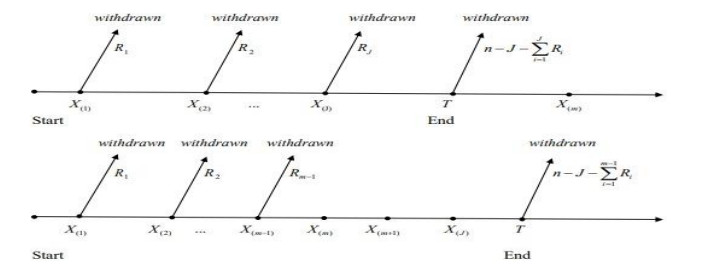
In real-life experiments, collecting complete data is time-, finance-, and resources-consuming as stated by statisticians and analysts. Their goal was to compromise between the total time of testing, the number of units under scrutiny, and the expenditures paid through a censoring scheme. Comparing failure-censored schemes (Type-Ⅱ and Progressive Type-Ⅱ) to Time-censored schemes (Type-Ⅰ), it's worth noting that the former is time-consuming and is no more suitable to be applied in real-life situations. This is the reason why the Type-Ⅰ adaptive progressive hybrid censoring scheme has exceeded other failure-censored types; Time-censored types enable analysts to accomplish their trials and experiments in a shorter time and with higher efficiency. In this paper, the parameters of the inverse Weibull distribution are estimated under the Type-Ⅰ adaptive progressive hybrid censoring scheme (Type-Ⅰ APHCS) based on competing risks data. The model parameters are estimated using maximum likelihood estimation and Bayesian estimation methods. Further, we examine the asymptotic confidence intervals and bootstrap confidence intervals for the unknown model parameters. Monte Carlo simulations are carried out to compare the performance of the suggested estimation methods under Type-Ⅰ APHCS. Moreover, Markov Chain Monte Carlo by applying Metropolis-Hasting algorithm under the square error of loss function is used to compute Bayes estimates and related to the highest posterior density. Finally, two data sets are studied to illustrate the introduced methods of inference. Based on our results, we can conclude that the Bayesian estimation outperforms the maximum likelihood estimation for estimating the inverse Weibull parameters under Type-Ⅰ APHCS.
Citation: Wael S. Abu El Azm, Ramy Aldallal, Hassan M. Aljohani, Said G. Nassr. Estimations of competing lifetime data from inverse Weibull distribution under adaptive progressively hybrid censored[J]. Mathematical Biosciences and Engineering, 2022, 19(6): 6252-6275. doi: 10.3934/mbe.2022292
In real-life experiments, collecting complete data is time-, finance-, and resources-consuming as stated by statisticians and analysts. Their goal was to compromise between the total time of testing, the number of units under scrutiny, and the expenditures paid through a censoring scheme. Comparing failure-censored schemes (Type-Ⅱ and Progressive Type-Ⅱ) to Time-censored schemes (Type-Ⅰ), it's worth noting that the former is time-consuming and is no more suitable to be applied in real-life situations. This is the reason why the Type-Ⅰ adaptive progressive hybrid censoring scheme has exceeded other failure-censored types; Time-censored types enable analysts to accomplish their trials and experiments in a shorter time and with higher efficiency. In this paper, the parameters of the inverse Weibull distribution are estimated under the Type-Ⅰ adaptive progressive hybrid censoring scheme (Type-Ⅰ APHCS) based on competing risks data. The model parameters are estimated using maximum likelihood estimation and Bayesian estimation methods. Further, we examine the asymptotic confidence intervals and bootstrap confidence intervals for the unknown model parameters. Monte Carlo simulations are carried out to compare the performance of the suggested estimation methods under Type-Ⅰ APHCS. Moreover, Markov Chain Monte Carlo by applying Metropolis-Hasting algorithm under the square error of loss function is used to compute Bayes estimates and related to the highest posterior density. Finally, two data sets are studied to illustrate the introduced methods of inference. Based on our results, we can conclude that the Bayesian estimation outperforms the maximum likelihood estimation for estimating the inverse Weibull parameters under Type-Ⅰ APHCS.

| [1] |
B. Epstein, Truncated life tests in the exponential case, Ann. Math. Stat., 25 (1954), 555-564. https://doi.org/10.1214/aoms/1177728723 doi: 10.1214/aoms/1177728723

|
| [2] |
A. Childs, B. Chandrasekar, N. Balakrishnan, D. Kundu, Exact likelihood inference based on type Ⅰ and type Ⅱ hybrid censored samples from the exponential distribution, Ann. Inst. Stat. Math., 55 (2003), 319-330. https://doi.org/10.1007/BF02530502 doi: 10.1007/BF02530502
|
| [3] |
D. Kundu, A. Joarder, Analysis of type Ⅱ progressively hybrid censored data, Comput. Stat. Data Anal., 50 (2006a), 2509-2528. https://doi.org/10.1016/j.csda.2005.05.002 doi: 10.1016/j.csda.2005.05.002
|
| [4] |
D. Kundu, A. Joarder, Analysis of type Ⅱ progressively hybrid censored competing risks data, J. Mod. Appl. Stat. Methods, 5 (2006b), 186-204. https://doi.org/10.22237/jmasm/1146456780 doi: 10.22237/jmasm/1146456780
|
| [5] | A. Childs, B. Chandrasekar, N. Balakrishnan, Exact likelihood inference for exponential parameter under progressive hybrid censoring schemes, in Statistical Models and Methods for Biomedical and Technical Systems (eds. Vonta, F., Nikulin, M., Limnios, N., Huber-Carol), Boston Birkhauser, (2008), 323-334. |
| [6] |
H. K. T. Ng, D. Kundu, P. S. Chan, Statistical analysis of exponential lifetimes under an adaptive Type-Ⅱ progressively censoring scheme, Nav. Res. Logist., 56 (2009), 687-698. https://doi.org/10.1002/nav.20371 doi: 10.1002/nav.20371
|
| [7] |
N. Balakrishnan, D. Kundu, Hybrid censoring: inference results and applications, Comput. Stat. Data Anal., 57 (2013), 166-209. https://doi.org/10.1016/j.csda.2012.03.025 doi: 10.1016/j.csda.2012.03.025
|
| [8] |
C. T. Lin, Y. L. Huang, On progressive hybrid censored exponential distribution, J. Stat. Comput. Simul., 82 (2012), 689-709. https://doi.org/10.1080/00949655.2010.550581 doi: 10.1080/00949655.2010.550581
|
| [9] |
C. T. Lin, C. C. Chou, Y. L. Huang, Inference for the Weibull distribution with progressive hybrid censoring, Comput. Stat. Data Anal., 56 (2012), 451-467. https://doi.org/10.1016/j.csda.2011.09.002 doi: 10.1016/j.csda.2011.09.002
|
| [10] |
D. V. Lindley, Approximate Bayesian method. Trab. Estandistica, 31 (1980), 223-237. https://doi.org/10.1007/BF02888353 doi: 10.1007/BF02888353
|
| [11] |
L. Tierney, J. B. Kadane, Accurate approximations for posterior moments and marginal densities, J. Am. Stat. Assoc., 81 (1986), 82-86. https://doi.org/10.1080/01621459.1986.10478240 doi: 10.1080/01621459.1986.10478240
|
| [12] |
M. Nassar, S. G. Nassr, S. Dey, Analysis of Burr type XⅡ distribution under step stress partially accelerated life tests with type Ⅰ and adaptive type Ⅱ progressively hybrid censoring schemes, Ann. Data Sci., 4 (2017), 227-248. https://doi.org/10.1007/s40745-017-0101-8 doi: 10.1007/s40745-017-0101-8
|
| [13] |
H. Okasha, A. Mustafa, E-Bayesian estimation for the Weibull distribution under adaptive type-Ⅰ progressive hybrid censored competing risks data, Entropy, 22 (2020), 1-20. https://doi.org/10.3390/e22080903 doi: 10.3390/e22080903
|
| [14] |
A. Helu, H. Samawi, Statistical analysis based on adaptive progressive hybrid censored data from Lomax distribution, Stat. Optim. Inf. Comput., 9 (2021), 789-808. https://doi.org/10.19139/soic-2310-5070-1330 doi: 10.19139/soic-2310-5070-1330
|
| [15] |
H. Okasha, Y. Lio, M. Albassam, On reliability estimation of Lomax distribution under adaptive type-Ⅰ progressive hybrid censoring scheme, Mathematics, 9 (2021), 1-40. https://doi.org/10.3390/math9222903 doi: 10.3390/math9222903
|
| [16] |
S. K. Ashour, M. M. A. Nassar, Inference for Weibull distribution under adaptive type-Ⅰ progressive hybrid censored competing risks data, Commun. Stat. Theory Methods, 46 (2016), 4756-4773. https://doi.org/10.1080/03610926.2015.1083111 doi: 10.1080/03610926.2015.1083111
|
| [17] |
M. Nassar, S. A. Dobbah, Analysis of reliability characteristics of bathtub-shaped distribution under adaptive type-Ⅰ progressive hybrid censoring, IEEE Access, 8 (2020), 181796-181806. https://doi.org/10.1109/ACCESS.2020.3029023 doi: 10.1109/ACCESS.2020.3029023
|
| [18] |
D. R. Cox, The analysis of exponentially distributed lifetimes with two types of failure, J. R. Stat. Soc. Ser. B, 21 (1959), 411-421. https://doi.org/10.1111/j.2517-6161.1959.tb00349.x doi: 10.1111/j.2517-6161.1959.tb00349.x
|
| [19] | M. J. Crowder, Classical Competing Risks, Chapman & Hall, 2001. |
| [20] |
S. K. Ashour, M. M. A. Nassar, Analysis of exponential distribution under adaptive type-Ⅰ progressive hybrid censored competing risks data, Pak. J. Stat. Oper. Res., 10 (2014), 229- 245. https://doi.org/10.1234/pjsor.v10i2.705 doi: 10.1234/pjsor.v10i2.705
|
| [21] |
A. S. Hassan, S. G. Nassr, S. Pramanik, S. S. Maiti, Estimation in constant stress partially accelerated life tests for Weibull distribution based on censored competing risks data, Ann. Data Sci., 7 (2020), 45-62. https://doi.org/10.1007/s40745-019-00226-3 doi: 10.1007/s40745-019-00226-3
|
| [22] | S. G. Nassr, E. M. Almetwally, W. S. Abu El Azm, Statistical inference for the extended Weibull distribution based on adaptive type Ⅱ progressive hybrid censored competing risks data, Thail. Stat., 19 (2021), 547-564. |
| [23] | A. Z, Keller, A. R. R. Kamath, Alternative reliability models for mechanical systems, in Proceeding of the third international conference on reliability and maintainability, (1982), 411-415. |
| [24] |
P. Erto, M. Rapone, Non-informative and practical Bayesian confidence bounds for reliable life in the Weibull model, Reliab. Eng., 7 (1984), 181-191. https://doi.org/10.1016/0143-8174(84)90016-7 doi: 10.1016/0143-8174(84)90016-7
|
| [25] |
R. Calabria, G. Pulcini, Bayesian 2-sample prediction for the inverse Weibull distribution, Commun. Stat. Theory Methods, 23 (1994), 1811-1824. https://doi.org/10.1080/03610929408831356 doi: 10.1080/03610929408831356
|
| [26] |
M. Maswadah, Conditional confidence interval estimation for the inverse Weibull distribution based on censored generalized order statistics, J. Stat. Comput. Simul., 73 (2003), 887-898. https://doi.org/10.1080/0094965031000099140 doi: 10.1080/0094965031000099140
|
| [27] |
B. O. Oluyede, T. Yang, Generalizations of the inverse Weibull and related distributions with applications, Electron. J. Appl. Stat. Anal., 7 (2014), 94-116. https://doi.org/10.1285/i20705948v7n1p94 doi: 10.1285/i20705948v7n1p94
|
| [28] |
D. Kundu, H. Howlader, Bayesian inference and prediction of the inverse Weibull distribution for type-Ⅱ censored data, Comput. Stat. Data Anal., 54 (2010), 1547-1558. https://doi.org/10.1016/j.csda.2010.01.003 doi: 10.1016/j.csda.2010.01.003
|
| [29] |
R. Musleh, A. Helu, Estimation of the inverse Weibull distribution based on progressively censored data: Comparative study, Reliab. Eng. Syst. Saf., 131 (2014), 216-227. https://doi.org/10.1016/j.ress.2014.07.006 doi: 10.1016/j.ress.2014.07.006
|
| [30] |
K. S. Sultan, N. H. Alsadat, D. Kundu, Bayesian and maximum likelihood estimations of the inverse Weibull parameters under progressive type-Ⅱ censoring, J. Stat. Comput. Simul., 84 (10) (2014), 2248-2265. https://doi.org/10.1080/00949655.2013.788652 doi: 10.1080/00949655.2013.788652
|
| [31] |
X. Peng, Z. Yan, Bayesian estimation and prediction for the inverse Weibull distribution under general progressive censoring, Commun. Stat. Theory Methods, 45 (2016), 624-635. https://doi.org/10.1080/03610926.2013.834452 doi: 10.1080/03610926.2013.834452
|
| [32] |
A. S. Hassan, S. G. Nassr, The inverse Weibull generator of distribution: properties and applications, J. Data Sci., 16 (2018), 723-742. https://doi.org/10.6339/JDS.201810_16(4).00004 doi: 10.6339/JDS.201810_16(4).00004
|
| [33] |
A. C. Cohen, Maximum likelihood estimation in the Weibull distribution based on complete and censored samples, Technometrics, 5 (1965), 327-329. https://doi.org/10.1080/00401706.1965.10490300 doi: 10.1080/00401706.1965.10490300
|
| [34] |
S. Dey, S. Singh, Y. M. Tripathi, A. Asgharzadeh, Estimation and prediction for a progressively censored generalized inverted exponential distribution, Stat. Methodol., 132 (2016), 185-202. https://doi.org/10.1016/j.stamet.2016.05.007 doi: 10.1016/j.stamet.2016.05.007
|
| [35] |
N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, E. Teller, Equation of state calculations by fast computing machines, J. Chem Phys., 21 (1953), 1087-1091. https://doi.org/10.1063/1.1699114 doi: 10.1063/1.1699114
|
| [36] | C. P. Robert, G. Casella, Monte carlo statistical methods, Springier, 2004. |
| [37] | D. V. Ravenzwaaij, P. Cassey, S. D. Brown, A simple introduction to Markov Chain Monte-Carlo sampling, Psychon. Bull. Rev., 25 (2018), 143-154. https://doi.org/0.3758/s13423-016-1015-8 |
| [38] |
M. H. Chen, Q. M. Shao, Monte Carlo estimation of Bayesian credible and HPD intervals, J. Comput. Graph. Stat., 8 (1999), 69-92. https://doi.org/10.1080/10618600.1999.10474802 doi: 10.1080/10618600.1999.10474802
|
| [39] |
S. Dey, B. Pradhan, Generalized inverted exponential distribution under hybrid censoring, Stat. Methodol., 18 (2014), 101-114. https://doi.org/10.1016/j.stamet.2013.07.007 doi: 10.1016/j.stamet.2013.07.007
|
| [40] |
D. G. Hoel, A representation of mortality data by competing risks, Biometrics, 28 (1972), 475-488. https://doi.org/10.2307/2556161 doi: 10.2307/2556161
|


Figures(3) / Tables(7)

Wael S. Abu El Azm, Ramy Aldallal, Hassan M. Aljohani, Said G. Nassr. Estimations of competing lifetime data from inverse Weibull distribution under adaptive progressively hybrid censored[J]. Mathematical Biosciences and Engineering, 2022, 19(6): 6252-6275. doi: 10.3934/mbe.2022292







 DownLoad:
DownLoad: