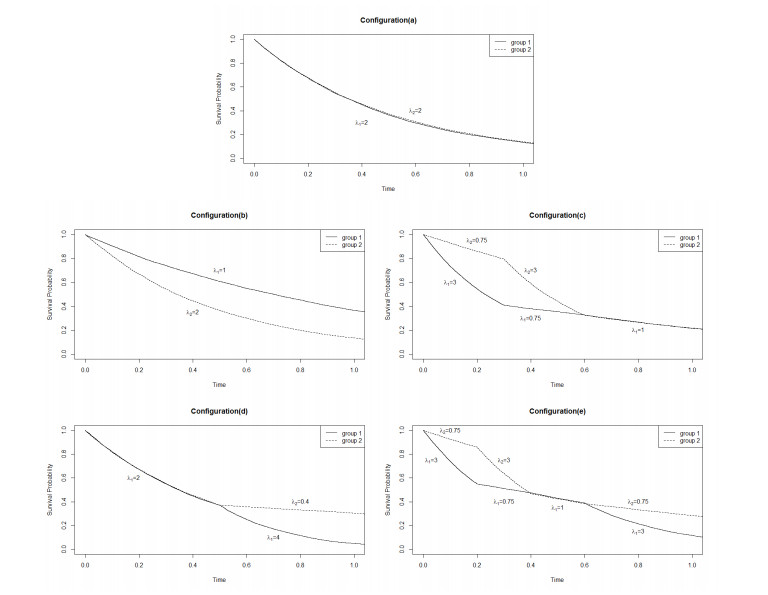
Many tests for comparing survival curves have been proposed over the last decades. There are two branches, one based on weighted log-rank statistics and other based on weighted Kaplan-Meier statistics. If we carefully choose the weight function, a substantial increase in power of tests against non-proportional alternatives can be obtained. However, it is difficult to specify in advance the types of survival differences that may actually exist between two groups. Therefore, a combination test can simultaneously detect equally weighted, early, late or middle departures from the null hypothesis and can robustly handle several non-proportional hazard types with no a priori knowledge of the hazard functions. In this paper, we focus on the most used and the most powerful test statistics related to these two branches which have been studied separately but not compared between them. Through a simulation study, we compare the size and power of thirteen test statistics under proportional hazards and different types of non-proportional hazards patterns. We illustrate the procedures using data from a clinical trial of bone marrow transplant patients with leukemia.
Citation: María del Carmen Pardo, Beatriz Cobo. Comparison of methods to testing for differential treatment effect under non-proportional hazards data[J]. Mathematical Biosciences and Engineering, 2023, 20(10): 17646-17660. doi: 10.3934/mbe.2023784
Many tests for comparing survival curves have been proposed over the last decades. There are two branches, one based on weighted log-rank statistics and other based on weighted Kaplan-Meier statistics. If we carefully choose the weight function, a substantial increase in power of tests against non-proportional alternatives can be obtained. However, it is difficult to specify in advance the types of survival differences that may actually exist between two groups. Therefore, a combination test can simultaneously detect equally weighted, early, late or middle departures from the null hypothesis and can robustly handle several non-proportional hazard types with no a priori knowledge of the hazard functions. In this paper, we focus on the most used and the most powerful test statistics related to these two branches which have been studied separately but not compared between them. Through a simulation study, we compare the size and power of thirteen test statistics under proportional hazards and different types of non-proportional hazards patterns. We illustrate the procedures using data from a clinical trial of bone marrow transplant patients with leukemia.

| [1] |
R. S. Herbst, P. Baas, D. W. Kim, E. Felip, J. L. Pérez-Gracia, J. Y. Han, et al., Pembrolizumab Versus Docetaxel for Previously Treated, PDL1-Positive, Advanced Non-Small-Cell Lung Cancer (KEYNOTE-010): A Randomised Controlled Trial, The Lancet, 387 (2016), 1540–-1550. https://doi.org/10.1016/S0140-6736(15)01281-7 doi: 10.1016/S0140-6736(15)01281-7

|
| [2] |
M. S. Pepe, T. R. Fleming, Weighted Kaplan-Meier statistics: A class of distance tests for censored survival data, Biometrics, 45 (1989), 497–507. http://dx.doi.org/10.2307/2531492 doi: 10.2307/2531492
|
| [3] |
B. Huang, P. F. Kuan, Comparison of the restricted mean survival time with the hazard ratio in superiority trials with a time-to-event end point, Pharmaceut. Statist., 17 (2018), 202–213. http://dx.doi.org/10.1002/pst.1846 doi: 10.1002/pst.1846
|
| [4] |
S. G. Self, An adaptive weighted log-rank test with application to cancer prevention and screening trials, Biometrics, 47 (1991), 975–986. http://dx.doi.org/10.2307/2532653 doi: 10.2307/2532653
|
| [5] |
T. R. Fleming, D. P. Harrington, A class of hypothesis tests for one and two samples of censored survival data, Commun. Statist. Theory Methods, 13 (1981), 2469–2486. http://dx.doi.org/10.1080/03610928108828073 doi: 10.1080/03610928108828073
|
| [6] |
D. P. Harrington, T. R. Fleming, A class of rank test procedures for censored survival data, Biometrika, 69 (1982), 553–566. http://dx.doi.org/10.1093/biomet/69.3.553 doi: 10.1093/biomet/69.3.553
|
| [7] | T. R. Fleming, D. P. Harrington, Counting Processes and Survival Analysis, New York: Wiley, (1991). http://dx.doi.org/10.1002/9781118150672 |
| [8] |
J. W. Lee, Some versatile tests based on the simultaneous use of weighted log-rank statistics, Biometrics, 52 (1996), 721–725. http://dx.doi.org/10.2307/2532911 doi: 10.2307/2532911
|
| [9] |
S. H. Lee, On the versatility of the combination of the weighted log-rank statistics, Comput. Statist. Data Anal., 51 (2007), 6557–6564. http://dx.doi.org/10.1016/j.csda.2007.03.006 doi: 10.1016/j.csda.2007.03.006
|
| [10] |
T. G. Karrison, Versatile tests for comparing survival curves based on weighted log-rank statistics, Stat. J., 16 (2016), 678–690. http://dx.doi.org/10.1177/1536867X1601600308 doi: 10.1177/1536867X1601600308
|
| [11] |
Y. Shen, J. Cai, Maximum of the Weighted Kaplan-Meier tests with application to cancer prevention and screening trials, Biometrics, 57 (2001), 837–843. http://dx.doi.org/10.1111/j.0006-341X.2001.00837.x doi: 10.1111/j.0006-341X.2001.00837.x
|
| [12] |
S. H. Lee, Maximum of the weighted Kaplan-Meier tests for the two-sample censored data, J. Statist. Comput. Simul., 81 (2011), 1017–1026. http://dx.doi.org/10.1080/00949651003627753 doi: 10.1080/00949651003627753
|
| [13] |
P. Royston, M. K. B. Parmar, A simulation study comparing the power of nine tests of the treatment effect in randomized controlled trials with a time-to-event outcome, Trials, 21 (2020), 315. http://dx.doi.org/10.1186/s13063-020-4153-2 doi: 10.1186/s13063-020-4153-2
|
| [14] |
R. S. Lin, J. Lin, S. Roychoudhury, K. M. Anderson, T. Hu, B. Huang, et al., Alternative Analysis Methods for Time to Event Endpoints under Non-proportional Hazards: A Comparative Analysis, Statist. Biopharm. Res., 12 (2020), 187–198. https://doi.org/10.1080/19466315.2019.1697738 doi: 10.1080/19466315.2019.1697738
|
| [15] |
S. Roychoudhury, K. M. Anderson, J. Ye, P. Mukhopadhyay, Robust Design and Analysis of Clinical Trials with Nonproportional Hazards: A Straw Man Guidance From a Cross- Pharma Working Group, Statist. Biopharm. Res., 15 (2021), 280–294. http://dx.doi.org/10.1080/19466315.2021.1874507 doi: 10.1080/19466315.2021.1874507
|
| [16] |
E. Kaplan, P. Meier, Nonparametric estimation from incomplete observations, J. Amer. Statist. Assoc., 53 (1958), 457–481. http://dx.doi.org/10.1080/01621459.1958.10501452 doi: 10.1080/01621459.1958.10501452
|
| [17] |
T. R. Fleming, D. P. Harrington, M. O'Sullivan, Supremum versions of the log-rank and generalized Wilcoxon statistics, J. Am. Stat. Assoc., 82 (1987), 312–320. http://dx.doi.org/10.1080/01621459.1987.10478435 doi: 10.1080/01621459.1987.10478435
|
| [18] | W. Yang, W. Haiyan, A. Keaven, R. Satrajit, H. Tianle, L. Hongliu, R package nphsim: Non proportional hazards sample size and simulation, (2017). Available from: https://github.com/keaven/nphsim |
| [19] | R. Ristl, N. Ballarini, R package nph: Planning and Analysing Survival Studies under Non-Proportional Hazards, (2020). Available from: https://CRAN.R-project.org/package=nph |
| [20] | M. Bofill, G. Gómez, R package SurvBin: Two-sample statistics for binary and time-to-event outcomes, (2020). Available from: https://github.com/MartaBofillRoig/SurvBin |
| [21] | H. Uno, L. Tian, M. Horiguchi, A. Cronin, C. Battioui, J. Bell, R package survRM2: Comparing Restricted Mean Survival Time, (2020). Available from: https://CRAN.R-project.org/package=survRM2 |
| [22] | J. P Klein, M. L. Moeschberger, J. Yan, R package KMsurv: Data sets from Klein and Moeschberger (1997), Survival Analysis, (2012). Available from: https://CRAN.R-project.org/package=KMsurv |
| [23] |
R. S. Lin, L. F. León, Estimation of treatment effects in weighted log-rank tests, Contempor. Clin. Trials Commun., 8 (2017), 147–155. http://dx.doi.org/10.1016/j.conctc.2017.09.004 doi: 10.1016/j.conctc.2017.09.004
|


Figures(3) / Tables(3)

María del Carmen Pardo, Beatriz Cobo. Comparison of methods to testing for differential treatment effect under non-proportional hazards data[J]. Mathematical Biosciences and Engineering, 2023, 20(10): 17646-17660. doi: 10.3934/mbe.2023784







 DownLoad:
DownLoad: