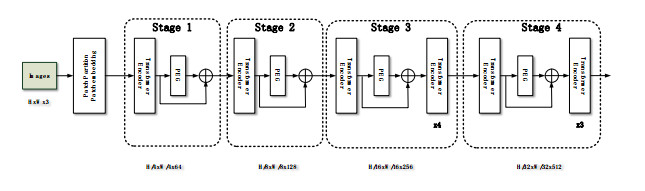
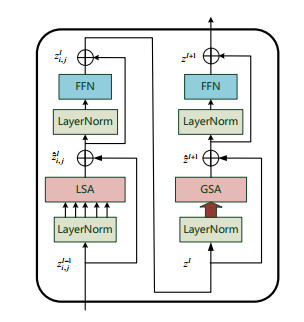
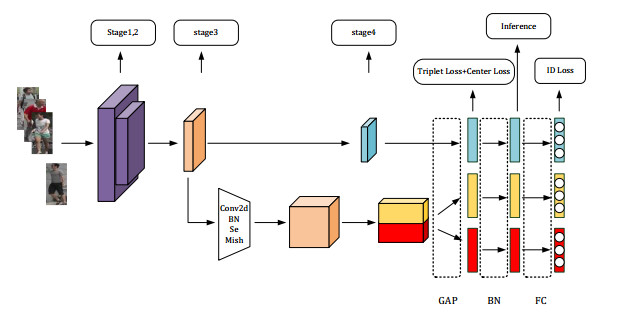
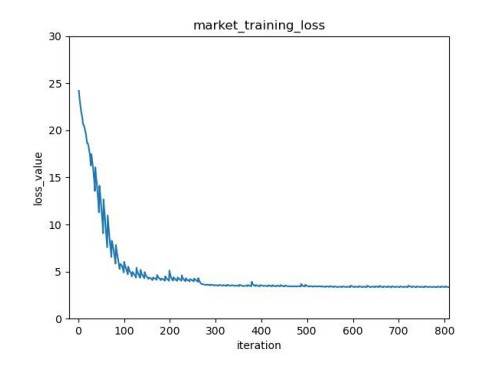
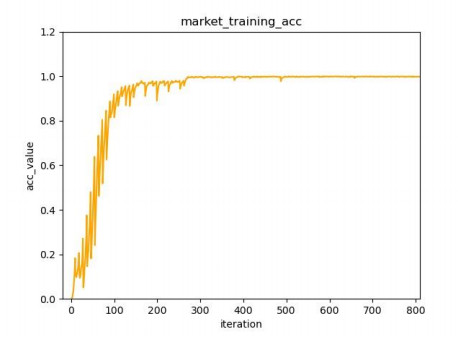
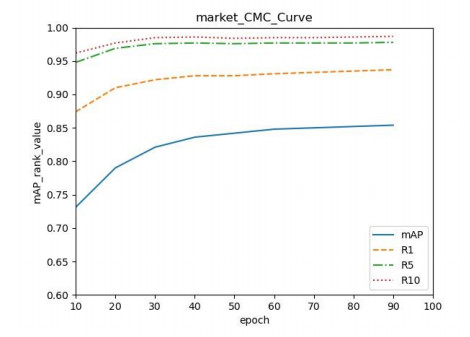
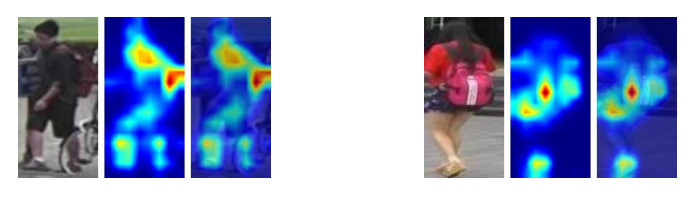
In the traditional person re-identification model, the CNN network is usually used for feature extraction. When converting the feature map into a feature vector, a large number of convolution operations are used to reduce the size of the feature map. In CNN, since the receptive field of the latter layer is obtained by convolution operation on the feature map of the previous layer, the size of this local receptive field is limited, and the computational cost is large. For these problems, combined with the self-attention characteristics of Transformer, an end-to-end person re-identification model (twinsReID) is designed that integrates feature information between levels in this article. For Transformer, the output of each layer is the correlation between its previous layer and other elements. This operation is equivalent to the global receptive field because each element needs to calculate the correlation with other elements, and the calculation is simple, so its cost is small. From these perspectives, Transformer has certain advantages over CNN's convolution operation. This paper uses Twins-SVT Transformer to replace the CNN network, combines the features extracted from the two different stages and divides them into two branches. First, convolve the feature map to obtain a fine-grained feature map, perform global adaptive average pooling on the second branch to obtain the feature vector. Then divide the feature map level into two sections, perform global adaptive average pooling on each. These three feature vectors are obtained and sent to the Triplet Loss respectively. After sending the feature vectors to the fully connected layer, the output is input to the Cross-Entropy Loss and Center-Loss. The model is verified On the Market-1501 dataset in the experiments. The mAP/rank1 index reaches 85.4%/93.7%, and reaches 93.6%/94.9% after reranking. The statistics of the parameters show that the parameters of the model are less than those of the traditional CNN model.
Citation: Keying Jin, Jiahao Zhai, Yunyuan Gao. TwinsReID: Person re-identification based on twins transformer's multi-level features[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 2110-2130. doi: 10.3934/mbe.2023098
In the traditional person re-identification model, the CNN network is usually used for feature extraction. When converting the feature map into a feature vector, a large number of convolution operations are used to reduce the size of the feature map. In CNN, since the receptive field of the latter layer is obtained by convolution operation on the feature map of the previous layer, the size of this local receptive field is limited, and the computational cost is large. For these problems, combined with the self-attention characteristics of Transformer, an end-to-end person re-identification model (twinsReID) is designed that integrates feature information between levels in this article. For Transformer, the output of each layer is the correlation between its previous layer and other elements. This operation is equivalent to the global receptive field because each element needs to calculate the correlation with other elements, and the calculation is simple, so its cost is small. From these perspectives, Transformer has certain advantages over CNN's convolution operation. This paper uses Twins-SVT Transformer to replace the CNN network, combines the features extracted from the two different stages and divides them into two branches. First, convolve the feature map to obtain a fine-grained feature map, perform global adaptive average pooling on the second branch to obtain the feature vector. Then divide the feature map level into two sections, perform global adaptive average pooling on each. These three feature vectors are obtained and sent to the Triplet Loss respectively. After sending the feature vectors to the fully connected layer, the output is input to the Cross-Entropy Loss and Center-Loss. The model is verified On the Market-1501 dataset in the experiments. The mAP/rank1 index reaches 85.4%/93.7%, and reaches 93.6%/94.9% after reranking. The statistics of the parameters show that the parameters of the model are less than those of the traditional CNN model.

| [1] |
W. Luo, Y. Li, R. Urtasun, R. Zemel, Understanding the effective receptive field in deep convolutional neural networks, Neural Information Processing Systems (NIPS 2017), 29 (2017). https://doi.org/10.48550/arXiv.1701.04128 doi: 10.48550/arXiv.1701.04128

|
| [2] | A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. H. Zhai, T. Unterthiner, et al., An image is worth 16x16 words: Transformers for image recognition at scale, (2020), preprint. https://doi.org/10.48550/arXiv.2010.11929 |
| [3] | J. Devlin, M. W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, (2018), preprint. https://doi.org/10.48550/arXiv.1810.04805 |
| [4] | A. Radford, K. Narasimhan, T. Salimans, I. Sutskever, Improving language understanding by generative pre-training, (2018), work in progress. |
| [5] |
X. X. Chu, Z. Tian, Y. Q. Wang, B. Zhang, H. B. Ren, X. L. Wei, et al., Twins: Revisiting the design of spatial attention in vision transformers, Neural Information Processing Systems (NIPS 2021), 34 (2021). https://doi.org/10.48550/arXiv.2104.13840 doi: 10.48550/arXiv.2104.13840
|
| [6] |
S. Cheng, I. C. Prentice, Y. Huang, Y. Jin, Y. K. Guo, R. Arcucci, Data-driven surrogate model with latent data assimilation: Application to wildfire forecasting, J. Comput. Phys., 464 (2022), 111302. https://doi.org/10.1016/j.jcp.2022.111302 doi: 10.1016/j.jcp.2022.111302
|
| [7] |
J. A. Weyn, D. R. Durran, R. Caruana, Improving data-driven global weather prediction using deep convolutional neural networks on a cubed sphere, J. Adv. Model. Earth Syst., 12 (2020). https://doi.org/10.1029/2020MS002109 doi: 10.1029/2020MS002109
|
| [8] | M. Chen, A. Radford, J. Wu, H. W. Jun, P. Dhariwal, D. Luan, et al., Generative pretraining from pixels, Proceed. Mach. Learn. Res., 199 (2020), 1691–1703. |
| [9] |
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, H. Jégou, Training data-efficient image transformers & distillation through attention, Proceed. Mach. Learn. Res., 139 (2021), 10347–10357. https://doi.org/10.48550/arXiv.2012.12877 doi: 10.48550/arXiv.2012.12877
|
| [10] |
K. Han, A. Xiao, E. Wu, J. Guo, C. Xu, Y. Wang, Transformer in transformer, Neural Information Processing Systems, 34 (2021), 15908–15919. https://doi.org/10.48550/arXiv.2103.00112 doi: 10.48550/arXiv.2103.00112
|
| [11] | N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, S. Zagoruyko, End-to-end object detection with transformers, in European conference on computer vision (ECCV 2020), (2020), 213–229. https://doi.org/10.1007/978-3-030-58452-8_13 |
| [12] | R. Strudel, R. Garcia, I. Laptev, C. Schmid, Segmenter: Transformer for semantic segmentation, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 7242–7252. https://doi.org/10.48550/arXiv.2105.05633 |
| [13] | S. He, H. Luo, P. Wang, F. Wang, H. Li, W. Jiang, TransReID: Transformer-based Object Re-Identification, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 14993–15002. https://doi.org/10.1109/ICCV48922.2021.01474 |
| [14] | Z. Liu, Y. Lin, Y. Cao, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 9992–10002. https://doi.org/10.1109/ICCV48922.2021.00986 |
| [15] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [16] | W. Wang, E. Xie, X. Li, D. P. Fan, K. T. Song, D. Liang, et al., Pyramid vision transformer: A versatile backbone for dense prediction without convolutions, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 548–558. https://doi.org/10.1109/ICCV48922.2021.00061 |
| [17] | X. Chu, Z. Tian, B. Zhang, X. Wang, X. Wei, H. Xia, et al., Conditional positional encodings for vision transformers, (2021), preprint. https://doi.org/10.48550/arXiv.2102.10882 |
| [18] |
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, Neural Information Processing Systems (NIPS 2017), 30 (2017). https://doi.org/10.48550/arXiv.1706.03762 doi: 10.48550/arXiv.1706.03762
|
| [19] | L. Sifre, S. Mallat, Rigid-Motion Scattering for Image Classification, (2014), preprint. https://doi.org/10.48550/arXiv.1403.1687 |
| [20] | J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 7032–7141. https://doi.org/10.1109/CVPR.2018.00745 |
| [21] | D. Misra, Mish: A self regularized non-monotonic activation function, (2019), preprint. https://doi.org/10.48550/arXiv.1908.08681 |
| [22] | H. Luo, Y. Gu, X. Liao, S. Lai, W. Jiang, Bag of tricks and a strong baseline for deep person re-identification, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), (2019), 1487–1495. https://doi.org/10.1109/CVPRW.2019.00190 |
| [23] | C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the inception architecture for computer vision, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 2818–2826. https://doi.org/10.1109/CVPR.2016.308 |
| [24] | F. Schroff, D. Kalenichenko, J. Philbin, Facenet: A unified embedding for face recognition and clustering, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 815–823. https://doi.org/10.1109/CVPR.2015.7298682 |
| [25] | Y. Wen, K. Zhang, Z. Li, Y. Qiao, A Discriminative Feature Learning Approach for Deep Face Recognition, in European conference on computer vision (ECCV 2016), (2016). https://doi.org/10.1007/978-3-319-46478-7_31 |
| [26] |
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, et al., ImageNet large scale visual recognition challenge, Int. J. Comput. Vision, 115 (2015), 211–252. https://doi.org/10.1007/s11263-015-0816-y doi: 10.1007/s11263-015-0816-y
|
| [27] | Z. Zhong, L. Zheng, G. Kang, S. Li, Y. Yang, Random erasing data augmentation, in Proceedings of the AAAI conference on artificial intelligence, 34 (2020). https://doi.org/10.48550/arXiv.1708.04896 |
| [28] | Z. Zhong, L. Zheng, D. Cao, S. Li, Re-ranking person re-identification with k-reciprocal encoding, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 3652–3661. https://doi.org/10.1109/CVPR.2017.389 |
| [29] | K. Zhou, Y. Yang, A. Cavallaro, T. Xiang, Omni-scale feature learning for person re-identification, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), (2019), 3701–3711. https://doi.org/10.1109/ICCV.2019.00380 |
| [30] |
P. Wang, Z. Zhao, F. Su, X. Zu, N.V. Boulgouris, HOReID: Deep high-order mapping enhances pose alignment for person re-identification, IEEE Transact. Image Process., 30 (2021), 2908–2922. https://doi.org/10.1109/TIP.2021.3055952 doi: 10.1109/TIP.2021.3055952
|
| [31] | R. Quan, X. Dong, Y. Wu, L. Zhu, Y. Yang, Auto-ReID: Searching for a part-aware ConvNet for person re-identification, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 3749–3758. https://doi.org/10.1109/ICCV.2019.00385 |
| [32] |
H. Luo, W. Jiang, X. Zhang, X. Fan, J. Qian, C. Zhang, Alignedreid++: Dynamically matching local information for person re-identification, Pattern Recogn. J. Pattern Recogn. Soc., 94 (2019), 53–61. https://doi.org/10.1016/j.patcog.2019.05.028 doi: 10.1016/j.patcog.2019.05.028
|
| [33] | C.-P. Tay, S. Roy, K.-H. Yap, AANet: Attribute Attention Network for Person Re-Identifications, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 7127–7136. https://doi.org/10.1109/CVPR.2019.00730 |
| [34] | M. Zheng, S. Karanam, Z. Wu, R.J. Radke, Re-Identification With Consistent Attentive Siamese Networks, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 5728–5737. https://doi.org/10.1109/CVPR.2019.00588 |
| [35] | B. Chen, W. Deng, J. Hu, Mixed High-Order Attention Network for Person Re-Identification, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 371–381. https://doi.org/10.48550/arXiv.1908.05819 |
| [36] | M. M. Kalayeh, E. Basaran, M. Gökmen, M. E. Kamasak, M. Shah, Human semantic parsing for person re-identification, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 1062–1071. https://doi.org/10.1109/CVPR.2018.00117 |
| [37] | M. S. Sarfraz, A. Schumann, A. Eberle, R. Stiefelhagen, A pose-sensitive embedding for person re-identification with expanded cross neighborhood re-ranking, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 420–429. https://doi.org/10.1109/CVPR.2018.00051 |
| [38] | J. Wang, X. Zhu, S. Gong, W. Li, Transferable joint attribute-identity deep learning for unsupervised person re-identification, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 2275–2284. https://doi.org/10.1109/CVPR.2018.00242 |
| [39] | J. Liu, Z.-J. Zha, D. Chen, R. Hong, M. Wang, Adaptive transfer network for cross-domain person re-identification, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 7195–7204. https://doi.org/10.1109/CVPR.2019.00737 |
| [40] | I. Goodfellow, J. Pouget-Abadie, M. Mirza, Conditional generative adversarial nets, in Neural Information Processing Systems, 27 (2014). https://doi.org/10.48550/arXiv.1411.1784 |
| [41] | H. Park, B. Ha, Relation network for person re-identification, in Proceedings of the AAAI Conference on Artificial Intelligence, (2020). https://doi.org/10.48550/arXiv.1911.09318 |
| [42] |
H. Tan, H. Xiao, X. Zhang, B. Dai, S. M. Lai, Y. Liu, et al., MSBA: Multiple scales, branches and attention network with bag of tricks for person re-identification, IEEE Access, 8 (2020), 63632–63642. https://doi.org/10.1109/ACCESS.2020.2984915 doi: 10.1109/ACCESS.2020.2984915
|
| [43] | G. Wang, Y. Yuan, X. Chen, J. Li, X. Zhou, Learning discriminative features with multiple granularities for person re-identification, in Proceedings of the 26th ACM international conference on Multimedia, (2018). https://doi.org/10.1145/3240508.3240552 |



Figures(10) / Tables(7)

Keying Jin, Jiahao Zhai, Yunyuan Gao. TwinsReID: Person re-identification based on twins transformer's multi-level features[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 2110-2130. doi: 10.3934/mbe.2023098







 DownLoad:
DownLoad: