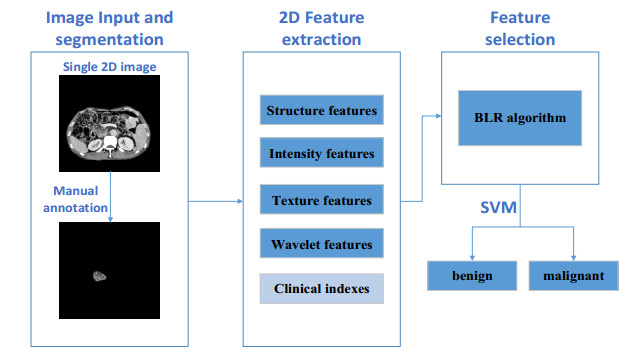
In clinical practice, differentiating benign from malignant intraductal papillary mucinous neoplasm (IPMN) and mucinous cystic neoplasm (MCN) preoperatively is crucial for deciding future treating algorithm. However, it remains challenging as benign and malignant lesions usually show similarities in both imaging appearances and clinical indices. Therefore, a robust and accurate computer-aided diagnosis (CAD) system based on radiomics and clinical indices was proposed in this paper to solve this dilemma. In the proposed CAD system, 107 patients were enrolled, where 90 cases were randomly selected for the training set with 5-fold cross validation to build the diagnostic model, while 17 cases were remained for an independent testing set to validate the performance. 436 high-throughput radiomics features while 9 clinical indices were designed and extracted. A novel feature selection algorithm named BLR (Bootstrapping repeated LASSO with Random selections) was proposed to select the most effective features. Then the selected features were sent to Support Vector Machine (SVM) to differentiate the benign or malignant. In the cross-validation cohort and independent testing cohort, the area under receiver operating characteristic curve (AUC) of CAD scheme were 0.83 and 0.92, respectively. The results fully prove the proposed CAD system achieves significant effect in tumors diagnosis.
Citation: Chengkang Li, Ran Wei, Yishen Mao, Yi Guo, Ji Li, Yuanyuan Wang. Computer-aided differentiates benign from malignant IPMN and MCN with a novel feature selection algorithm[J]. Mathematical Biosciences and Engineering, 2021, 18(4): 4743-4760. doi: 10.3934/mbe.2021241
In clinical practice, differentiating benign from malignant intraductal papillary mucinous neoplasm (IPMN) and mucinous cystic neoplasm (MCN) preoperatively is crucial for deciding future treating algorithm. However, it remains challenging as benign and malignant lesions usually show similarities in both imaging appearances and clinical indices. Therefore, a robust and accurate computer-aided diagnosis (CAD) system based on radiomics and clinical indices was proposed in this paper to solve this dilemma. In the proposed CAD system, 107 patients were enrolled, where 90 cases were randomly selected for the training set with 5-fold cross validation to build the diagnostic model, while 17 cases were remained for an independent testing set to validate the performance. 436 high-throughput radiomics features while 9 clinical indices were designed and extracted. A novel feature selection algorithm named BLR (Bootstrapping repeated LASSO with Random selections) was proposed to select the most effective features. Then the selected features were sent to Support Vector Machine (SVM) to differentiate the benign or malignant. In the cross-validation cohort and independent testing cohort, the area under receiver operating characteristic curve (AUC) of CAD scheme were 0.83 and 0.92, respectively. The results fully prove the proposed CAD system achieves significant effect in tumors diagnosis.

| [1] |
K. Tulla, A. Maker, Can we better predict the biologic behavior of incidental IPMN? A comprehensive analysis of molecular diagnostics and biomarkers in intraductal papillary mucinous neoplasms of the pancreas, Langenbecks Arch. Surg., 403 (2018), 151-194. doi: 10.1007/s00423-017-1644-z

|
| [2] |
M. Daude, F. Muscari, C. Buscail, N. Carrere, P. Otal, J. Selves, et al., Outcomes of nonresected main-duct intraductal papillary mucinous neoplasms of the pancreas, World J. Gastroenterol., 21 (2015), 2658-2667. doi: 10.3748/wjg.v21.i9.2658
|
| [3] | J. Farrell, Prevalence, diagnosis and management of pancreatic cystic neoplasms: current status and future directions, Gut Liver, 9 (2015), 571-589. |
| [4] |
K. Ohta, M. Tanada, Y. Sugawara, N. Teramoto, H. Iguchi, Usefulness of positron emission tomography (pet)/contrast-enhanced computed tomography (ce-ct) in discriminating between malignant and benign intraductal papillary mucinous neoplasms (ipmns), Pancreatology, 17 (2017), 911-919. doi: 10.1016/j.pan.2017.09.010
|
| [5] |
S. Choi, J. Kim, M. Yu, H. Eun, H. Lee, J. Han, Diagnostic performance and imaging features for predicting the malignant potential of intraductal papillary mucinous neoplasm of the pancreas: a comparison of eus, contrast-enhanced ct and mri, Abdom. Radiol., 42 (2017), 1449-1458. doi: 10.1007/s00261-017-1053-3
|
| [6] |
D. D. D. Brennan, G. A. Zamboni, V. D. Raptopoulos, J. B. Kruskal, Comprehensive preoperative assessment of pancreatic adenocarcinoma with 64-section volumetric CT, Radiographics, 27 (2007), 1653-1666. doi: 10.1148/rg.276075034
|
| [7] |
M. Tanaka, C. F. Castillo, V. Adsay, S. Chari, M. Falconi, J. Y. Jang, et al., International consensus guidelines 2012 for the management of IPMN and MCN of the pancreas, Pancreatology, 12 (2012), 183-197. doi: 10.1016/j.pan.2012.04.004
|
| [8] |
M. Tanaka, S. Chari, V. Adsay, F. Castillo, M. Falconi, M. Shimizu, et al., International consensus guidelines for management of intraductal papillary mucinous neoplasms and mucinous cystic neoplasms of the pancreas, Pancreatology, 6 (2006), 17-32. doi: 10.1159/000090023
|
| [9] |
Y. Gu, C. Lan, H. Pei, S. N. Yang, F. Y. Liu, L. L. Xiao, Applicative value of serum CA19-9, CEA, CA125 and CA242 in diagnosis and prognosis for patients with pancreatic cancer treated by concurrent chemoradiotherapy, Asian Pac. J. Cancer Prev., 16 (2015), 6569-6573. doi: 10.7314/APJCP.2015.16.15.6569
|
| [10] |
C. Jayasree, M. Abhishek, G. Lior, A. Marc, L. Liana, A. Peter, et al., CT radiomics to predict high risk intraductal papillary mucinous neoplasms of the pancreas, Med. Phys., 45 (2018), 5019-5029. doi: 10.1002/mp.13159
|
| [11] |
S. Park, L. C. Chu, R. Hruban, B. Vogelstein, K. W. Kinzler, A. L. Yuille, et al., Differentiating autoimmune pancreatitis from pancreatic ductal adenocarcinoma with CT radiomics features, Diagn. Interventional Imaging, 101 (2020), 555-564. doi: 10.1016/j.diii.2020.03.002
|
| [12] |
Y. Zhang, C. Cheng, Z. Liu, L. Wang, G. Pan, G. Sun, et al., Radiomics analysis for the differentiation of autoimmune pancreatitis and pancreatic ductal adenocarcinoma in 18F-FDG PET/CT, Med. Phys., 46 (2019), 4520-4530. doi: 10.1002/mp.13733
|
| [13] | R. Wei, K. Lin, W. Yan, Y. Guo, Y. Wang, J. Li, et al., Computer-aided diagnosis of pancreas serous cystic neoplasms: a radiomics method on preoperative MDCT images, Technol. Cancer Res. Treat., 18 (2019), 1-9. |
| [14] |
D. Sahani, A. Kambadakone, M. Macari, N. Takahashi, S. Chari, F. Castillo, Diagnosis and management of cystic pancreatic lesions, Am. J. Roentgenol., 200 (2013), 343-354. doi: 10.2214/AJR.12.8862
|
| [15] |
Y. Chou, C. Tiu, G. Hung, S. Wu, T. Chang, H. Chiang, Stepwise logistic regression analysis of tumor contour features for breast ultrasound diagnosis, Ultrasound Med. Biol., 27 (2001), 1493-1498. doi: 10.1016/S0301-5629(01)00466-5
|
| [16] |
Y. Guo, Y. Hu, M. Qiao, Y. Wang, J. Yu, J. Li, et al., Radiomics analysis on ultrasound for prediction of biologic behavior in breast invasive ductal carcinoma, Clin. Breast Cancer, 18 (2018), e335-e344. doi: 10.1016/j.clbc.2017.08.002
|
| [17] | R. Haralick, K. Shanmugam, I. Dinstein, Textural features for image classification, IEEE Trans. Syst. Man Cybern., 3 (1973), 610-621. |
| [18] | M. Galloway, Texture analysis using gray level run lengths, NASA STI/Recon Tech. Rep. N, 4 (1975), 172-179. |
| [19] |
G. Thibault, B. Fertil, C. Navarro, S. Pereira, P. Cau, N. Levy, et al., Shape and texture indices application to cell nuclei classification, Int. J. Pattern Recognit. Artif. Intell., 27 (2013), 1357002. doi: 10.1142/S0218001413570024
|
| [20] |
M. Amadasun, R. King, Textural features corresponding to textural properties, IEEE Trans. Syst. Man Cybern., 19 (1989), 1264-1274. doi: 10.1109/21.44046
|
| [21] | A. Dalalyan., M. Hebiri, J. Lederer, On the prediction performance of the Lasso, Bernoulli, 23 (2017), 552-581. |
| [22] | H. Richard, R. Patricia, R. Vincent, Lasso and probabilistic inequalities for multivariate point processes, Bernoulli, 21 (2015), 83-143. |






Figures(7) / Tables(9)

Chengkang Li, Ran Wei, Yishen Mao, Yi Guo, Ji Li, Yuanyuan Wang. Computer-aided differentiates benign from malignant IPMN and MCN with a novel feature selection algorithm[J]. Mathematical Biosciences and Engineering, 2021, 18(4): 4743-4760. doi: 10.3934/mbe.2021241







 DownLoad:
DownLoad: