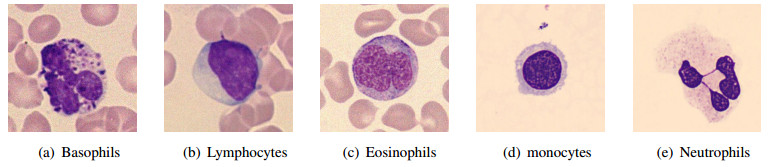
An automatic recognizing system of white blood cells can assist hematologists in the diagnosis of many diseases, where accuracy and efficiency are paramount for computer-based systems. In this paper, we presented a new image processing system to recognize the five types of white blood cells in peripheral blood with marked improvement in efficiency when juxtaposed against mainstream methods. The prevailing deep learning segmentation solutions often utilize millions of parameters to extract high-level image features and neglect the incorporation of prior domain knowledge, which consequently consumes substantial computational resources and increases the risk of overfitting, especially when limited medical image samples are available for training. To address these challenges, we proposed a novel memory-efficient strategy that exploits graph structures derived from the images. Specifically, we introduced a lightweight superpixel-based graph neural network (GNN) and broke new ground by introducing superpixel metric learning to segment nucleus and cytoplasm. Remarkably, our proposed segmentation model superpixel metric graph neural network (SMGNN) achieved state of the art segmentation performance while utilizing at most 10000$ \times $ less than the parameters compared to existing approaches. The subsequent segmentation-based cell type classification processes showed satisfactory results that such automatic recognizing algorithms are accurate and efficient to execeute in hematological laboratories. Our code is publicly available at https://github.com/jyh6681/SPXL-GNN.
Citation: Yuanhong Jiang, Yiqing Shen, Yuguang Wang, Qiaoqiao Ding. Automatic recognition of white blood cell images with memory efficient superpixel metric GNN: SMGNN[J]. Mathematical Biosciences and Engineering, 2024, 21(2): 2163-2188. doi: 10.3934/mbe.2024095
An automatic recognizing system of white blood cells can assist hematologists in the diagnosis of many diseases, where accuracy and efficiency are paramount for computer-based systems. In this paper, we presented a new image processing system to recognize the five types of white blood cells in peripheral blood with marked improvement in efficiency when juxtaposed against mainstream methods. The prevailing deep learning segmentation solutions often utilize millions of parameters to extract high-level image features and neglect the incorporation of prior domain knowledge, which consequently consumes substantial computational resources and increases the risk of overfitting, especially when limited medical image samples are available for training. To address these challenges, we proposed a novel memory-efficient strategy that exploits graph structures derived from the images. Specifically, we introduced a lightweight superpixel-based graph neural network (GNN) and broke new ground by introducing superpixel metric learning to segment nucleus and cytoplasm. Remarkably, our proposed segmentation model superpixel metric graph neural network (SMGNN) achieved state of the art segmentation performance while utilizing at most 10000$ \times $ less than the parameters compared to existing approaches. The subsequent segmentation-based cell type classification processes showed satisfactory results that such automatic recognizing algorithms are accurate and efficient to execeute in hematological laboratories. Our code is publicly available at https://github.com/jyh6681/SPXL-GNN.

| [1] | H. Mohamed, R. Omar, N. Saeed, A. Essam, N. Ayman, T. Mohiy, et al., Automated detection of white blood cells cancer diseases, in 2018 First International Workshop on Deep and Representation Learning (IWDRL), (2018), 48–54. https://doi.org/10.1109/IWDRL.2018.8358214 |
| [2] |
M. S. Kruskall, T. H. Lee, S. F. Assmann, M. Laycock, L. A. Kalish, M. M. Lederman, et al., Survival of transfused donor white blood cells in hiv-infected recipients, Blood J. Am. Soc. Hematol., 98 (2001), 272–279. https://doi.org/10.1182/blood.V98.2.272 doi: 10.1182/blood.V98.2.272

|
| [3] |
F. Xing, L. Yang, Robust nucleus/cell detection and segmentation in digital pathology and microscopy images: a comprehensive review, IEEE Rev. Biomed. Eng., 9 (2016), 234–263. https://doi.org/10.1109/RBME.2016.2515127 doi: 10.1109/RBME.2016.2515127
|
| [4] |
X. Zheng, Y. Wang, G. Wang, J. Liu, Fast and robust segmentation of white blood cell images by self-supervised learning, Micron, 107 (2018), 55–71. https://doi.org/10.1016/j.micron.2018.01.010 doi: 10.1016/j.micron.2018.01.010
|
| [5] |
Z. Zhu, S. H. Wang, Y. D. Zhang, Rernet: A deep learning network for classifying blood cells, Technol. Cancer Res. Treatment, 22 (2023), 15330338231165856. https://doi.org/10.1177/15330338231165856 doi: 10.1177/15330338231165856
|
| [6] |
Z. Zhu, Z. Ren, S. Lu, S. Wang, Y. Zhang, Dlbcnet: A deep learning network for classifying blood cells, Big Data Cognit. Comput., 7 (2023), 75. https://doi.org/10.3390/bdcc7020075 doi: 10.3390/bdcc7020075
|
| [7] |
C. Cheuque, M. Querales, R. León, R. Salas, R. Torres, An efficient multi-level convolutional neural network approach for white blood cells classification, Diagnostics, 12 (2022), 248. https://doi.org/10.3390/diagnostics12020248 doi: 10.3390/diagnostics12020248
|
| [8] |
Y. Zhou, Y. Wu, Z. Wang, B. Wei, M. Lai, J. Shou, et al., Cyclic learning: Bridging image-level labels and nuclei instance segmentation, IEEE Trans. Med. Imaging, 42 (2023), 3104–3116. https://doi.org/10.1109/TMI.2023.3275609 doi: 10.1109/TMI.2023.3275609
|
| [9] | Z. Gao, J. Shi, X. Zhang, Y. Li, H. Zhang, J. Wu, et al., Nuclei grading of clear cell renal cell carcinoma in histopathological image by composite high-resolution network, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2021), 132–142. https://doi.org/10.1007/978-3-030-87237-3_13 |
| [10] |
X. Liu, L. Song, S. Liu, Y. Zhang, A review of deep-learning-based medical image segmentation methods, Sustainability, 13 (2021), 1224. https://doi.org/10.3390/su13031224 doi: 10.3390/su13031224
|
| [11] | O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |
| [12] | F. Falck, C. Williams, D. Danks, G. Deligiannidis, C. Yau, C. Holmes, et al., A multi-resolution framework for U-Nets with applications to hierarchical VAEs, Adv. Neural Inf. Process. Syst., 35 (2022), 15529–15544. |
| [13] | Z. Zhou, M. Rahman Siddiquee, N. Tajbakhsh, J. Liang, Unet++: A nested u-net architecture for medical image segmentation, in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, (2018), 3–11. https://doi.org/10.1007/978-3-030-00889-5_1 |
| [14] | H. Huang, L. Lin, R. Tong, H. Hu, Q. Zhang, Y. Iwamoto, et al., Unet 3+: A full-scale connected unet for medical image segmentation, in IEEE International Conference on Acoustics, Speech and Signal Processing, (2020), 1055–1059. https://doi.org/10.1109/icassp40776.2020.9053405 |
| [15] | F. Jia, J. Liu, X. Tai, A regularized convolutional neural network for semantic image segmentation, Anal. Appl., 19 (01), 147–165. https://doi.org/10.1142/s0219530519410148 |
| [16] |
N. Akram, S. Adnan, M. Asif, S. Imran, M. Yasir, R. Naqvi, et al., Exploiting the multiscale information fusion capabilities for aiding the leukemia diagnosis through white blood cells segmentation, IEEE Access, 10 (2022), 48747–48760. https://doi.org/10.1109/access.2022.3171916 doi: 10.1109/access.2022.3171916
|
| [17] | A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, et al., An image is worth 16x16 words: Transformers for image recognition at scale, in International Conference on Learning Representations, 2021. |
| [18] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in Proceedings of the IEEE International Conference on Computer Vision, (2021), 10012–10022. https://doi.org/10.1109/iccv48922.2021.00986 |
| [19] | C. Nicolas, M. Francisco, G. Synnaeve, N. Usunier, A. Kirillov, S. Zagoruyko, End-to-end object detection with transformers, in European Conference on Computer Vision, (2020), 213–229. |
| [20] | O. Petit, N. Thome, C. Rambour, L. Themyr, T. Collins, L. Soler, U-net transformer: Self and cross attention for medical image segmentation, in International Workshop on Machine Learning in Medical Imaging, (2021), 267–276. https://doi.org/10.1007/978-3-030-87589-3_28 |
| [21] | J. Valanarasu, P. Oza, I. Hacihaliloglu, V. Patel, Medical transformer: Gated axial-attention for medical image segmentation, in Medical Image Computing and Computer Assisted Intervention, (2021), 36–46. https://doi.org/10.1007/978-3-030-87193-2_4 |
| [22] | H. Cao, Y. Wang, J. Chen, D. Jiang, X. Zhang, Q. Tian, et al., Swin-unet: Unet-like pure transformer for medical image segmentation, in Proceedings of European Conference on Computer Vision Workshops, 3 (2023), 205–218. https://doi.org/10.1007/978-3-031-25066-8_9 |
| [23] |
Z. Chi, Z. Wang, M. Yang, D. Li, W. Du, Learning to capture the query distribution for few-shot learning, IEEE Trans. Circuits Syst. Video Technol., 32 (2021), 4163–4173. https://doi.org/10.1109/tcsvt.2021.3125129 doi: 10.1109/tcsvt.2021.3125129
|
| [24] |
G. Li, S. Masuda, D. Yamaguchi, M. Nagai, The optimal gnn-pid control system using particle swarm optimization algorithm, Int. J. Innovative Comput. Inf. Control, 5 (2009), 3457–3469. https://doi.org/10.1109/GSIS.2009.5408225 doi: 10.1109/GSIS.2009.5408225
|
| [25] | Y. Wang, K. Yi, X. Liu, Y. Wang, S. Jin, Acmp: Allen-cahn message passing with attractive and repulsive forces for graph neural networks, in International Conference on Learning Representations, 2022. |
| [26] |
S. Min, Z. Gao, J. Peng, L. Wang, K. Qin, B. Fang, Stgsn—a spatial–temporal graph neural network framework for time-evolving social networks, Knowl. Based Syst., 214 (2021), 106746. https://doi.org/10.1016/j.knosys.2021.106746 doi: 10.1016/j.knosys.2021.106746
|
| [27] | B. Bumgardner, F. Tanvir, K. Saifuddin, E. Akbas, Drug-drug interaction prediction: a purely smiles based approach, in IEEE International Conference on Big Data, (2021), 5571–5579. https://doi.org/10.1109/bigdata52589.2021.9671766 |
| [28] | J. Bruna, W. Zaremba, A. Szlam, Y. LeCun, Spectral networks and locally connected networks on graphs, in International Conference on Learning Representations, 2014. |
| [29] | M. Defferrard, X. Bresson, P. Vandergheynst, Convolutional neural networks on graphs with fast localized spectral filtering, Adv. Neural Inf. Process. Syst., 29 (2016). |
| [30] | T. Kipf, M. Welling, Semi-supervised classification with graph convolutional networks, International Conference on Learning Representations, 2017. |
| [31] | P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Liò, Y. Bengio, Graph attention networks, in International Conference on Learning Representations, 2018. |
| [32] | K. Xu, W. Hu, J. Leskovec, S. Jegelka, How powerful are graph neural networks?, preprint, arXiv: 1810.00826. |
| [33] | Y. Lu, Y. Chen, D. Zhao, J. Chen, Graph-FCN for image semantic segmentation, in International Symposium on Neural Networks, 2019. |
| [34] | L. Zhang, X. Li, A. Arnab, K. Yang, Y. Tong, P. Torr, et al., Dual graph convolutional network for semantic segmentation, in British Machine Vision Conference, 2019. |
| [35] | Y. Jiang, Q. Ding, Y. G. Wang, P. Liò, X.Zhang, Vision graph u-net: Geometric learning enhanced encoder for medical image segmentation and restoration, Inverse Prob. Imaging, 2023 (2023). https://doi.org/10.3934/ipi.2023049 |
| [36] |
Z. Tian, L. Liu, Z. Zhang, B. Fei, Superpixel-based segmentation for 3d prostate mr images, IEEE Trans. Med. Imaging, 35 (2015), 791–801. https://doi.org/10.1109/tmi.2015.2496296 doi: 10.1109/tmi.2015.2496296
|
| [37] | F. Monti, D. Boscaini, J. Masci, E. Rodola, J. Svoboda, M. Bronstein, Geometric deep learning on graphs and manifolds using mixture model cnns, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 5115–5124. https://doi.org/10.1109/cvpr.2017.576 |
| [38] | R. Gadde, V. Jampani, M. Kiefel, D. Kappler, P. Gehler, Superpixel convolutional networks using bilateral inceptions, in Proceedings of the European Conference on Computer Vision, (2016). https://doi.org/10.1007/978-3-319-46448-0_36 |
| [39] | P. Avelar, A. Tavares, T. Silveira, C. Jung, L. Lamb, Superpixel image classification with graph attention networks, in SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), (2020), 203–209. https://doi.org/10.1109/sibgrapi51738.2020.00035 |
| [40] |
W. Zhao, L. Jiao, W. Ma, J. Zhao, J. Zhao, H. Liu, et al, . Superpixel-based multiple local cnn for panchromatic and multispectral image classification, IEEE Trans. Geosci. Remote Sens., 55 (2017), 4141–4156. https://doi.org/10.1109/tgrs.2017.2689018 doi: 10.1109/tgrs.2017.2689018
|
| [41] |
B. Cui, X. Xie, X. Ma, G. Ren, Y. Ma, Superpixel-based extended random walker for hyperspectral image classification, IEEE Trans. Geosci. Remote Sens., 56 (2018), 3233–3243. https://doi.org/10.1109/tgrs.2018.2796069 doi: 10.1109/tgrs.2018.2796069
|
| [42] |
S. Zhang, S. Li, W. Fu, L. Fang, Multiscale superpixel-based sparse representation for hyperspectral image classification, Remote Sens., 9 (2017), 139. https://doi.org/10.3390/rs9020139 doi: 10.3390/rs9020139
|
| [43] |
Q. Liu, L. Xiao, J. Yang, Z. Wei, Cnn-enhanced graph convolutional network with pixel-and superpixel-level feature fusion for hyperspectral image classification, IEEE Trans. Geosci. Remote Sens., 59 (2020), 8657–8671. https://doi.org/10.1109/tgrs.2020.3037361 doi: 10.1109/tgrs.2020.3037361
|
| [44] |
P. Felzenszwalb, D. Huttenlocher, Efficient graph-based image segmentation, Int. J. Comput. Vision, 59 (2010), 167–181. https://doi.org/10.1109/icip.2010.5653963 doi: 10.1109/icip.2010.5653963
|
| [45] |
X. Ren, J. Malik, Learning a classification model for segmentation, Proceedings of the IEEE International Conference on Computer Vision, 2 (2003), 10–10. https://doi.org/10.1109/iccv.2003.1238308 doi: 10.1109/iccv.2003.1238308
|
| [46] | M. Liu, O. Tuzel, S. Ramalingam, R. Chellappa, Entropy rate superpixel segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2011), 2097–2104. https://doi.org/10.1109/cvpr.2011.5995323 |
| [47] | R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. FuaSü, S. Sstrunk, Slic superpixels compared to state-of-the-art superpixel methods, IEEE Trans. Pattern Anal. Mach. Intell., 34 (11), 2274–2282. https://doi.org/10.1109/tpami.2012.120 |
| [48] | Z. Li, J. Chen, Superpixel segmentation using linear spectral clustering, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2015), 1356–1363. https://doi.org/10.1109/cvpr.2015.7298741 |
| [49] | Y. Liu, C. Yu, M. Yu, Y. He, Manifold slic: a fast method to compute content-sensitive superpixels, in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, (2016), 651–659. https://doi.org/10.1109/cvpr.2016.77 |
| [50] | R. Achanta, S. Susstrunk, Superpixels and polygons using simple non-iterative clustering, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2017), 4651–4660. https://doi.org/10.1109/cvpr.2017.520 |
| [51] | W. Tu, M. Liu, V. Jampani, D. Sun, S. Chien, M. Yang, et al., Learning superpixels with segmentation-aware affinity loss, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 568–576. https://doi.org/10.1109/cvpr.2018.00066 |
| [52] | V. Jampani, D. Sun, M. Liu, M. Yang, J. Kautz, Superpixel sampling networks, in Proceedings of the European Conference on Computer Vision, (2018), 352–368. https://doi.org/10.1007/978-3-030-01234-2_22 |
| [53] | F. Yang, Q. Sun, H. Jin, Z. Zhou, Superpixel segmentation with fully convolutional networks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2020), 13964–13973. https://doi.org/10.1109/cvpr42600.2020.01398 |
| [54] | T. Suzuki, Superpixel segmentation via convolutional neural networks with regularized information maximization, in IEEE International Conference on Acoustics, Speech and Signal Processing, (2020), 2573–2577. https://doi.org/10.1109/icassp40776.2020.9054140 |
| [55] | L. Zhu, Q. She, B. Zhang, Y. Lu, Z. Lu, D. Li, J. Hu, Learning the superpixel in a non-iterative and lifelong manner, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2021), 1225–1234. https://doi.org/10.1109/cvpr46437.2021.00128 |
| [56] | C. Saueressig, A. Berkley, R. Munbodh, R. Singh, A joint graph and image convolution network for automatic brain tumor segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention Workshop, (2021), 356–365. https://doi.org/10.1007/978-3-031-08999-2_30 |
| [57] | V. Kulikov, V. Lempitsky, Instance segmentation of biological images using harmonic embeddings, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2020), 3843–3851. https://doi.org/10.1109/cvpr42600.2020.00390 |
| [58] | J. Kim, T. Kim, S. Kim, C. Yoo, Edge-labeling graph neural network for few-shot learning, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2019), 11–20. https://doi.org/10.1109/cvpr.2019.00010 |
| [59] | T. Chen, S. Kornblith, M. Norouzi, G. Hinton, A simple framework for contrastive learning of visual representations, in International conference on machine learning, (2020), 1597–1607. |
| [60] | X. Chen, H. Fan, R. Girshick, K. He, Improved baselines with momentum contrastive learning, preprint, arXiv: 2003.04297. |
| [61] | K. He, H. Fan, Y. Wu, S. Xie, R. Girshick, Momentum contrast for unsupervised visual representation learning, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2020), 9729–9738. https://doi.org/10.1109/cvpr42600.2020.00975 |
| [62] | M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, A. Joulin, Unsupervised learning of visual features by contrasting cluster assignments, Adv. Neural Inf. Process. Syst., 33 (2020), 9912–9924. |
| [63] | W. Wang, T. Zhou, F. Yu, J. Dai, E. KonukogluVan, L. Gool, Exploring cross-image pixel contrast for semantic segmentation, in Proceedings of the IEEE International Conference on Computer Vision, (2021), 7303–7313. https://doi.org/10.1109/iccv48922.2021.00721 |
| [64] | J. Gilmer, S. Schoenholz, P. Riley, O. Vinyals, G. Dahl, Neural message passing for quantum chemistry, in International Conference on Machine Learning, 2017. |
| [65] | B. Weisfeiler, A. Leman, A reduction of a graph to a canonical form and an algebra arising during this reduction, Nauchno Tech. Inf., 2 (1968), 12–16. |
| [66] | R. Achanta, S. Susstrunk, Superpixels and polygons using simple non-iterative clustering, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017. https://doi.org/10.1109/cvpr.2017.520 |
| [67] | F. Milletari, N. Navab, S. Ahmadi, V-net: Fully convolutional neural networks for volumetric medical image segmentation, in International Conference on 3D Vision, (2016), 565–571. https://doi.org/10.1109/3dv.2016.79 |
| [68] | D. Kingma, J. Ba, Adam: A method for stochastic optimization, in International Conference on Learning Representations, 2015. |
| [69] |
X. Zheng, Y. Wang, G. Wang, Z. Chen, A novel algorithm based on visual saliency attention for localization and segmentation in rapidly-stained leukocyte images, Micron, 56 (2014), 17–28. https://doi.org/10.1016/j.micron.2013.09.006 doi: 10.1016/j.micron.2013.09.006
|
| [70] | L. McInnes, J. Healy, J. Melville, Umap: Uniform manifold approximation and projection for dimension reduction, preprint, arXiv: 1802.03426. |
| [71] |
A. Acevedo, A. Merino, S. Alférez, A. Molina, L. Boldú, J. Rodellar, A dataset of microscopic peripheral blood cell images for development of automatic recognition systems, Data Brief, 30 (2020), 105474. https://doi.org/10.1016/j.dib.2020.105474 doi: 10.1016/j.dib.2020.105474
|
| [72] | P. Yampri, C. Pintavirooj, S. Daochai, S. Teartulakarn, White blood cell classification based on the combination of eigen cell and parametric feature detection, in IEEE Conference on Industrial Electronics and Applications, (2006), 1–4. https://doi.org/10.1109/iciea.2006.257341 |
| [73] |
I. Livieris, E. Pintelas, A. Kanavos, P. Pintelas, Identification of blood cell subtypes from images using an improved ssl algorithm, Biomed. J. Sci. Tech. Res., 9 (2018), 6923–6929. https://doi.org/10.26717/bjstr.2018.09.001755 doi: 10.26717/bjstr.2018.09.001755
|
| [74] | R. Banerjee, A. Ghose, A light-weight deep residual network for classification of abnormal heart rhythms on tiny devices, in Joint European Conference on Machine Learning and Knowledge Discovery in Databases, (2022), 317–331. https://doi.org/10.1007/978-3-031-23633-4_22 |
| [75] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, (2016), 770–778. https://doi.org/10.1109/cvpr.2016.90 |












Figures(13) / Tables(6)

Yuanhong Jiang, Yiqing Shen, Yuguang Wang, Qiaoqiao Ding. Automatic recognition of white blood cell images with memory efficient superpixel metric GNN: SMGNN[J]. Mathematical Biosciences and Engineering, 2024, 21(2): 2163-2188. doi: 10.3934/mbe.2024095







 DownLoad:
DownLoad: