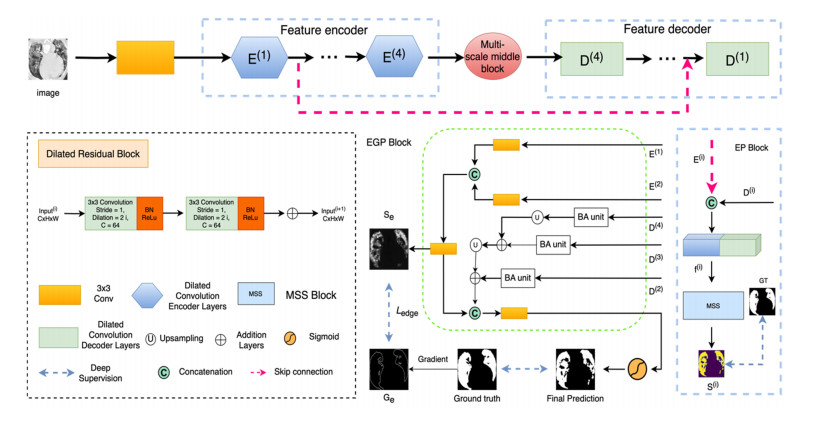
Accurate segmentation of infected regions in lung computed tomography (CT) images is essential for the detection and diagnosis of coronavirus disease 2019 (COVID-19). However, lung lesion segmentation has some challenges, such as obscure boundaries, low contrast and scattered infection areas. In this paper, the dilated multiresidual boundary guidance network (Dmbg-Net) is proposed for COVID-19 infection segmentation in CT images of the lungs. This method focuses on semantic relationship modelling and boundary detail guidance. First, to effectively minimize the loss of significant features, a dilated residual block is substituted for a convolutional operation, and dilated convolutions are employed to expand the receptive field of the convolution kernel. Second, an edge-attention guidance preservation block is designed to incorporate boundary guidance of low-level features into feature integration, which is conducive to extracting the boundaries of the region of interest. Third, the various depths of features are used to generate the final prediction, and the utilization of a progressive multi-scale supervision strategy facilitates enhanced representations and highly accurate saliency maps. The proposed method is used to analyze COVID-19 datasets, and the experimental results reveal that the proposed method has a Dice similarity coefficient of 85.6% and a sensitivity of 84.2%. Extensive experimental results and ablation studies have shown the effectiveness of Dmbg-Net. Therefore, the proposed method has a potential application in the detection, labeling and segmentation of other lesion areas.
Citation: Zhenwu Xiang, Qi Mao, Jintao Wang, Yi Tian, Yan Zhang, Wenfeng Wang. Dmbg-Net: Dilated multiresidual boundary guidance network for COVID-19 infection segmentation[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 20135-20154. doi: 10.3934/mbe.2023892
Accurate segmentation of infected regions in lung computed tomography (CT) images is essential for the detection and diagnosis of coronavirus disease 2019 (COVID-19). However, lung lesion segmentation has some challenges, such as obscure boundaries, low contrast and scattered infection areas. In this paper, the dilated multiresidual boundary guidance network (Dmbg-Net) is proposed for COVID-19 infection segmentation in CT images of the lungs. This method focuses on semantic relationship modelling and boundary detail guidance. First, to effectively minimize the loss of significant features, a dilated residual block is substituted for a convolutional operation, and dilated convolutions are employed to expand the receptive field of the convolution kernel. Second, an edge-attention guidance preservation block is designed to incorporate boundary guidance of low-level features into feature integration, which is conducive to extracting the boundaries of the region of interest. Third, the various depths of features are used to generate the final prediction, and the utilization of a progressive multi-scale supervision strategy facilitates enhanced representations and highly accurate saliency maps. The proposed method is used to analyze COVID-19 datasets, and the experimental results reveal that the proposed method has a Dice similarity coefficient of 85.6% and a sensitivity of 84.2%. Extensive experimental results and ablation studies have shown the effectiveness of Dmbg-Net. Therefore, the proposed method has a potential application in the detection, labeling and segmentation of other lesion areas.

| [1] | World Health Organization, WHO coronavirus (COVID-19) dashboard with vaccination data, 2023. Available from: https://covid19.who.int/. |
| [2] |
A. Alhudhaif, K. Polat, O. Karaman, Determination of COVID-19 pneumonia based on generalized convolutional neural network model from chest X-ray images, Expert Syst. Appl., 180 (2021). https://doi.org/10.1016/j.eswa.2021.115141 doi: 10.1016/j.eswa.2021.115141

|
| [3] |
H. S. Shi, X. Y. Han, N. C. Jiang, Y. K. Cao, O. Alwalid, J. Gu, et al., Radiological findings from 81 patients with COVID-19 pneumonia in Wuhan, China: a descriptive study, Lancet Infect. Dis, 20 (2020), 425–434. https://doi.org/10.1016/S1473-3099(20)30086-4 doi: 10.1016/S1473-3099(20)30086-4
|
| [4] |
Z. Ye, Y. Zhang, Y. Wang, Z. X. Huang, B. Song, Chest CT manifestations of new coronavirus disease 2019 (COVID-19): a pictorial review, Eur. Radio., 30 (2020), 4381–4389. https://doi.org/10.1007/s00330-020-06801-0 doi: 10.1007/s00330-020-06801-0
|
| [5] |
G. D. Rubin, C. J. Ryerson, L. B. Haramati, N. Sverzellati, J. P. Kanne, S. Raoof, et al., The role of chest imaging in patient management during the COVID-19 pandemic: a multinational consensus statement from the fleischner society, Radiology, 296 (2020), 172–180. https://doi.org/10.1148/radiol.2020201365 doi: 10.1148/radiol.2020201365
|
| [6] |
M. Chung, A. Bernheim, X. Mei, N. Zhang, M. Huang, X. Zeng, et al., CT imaging features of 2019 novel coronavirus (2019-nCoV), Radiology, 295 (2020), 202–207. https://doi.org/10.1148/radiol.2020200230 doi: 10.1148/radiol.2020200230
|
| [7] |
H. Munusamy, K. J. Muthukumar, S. Gnanaprakasam, T. R. Shanmugakani, A. Sekar, FractalCovNet architecture for COVID-19 chest X-ray image classification and CT-scan image segmentation, Biocybern. Biomed. Eng., 41 (2021), 1025–1038. https://doi.org/10.1016/j.bbe.2021.06.011 doi: 10.1016/j.bbe.2021.06.011
|
| [8] |
J. P. Kanne, Chest CT findings in 2019 novel coronavirus (2019-nCoV) infections from Wuhan, China: key points for the radiologist, Radiology, 295 (2020), 16–17. https://doi.org/10.1148/radiol.2020200241 doi: 10.1148/radiol.2020200241
|
| [9] | O. Ronneberger, P. Fischer, T. Brox, U-net: convolutional networks for biomedical image segmentation, in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Springer, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |
| [10] | J. Long, E. Shelhamer, T. Darrell, Fully convolutional networks for semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2015), 3431–3440. https://doi.org/10.1109/CVPR.2015.7298965 |
| [11] |
G. Rani, A. Misra, V. S. Dhaka, D. Buddhi, R. K. Sharma, E. Zumpano, et al., A multi-modal bone suppression, lung segmentation, and classification approach for accurate COVID-19 detection using chest radiographs, Intell. Syst. Appl., 16 (2022), 200148. https://doi.org/10.1016/j.iswa.2022.200148 doi: 10.1016/j.iswa.2022.200148
|
| [12] |
D. P. Fan, T. Zhou, G. P. Ji, Y. Zhou, G. Chen, H. Fu, et al., Inf-net: automatic COVID-19 lung infection segmentation from CT images, IEEE Trans. Med. Imaging, 39 (2020), 2626–2637. https://doi.org/10.1109/TMI.2020.2996645 doi: 10.1109/TMI.2020.2996645
|
| [13] |
R. Cong, H. Yang, Q. Jiang, W. Gao, H. Li, C. Wang, et al., BCS-Net: boundary, context, and semantic for automatic COVID-19 lung infection segmentation from CT images, IEEE Trans. Instrum. Meas., 71 (2022), 1–11. https://doi.org/10.1109/TIM.2022.3196430 doi: 10.1109/TIM.2022.3196430
|
| [14] |
R. Cong, Y. Zhang, N. Yang, H. Li, X. Zhang, R. Li, et al., Boundary guided semantic learning for real-time COVID-19 lung infection segmentation system, IEEE Trans. Consum. Electron., 68 (2022), 376–386. https://doi.org/10.1109/TCE.2022.3205376 doi: 10.1109/TCE.2022.3205376
|
| [15] |
X. Wang, Y. Yuan, D. Guo, X. Huang, Y. Cui, M. Xia, et al., SSA-Net: spatial self-attention network for COVID-19 pneumonia infection segmentation with semi-supervised few-shot learning, Med. Image Anal., 79 (2022), 102459. https://doi.org/10.1016/j.media.2022.102459 doi: 10.1016/j.media.2022.102459
|
| [16] |
S. Bose, R. S. Chowdhury, R. Das, U. Maulik, Dense dilated deep multiscale supervised u-network for biomedical image segmentation, Comput. Biol. Med., 143 (2022). https://doi.org/10.1016/j.compbiomed.2022.105274 doi: 10.1016/j.compbiomed.2022.105274
|
| [17] |
Q. Mao, S. G. Zhao, D. B. Tong, S. C. Su, Z. W. Li, X. Cheng, Hessian-MRLoG: Hessian information and multi-scale reverse LoG filter for pulmonary nodule detection, Comput. Biol. Med., 131 (2021). https://doi.org/10.1016/j.compbiomed.2021.104272 doi: 10.1016/j.compbiomed.2021.104272
|
| [18] |
Q. Mao, S. G. Zhao, L. J. Ren, Z. W. Li, D. B. Tong, X. Yuan, et al., Intelligent immune clonal optimization algorithm for pulmonary nodule classification, Math. Biosci. Eng., 18 (2021), 4146–4161. https://doi.org/10.3934/mbe.2021208 doi: 10.3934/mbe.2021208
|
| [19] |
G. Rani, A. Misra, V. S. Dhaka, E. Zumpano, E. Vocaturo, Spatial feature and resolution maximization GAN for bone suppression in chest radiographs, Comput. Methods Programs Biomed., 224 (2022), 107024. https://doi.org/10.1016/j.cmpb.2022.107024 doi: 10.1016/j.cmpb.2022.107024
|
| [20] |
X. Yan, Y. Liu, M. Jia, Multiscale cascading deep belief network for fault identification of rotating machinery under various working conditions, Knowledge-Based Syst., 193 (2020), 105484. https://doi.org/10.1016/j.knosys.2020.105484 doi: 10.1016/j.knosys.2020.105484
|
| [21] |
X. Yan, D. She, Y. Xu, M. Jia, Deep regularized variational autoencoder for intelligent fault diagnosis of rotor-bearing system within entire life-cycle process, Knowledge-based Syst., 226 (2021), 107142. https://doi.org/10.1016/j.knosys.2021.107142 doi: 10.1016/j.knosys.2021.107142
|
| [22] |
X. Yan, D. She, Y. Xu, Deep order-wavelet convolutional variational autoencoder for fault identification of rolling bearing under fluctuating speed conditions, Expert Syst. Appl., 216 (2023), 119479. https://doi.org/10.1016/j.eswa.2022.119479 doi: 10.1016/j.eswa.2022.119479
|
| [23] |
F. Bougourzi, C. Distante, F. Dornaika, A. Taleb-Ahmed, PDAtt-Unet: pyramid dual-decoder attention unet for COVID-19 infection segmentation from CT-scans, Med. Image Anal., 86 (2023), 102797. https://doi.org/10.1016/j.media.2023.102797 doi: 10.1016/j.media.2023.102797
|
| [24] |
L. Zhou, Z. Li, J. Zhou, H. Li, Y. Chen, Y. Huang, et al., A rapid, accurate and machine-agnostic segmentation and quantification method for CT-based COVID-19 diagnosis, IEEE Trans. Med. Imaging, 39 (2020), 2638–2652. https://doi.org/10.1109/TMI.2020.3001810 doi: 10.1109/TMI.2020.3001810
|
| [25] |
X. F. Wang, L. Jiang, L. Li, M. Xu, X. Deng, L. S. Dai, et al., Joint learning of 3D lesion segmentation and classification for explainable COVID-19 diagnosis, IEEE Trans. Med. Imaging, 40 (2021), 2463–2476. https://doi.org/10.1109/TMI.2021.3079709 doi: 10.1109/TMI.2021.3079709
|
| [26] |
X. Zhong, H. B. Zhang, G. L. Li, D. H. Ji, Do you need sharpened details? Asking MMDC-Net: multi-layer multi-scale dilated convolution network for retinal vessel segmentation, Comput. Biol. Med., 150 (2022). https://doi.org/10.1016/j.compbiomed.2022.106198 doi: 10.1016/j.compbiomed.2022.106198
|
| [27] |
C. Fan, Z. Zeng, L. Xiao, X. Qu, GFNet: automatic segmentation of COVID-19 lung infection regions using CT images based on boundary features, Pattern Recognit., 132 (2022), 108963. https://doi.org/10.1016/j.patcog.2022.108963 doi: 10.1016/j.patcog.2022.108963
|
| [28] |
S. Chakraborty, K. Mali, SUFEMO: a superpixel based fuzzy image segmentation method for COVID-19 radiological image elucidation, Appl. Soft Comput., 129 (2022). https://doi.org/10.1016/j.asoc.2022.109625 doi: 10.1016/j.asoc.2022.109625
|
| [29] |
N. Paluru, A. Dayal, H. B. Jenssen, T. Sakinis, L. R. Cenkeramaddi, J. Prakash, et al., Anam-Net: anamorphic depth embedding-based lightweight CNN for segmentation of anomalies in COVID-19 Chest CT Images, IEEE Trans. Neural Networks Learn. Syst., 32 (2021), 932–946. https://doi.org/10.1109/TNNLS.2021.3054746 doi: 10.1109/TNNLS.2021.3054746
|
| [30] |
G. Wang, X. Liu, C. Li, Z. Xu, J. Ruan, H. Zhu, et al., A noise-robust framework for automatic segmentation of COVID-19 pneumonia lesions from CT images, IEEE Trans. Med. Imaging, 39 (2020), 2653–2663. https://doi.org/10.1109/TMI.2020.3000314 doi: 10.1109/TMI.2020.3000314
|
| [31] |
Y. H. Wu, S. H. Gao, J. Mei, J. Xu, D. P. Fan, R. G. Zhang, et al., Jcs: An explainable COVID-19 diagnosis system by joint classification and segmentation, IEEE Trans. Image Process., 30 (2021), 3113–3126. https://doi.org/10.1109/TIP.2021.3058783 doi: 10.1109/TIP.2021.3058783
|
| [32] |
S. X. Zhao, Z. D. Li, Y. Chen, W. Zhao, X. Z. Xie, J. Liu, et al., SCOAT-Net: a novel network for segmenting COVID-19 lung opacification from CT images, Pattern Recognit., 119 (2021). https://doi.org/10.1016/j.patcog.2021.108109 doi: 10.1016/j.patcog.2021.108109
|
| [33] | Z. J. Zhang, H. Z. Fu, H. Dai, J. B. Shen, Y. W. Pang, L. Shao, ET-Net: a generic edge-attention guidance network for medical image segmentation, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2019, (2019), 442–450. https://doi.org/10.1007/978-3-030-32239-7_49 |
| [34] | Z. Wu, L. Su, Q. Huang, Stacked cross refinement network for edge-aware salient object detection, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 7264–7273. |
| [35] | Radiologists, COVID-19 CT segmentation dataset, 2020. Available from: https://medicalsegmentation.com/covid19. |
| [36] | J. Ma, C. Ge, Y. Wang, X. An, J. Gao, Z. Yu, et al., COVID-19 CT lung and infection segmentation dataset, 2020. https://doi.org/10.5281/zenodo.3757476 |
| [37] | Z. Zhou, M. M. R. Siddiquee, N. Tajbakhsh, J. Liang, Unet++: a nested u-net architecture for medical image segmentation, in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Springer, (2018), 3–11. https://doi.org/10.1007/978-3-030-00889-5_1 |
| [38] | O. Oktay, J. Schlemper, L. L. Folgoc, M. Lee, M. Heinrich, K. Misawa, et al., Attention u-net: learning where to look for the pancreas, arXiv preprint, (2018), arXiv: 1804.03999. https://doi.org/10.48550/arXiv.1804.03999 |
| [39] | K. Zhang, X. Liu, J. Shen, Z. Li, Y. Sang, X. Wu, et al., Clinically applicable AI system for accurate diagnosis, quantitative measurements, and prognosis of COVID-19 pneumonia using computed tomography, Cell, 181 (2020), 1423–1433. |
| [40] | A. Paszke, A. Chaurasia, S. Kim, E. Culurciello, Enet: A deep neural network architecture for real-time semantic segmentation, arXiv preprint, (2016), arXiv: 1606.02147. https://doi.org/10.48550/arXiv.1606.02147 |







Figures(8) / Tables(3)

Zhenwu Xiang, Qi Mao, Jintao Wang, Yi Tian, Yan Zhang, Wenfeng Wang. Dmbg-Net: Dilated multiresidual boundary guidance network for COVID-19 infection segmentation[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 20135-20154. doi: 10.3934/mbe.2023892







 DownLoad:
DownLoad: