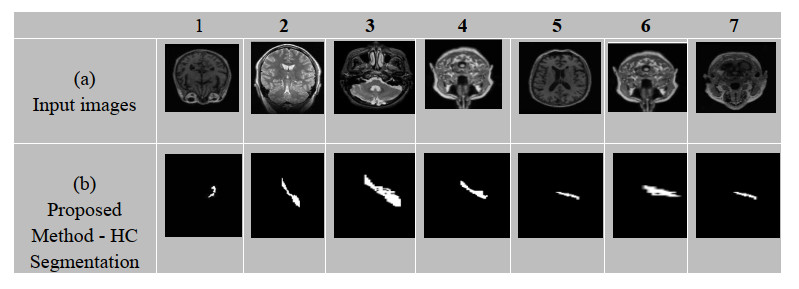
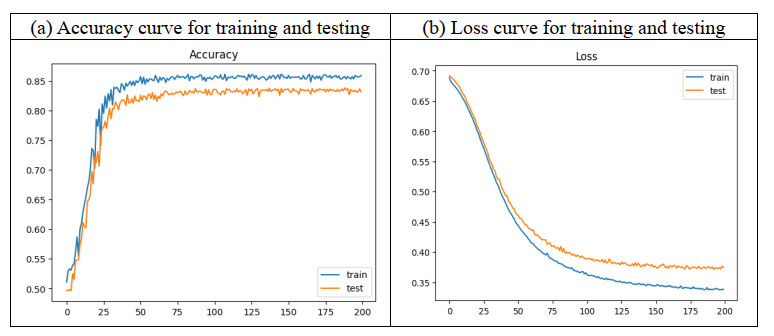
The hippocampus is a small, yet intricate seahorse-shaped tiny structure located deep within the brain's medial temporal lobe. It is a crucial component of the limbic system, which is responsible for regulating emotions, memory, and spatial navigation. This research focuses on automatic hippocampus segmentation from Magnetic Resonance (MR) images of a human head with high accuracy and fewer false positive and false negative rates. This segmentation technique is significantly faster than the manual segmentation methods used in clinics. Unlike the existing approaches such as UNet and Convolutional Neural Networks (CNN), the proposed algorithm generates an image that is similar to a real image by learning the distribution much more quickly by the semi-supervised iterative learning algorithm of the Deep Neuro-Fuzzy (DNF) technique. To assess its effectiveness, the proposed segmentation technique was evaluated on a large dataset of 18,900 images from Kaggle, and the results were compared with those of existing methods. Based on the analysis of results reported in the experimental section, the proposed scheme in the Semi-Supervised Deep Neuro-Fuzzy Iterative Learning System (SS-DNFIL) achieved a 0.97 Dice coefficient, a 0.93 Jaccard coefficient, a 0.95 sensitivity (true positive rate), a 0.97 specificity (true negative rate), a false positive value of 0.09 and a 0.08 false negative value when compared to existing approaches. Thus, the proposed segmentation techniques outperform the existing techniques and produce the desired result so that an accurate diagnosis is made at the earliest stage to save human lives and to increase their life span.
Citation: M Nisha, T Kannan, K Sivasankari. A semi-supervised deep neuro-fuzzy iterative learning system for automatic segmentation of hippocampus brain MRI[J]. Mathematical Biosciences and Engineering, 2024, 21(12): 7830-7853. doi: 10.3934/mbe.2024344
The hippocampus is a small, yet intricate seahorse-shaped tiny structure located deep within the brain's medial temporal lobe. It is a crucial component of the limbic system, which is responsible for regulating emotions, memory, and spatial navigation. This research focuses on automatic hippocampus segmentation from Magnetic Resonance (MR) images of a human head with high accuracy and fewer false positive and false negative rates. This segmentation technique is significantly faster than the manual segmentation methods used in clinics. Unlike the existing approaches such as UNet and Convolutional Neural Networks (CNN), the proposed algorithm generates an image that is similar to a real image by learning the distribution much more quickly by the semi-supervised iterative learning algorithm of the Deep Neuro-Fuzzy (DNF) technique. To assess its effectiveness, the proposed segmentation technique was evaluated on a large dataset of 18,900 images from Kaggle, and the results were compared with those of existing methods. Based on the analysis of results reported in the experimental section, the proposed scheme in the Semi-Supervised Deep Neuro-Fuzzy Iterative Learning System (SS-DNFIL) achieved a 0.97 Dice coefficient, a 0.93 Jaccard coefficient, a 0.95 sensitivity (true positive rate), a 0.97 specificity (true negative rate), a false positive value of 0.09 and a 0.08 false negative value when compared to existing approaches. Thus, the proposed segmentation techniques outperform the existing techniques and produce the desired result so that an accurate diagnosis is made at the earliest stage to save human lives and to increase their life span.

| [1] |
A. Obenaus, C. J. Yong-Hing, K. A. Tong, G. E. Sarty, A reliable method for measurement and normalization of pediatric hippocampal volumes, J. Pediatr. Res., 50 (2001), 124–132. https://doi.org/10.1203/00006450-200107000-00022 doi: 10.1203/00006450-200107000-00022

|
| [2] |
D. Shen, S. Moffat, S. M. Resnick, C. Davatzikos, Measuring size and shape of the hippocampus in MR images using a deformable shape model, Neuroimage, 15 (2002), 422–434. https://doi.org/10.1006/nimg.2001.0987 doi: 10.1006/nimg.2001.0987
|
| [3] |
S. Li, F. Shi, F. Pu, X. Li, T. Jiang, S. Xie, Hippocampal shape analysis of Alzheimer disease based on machine learning methods, J. Neuroradiol., 28 (2007), 1339–1345. https://doi.org/10.3174/ajnr.A0620 doi: 10.3174/ajnr.A0620
|
| [4] |
J. H. Morra, Z. Tu, L. G. Apostolova, A. E. Green, A. W. Toga, P. M. Thompson, Comparison of AdaBoost and support vector machines for detecting Alzheimer's disease through automated hippocampal segmentation, IEEE Trans. Med. Imaging, 29 (2010), 30–43. https://doi.org/10.1109/TMI.2009.2021941 doi: 10.1109/TMI.2009.2021941
|
| [5] |
H. Wang, J. W. Suh, S. R. Das, J. B. Pluta, C. Craige; P. A. Yushkevich, Multi-atlas segmentation with joint label fusion, IEEE Trans. Pattern Anal. Mach. Intell., 35 (2012), 611–623. https://doi.org/10.1109/TPAMI.2012.143 doi: 10.1109/TPAMI.2012.143
|
| [6] |
M. Kim, G. Wu, D. Shen, Unsupervised deep learning for hippocampus segmentation in 7.0 Tesla MR images, Int. Workshop Mach. Learn. Med. Imaging, (2013), 1–8. https://doi.org/10.1007/978-3-319-02267-3_1 doi: 10.1007/978-3-319-02267-3_1
|
| [7] |
J. Kim, M. C. Valdes-Hernandez, N. A. Royle, J. Park, Hippocampal shape modeling based on a progressive template surface deformation and its verification, IEEE Trans. Med. Imaging, 34 (2015), 1242–1261. https://doi.org/10.1109/TMI.2014.2382581 doi: 10.1109/TMI.2014.2382581
|
| [8] |
D. Zarpalas, P. Gkontra, P. Daras, N. Maglaveras, Accurate and fully automatic hippocampus segmentation using subject-specific 3D optimal local maps into a hybrid active contour model, IEEE J. Transl. Eng. Health Med., 2 (2016), 1–16. https://doi.org/10.1109/JTEHM.2014.2297953 doi: 10.1109/JTEHM.2014.2297953
|
| [9] |
S. Sri Devi, A. Mano, R. Asha, MRI brain tumor segmentation and feature extraction using GLCM, Int. J. Res. Appl. Sci. Eng. Technol., 6 (2018), 1911–1916. https://doi.org/10.22214/ijraset.2018.1297 doi: 10.22214/ijraset.2018.1297
|
| [10] |
V. Dill, P. C. Klein, A. R. Franco, M. S. Pinho, Atlas selection for hippocampus segmentation: Relevance evaluation of three meta-information parameters, J. Comput. Biol. Med., 95 (2018), 90–98. https://doi.org/10.1016/j.compbiomed.2018.02.005 doi: 10.1016/j.compbiomed.2018.02.005
|
| [11] |
N. Varuna Shree, T. N. R. Kumar, Identification and classification of brain tumor MRI images with feature extraction using DWT and probabilistic neural network, Brain Inform., 5 (2018), 23–30. https://doi.org/10.1007/s40708-017-0075-5 doi: 10.1007/s40708-017-0075-5
|
| [12] |
E. Gibson, W. Li, C. Sudre, L. Fidon, D. I. Shakir, G. Wang, et al., NiftyNet: a deep-learning platform for medical imaging, Comput. Methods Programs Biomed., 158 (2018), 113–122. https://doi.org/10.1016/j.cmpb.2018.01.025 doi: 10.1016/j.cmpb.2018.01.025
|
| [13] |
Y. Shao, J. Kim, Y. Gao, Q. Wang, W. Lin, D. Shen, Hippocampal segmentation from longitudinal infant brain MR images via classification-guided boundary regression, IEEE Access, 7 (2019), 33728–33740. https://doi.org/10.1109/ACCESS.2019.2904143 doi: 10.1109/ACCESS.2019.2904143
|
| [14] |
A. Basher, K. Y. Choi, J. J. Lee, B. Lee, B. C. Kim, K. H. Lee, et al., Hippocampus localization using a two-stage ensemble Hough convolutional neural network, IEEE Access, 7 (2019), 73436–73447. https://doi.org/10.1109/ACCESS.2019.2920005 doi: 10.1109/ACCESS.2019.2920005
|
| [15] |
S. Liu, Y. Wang, X. Yang, B. Lei, L. Liu, S. X. Li, Deep learning in medical ultrasound analysis: a review, Engineering, 5 (2019), 261–275. https://doi.org/10.1016/j.eng.2018.11.020 doi: 10.1016/j.eng.2018.11.020
|
| [16] |
A. Gumaei, M. M. Hassan, M. R. Hassan, A. Alelaiwi, G. Fortino, A hybrid feature extraction method with regularized extreme learning machine for brain tumor classification, IEEE Access, 7 (2019), 36266–36273. https://doi.org/10.1109/ACCESS.2019.2904145 doi: 10.1109/ACCESS.2019.2904145
|
| [17] |
Y. Shi, K. Cheng, Z. Liu, Hippocampal subfields segmentation in brain MR images using generative adversarial networks, Biomed. Eng. Online, 18 (2019), 1–12. https://doi.org/10.1186/s12938-019-0623-8 doi: 10.1186/s12938-019-0623-8
|
| [18] |
A. S. Lundervold, A. Lundervold, An overview of deep learning in medical imaging focusing on MRI, J. Med. Phys., 29 (2019), 102–127. https://doi.org/10.1016/j.zemedi.2018.11.002 doi: 10.1016/j.zemedi.2018.11.002
|
| [19] | S. M. Nisha, A novel computer-aided diagnosis scheme for breast tumor classification, Int. Res. J. Eng. Technol., 7 (2020), 718–724. |
| [20] |
N. Safavian, S. A. H. Batouli, M. A. Oghabian, An automatic level set method for hippocampus segmentation in MR images, Comput. Methods Biomech. Biomed. Eng. Imaging Vis., 8 (2020), 400–410. https://doi.org/10.1080/21681163.2019.1706054 doi: 10.1080/21681163.2019.1706054
|
| [21] |
M. Liu, F. Li, H. Yan, K. Wang, Y. Ma, L. Shen, et al., A multi-model deep convolutional neural network for automatic hippocampus segmentation and classification in Alzheimer's disease, Neuroimage, 208 (2020), 116459. https://doi.org/10.1016/j.neuroimage.2019.116459 doi: 10.1016/j.neuroimage.2019.116459
|
| [22] |
M. K. Singh, K. K. Singh, A review of publicly available automatic brain segmentation methodologies, machine learning models, recent advancements, and their comparison, Ann. Neurosci., 28 (2021), 82–93. https://doi.org/10.1177/0972753121990 doi: 10.1177/0972753121990
|
| [23] |
L. Liu, L. Kuang, Y. Ji, Multimodal MRI brain tumor image segmentation using sparse subspace clustering algorithm, Comput. Math. Methods Med., (2020), 8620403. https://doi.org/10.1155/2020/8620403 doi: 10.1155/2020/8620403
|
| [24] |
D. Carmo, B. Silva, C. Yasuda, L. Rittner, R. Lotufo, Hippocampus segmentation on epilepsy and Alzheimer's disease studies with multiple convolutional neural networks, Heliyon, 7 (2021), e06226. https://doi.org/10.1016/j.heliyon.2021.e06226 doi: 10.1016/j.heliyon.2021.e06226
|
| [25] |
R. De Feo, E. Hämäläinen, E. Manninen, R. Immonen, J. M. Valverde, X. E. Ndode-Ekane, et al., Convolutional neural networks enable robust automatic segmentation of the rat hippocampus in mri after traumatic brain injury, Front. Neurol., 13 (2022), 820267. https://doi.org/10.3389/fneur.2022.820267 doi: 10.3389/fneur.2022.820267
|
| [26] |
M. Nisha, T. Kannan, K. Sivasankari, M. Sabrigiriraj, Automatic hippocampus segmentation model for MRI of human head through semi-supervised generative adversarial networks, Neuroquantology, 20 (2022), 5222–5232. https://doi.org/10.14704/nq.2022.20.6.NQ22528 doi: 10.14704/nq.2022.20.6.NQ22528
|
| [27] |
K. S. Chuang, H. L. Tzeng, S. Chen, J. Wu, T. J. Chen, Fuzzy c-means clustering with spatial information for image segmentation, Comput. Med. Imaging Graph., 30 (2006), 9–15. https://doi.org/10.1016/j.compmedimag.2005.10.001 doi: 10.1016/j.compmedimag.2005.10.001
|
| [28] |
B. N. Li, C. K. Chui, S. Chang, S. H. Ong, Integrating spatial fuzzy clustering with level set methods for automated medical image segmentation, Comput. Biol. Med., 41 (2011), 1–10. https://doi.org/10.1016/j.compbiomed.2010.10.007 doi: 10.1016/j.compbiomed.2010.10.007
|
| [29] |
C. Militello, L. Rundo, M. Dimarco, A. Orlando, V. Conti, R. Woitek, et al., Semi-automated and interactive segmentation of contrast-enhancing masses on breast DCE-MRI using spatial fuzzy clustering, Biomed. Signal Process. Control, 71 (2022), 103113. https://doi.org/10.1016/j.bspc.2021.103113 doi: 10.1016/j.bspc.2021.103113
|
| [30] | Z. Zhou, M. M. R. Siddiquee, N. Tajbakhsh, J. Liang, U-Net++: A nested U-Net architecture for medical image segmentation, in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Springer, (2018), 3–11. https://doi.org/10.1007/978-3-030-00889-5_1 |
| [31] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [32] | G. Huang, Z. Liu, L. Van Der Maaten., K. Q. Weinberger, Densely connected convolutional networks, in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., (2017), 4700–4708. https://doi.org/10.1109/CVPR.2017.243 |
| [33] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in Proc. IEEE/CVF Int. Conf. Comput. Vis., (2021), 10012–10022. https://doi.org/10.1109/ICCV48922.2021.00986 |
| [34] | J. Hu, L. Shen, G. Sun, Squeeze-and-Excitation networks, in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., (2018), 7132–7141. https://doi.org/10.48550/arXiv.1709.01507 |
| [35] |
J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, et al., Deep high-resolution representation learning for visual recognition, IEEE Trans. Pattern Anal. Mach. Intell., 43 (2020), 3349–3364. https://doi.org/10.1109/TPAMI.2020.2983686 doi: 10.1109/TPAMI.2020.2983686
|
| [36] |
Z. Szentimrey, A. Al‐Hayali, S. de Ribaupierre, A. Fenster, E. Ukwatta, Semi‐supervised learning framework with shape encoding for neonatal ventricular segmentation from 3D ultrasound, Med. Phys., 2024. https://doi.org/10.1002/mp.17242 doi: 10.1002/mp.17242
|
| [37] | Z. Wang, C. Ma, Dual-contrastive dual-consistency dual-transformer: A semi-supervised approach to medical image segmentation, in Proc. 2023 IEEE/CVF Int. Conf. Comput. Vis. Workshops, (2023), 870–879. https://doi.org/10.1109/ICCVW60793.2023.00094 |
| [38] |
L. Huang, S. Ruan, T. Denœux, Semi-supervised multiple evidence fusion for brain tumor segmentation, Neurocomputing, 535 (2023), 40–52. https://doi.org/10.1016/j.neucom.2023.02.047 doi: 10.1016/j.neucom.2023.02.047
|
| [39] | Z. Wang, I. Voiculescu, Exigent examiner and mean teacher: An advanced 3d cnn-based semi-supervised brain tumor segmentation framework, in Med. Image Learn. Limited Noisy Data: 2nd Int. Workshop MILLanD 2023, (2023), 181–190. https://doi.org/10.1007/978-3-031-44917-8_17 |
| [40] |
G. Qu, B. Lu, J. Shi, Z. Wang, Y. Yuan, Y. Xia, et al., Motion-artifact-augmented pseudo-label network for semi-supervised brain tumor segmentation, Phys. Med. Biol., 69 (2024), 5. https://doi.org/10.1088/1361-6560/ad2634 doi: 10.1088/1361-6560/ad2634
|
| [41] |
R. A. Hazarika, A. K. Maji, R. Syiem, S. N. Sur, D. Kandar, Hippocampus segmentation using U-net convolutional network from brain magnetic resonance imaging (MRI), J. Digit. Imaging, 35 (2022), 893–909. https://doi.org/10.1007/s10278-022-00613-y doi: 10.1007/s10278-022-00613-y
|
| [42] |
D. Ataloglou, A. Dimou, D. Zarpalas, P. Daras, Fast and precise hippocampus segmentation through deep convolutional neural network ensembles and transfer learning, Neuroinformatics, 17 (2019), 563–582. https://doi.org/10.1007/s12021-019-09417-y doi: 10.1007/s12021-019-09417-y
|
| [43] |
M. Nisha, T. Kannan, K. Sivasankari, Deep integration model: A robust autonomous segmentation technique for hippocampus in MRI images of human head, Int. J. Health Sci., 6 (2022), 13745–13758. https://doi.org/10.53730/ijhs.v6nS2.8756 doi: 10.53730/ijhs.v6nS2.8756
|
| [44] | N. Allinson, H. Yin, L. Allinson, J. Slack, Advances in Self-Organising Maps, Springer, 2001. https://doi.org/10.1007/978-1-4471-0715-6. |
| [45] | S. N. Sivanandam, S. Sumathi, S. N. Deepa, Applications of Fuzzy Logic: Introduction to Fuzzy Logic Using MATLAB, Springer, 2007. https://doi.org/10.1007/978-3-540-35781-0_8 |
| [46] |
V. Conti, C. Militello, L. Rundo, S. Vitabile, A novel bio-inspired approach for high-performance management in service-oriented networks, IEEE Trans. Emerg. Top. Comput., 9 (2021), 1709–1722. https://doi.org/10.1109/TETC.2020.3018312 doi: 10.1109/TETC.2020.3018312
|
Figures(4) / Tables(4)

M Nisha, T Kannan, K Sivasankari. A semi-supervised deep neuro-fuzzy iterative learning system for automatic segmentation of hippocampus brain MRI[J]. Mathematical Biosciences and Engineering, 2024, 21(12): 7830-7853. doi: 10.3934/mbe.2024344







 DownLoad:
DownLoad: