Citation: Giuseppina Albano. Detecting time-changes in $ PM_{10} $ during Covid pandemic by means of an Ornstein Uhlenbeck type process[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 888-903. doi: 10.3934/mbe.2021047

| [1] | G. He, Y. Pan, T. Tanaka, The short-term impacts of COVID-19 lockdown on urban air pollution in China, Nat. Sustain., 3 (2020). |
| [2] |
X. Wu, R. C. Nethery, B. M. Sabath, D. Braun, F. Dominici, Air pollution and COVID-19 mortality in the United States: Strengths and limitations of an ecological regression analysis, Sci. Adv., 6 (2020), 1005–1011. doi: 10.1126/sciadv.abb1005

|
| [3] | Y. Han, J. C. Lam, V. O. Li, P. Guo, Q. Zhang, A. Wang, et al., The effects of outdoor air pollution concentrations and lockdowns on Covid-19 infections in Wuhan and other provincial capitals in China, preprints, (2020), 2020030364. Available from: https://www.preprints.org/manuscript/202003.0364/v1 |
| [4] |
G. Albano, V. Giorno, Inferring time non-homogeneous Ornstein Uhlenbeck type stochastic process, Comput. Stat. Data Anal., 150 (2020), 107008–107008. doi: 10.1016/j.csda.2020.107008
|
| [5] |
G. Albano, V. Giorno, On short-term loan interest rate models: a first passage time approach, Mathematics, 6 (2018), 70. doi: 10.3390/math6050070
|
| [6] | V. Linetsky, Computing hitting time densities for CIR and OU diffusions: Applications to mean reverting models, J. Comput. Financ., 4 (2004), 1–22. |
| [7] |
S. Ditlevsen, P. Lánský, Estimation of the input parameters in the Ornstein-Uhlenbeck neuronal model, Phys. Rev. E, 71 (2005), 011907. doi: 10.1103/PhysRevE.71.011907
|
| [8] |
H. Tuckwell, F. Wan, J. P. Rospars, A spatial stochastic neuronal model with Ornstein–Uhlenbeck input current, Biol. Cybern., 86 (2002), 137–145. doi: 10.1007/s004220100283
|
| [9] | G. Albano, V. Giorno, P. Román-Pomán, F. Torres-Ruiz, On a non-homogeneous Gompertz-type diffusion process: inference and first passage time, in LNCS 10672 (eds. R. Moreno-Díaz et al.), Springer (2018), 47–54. |
| [10] |
A. Buonocore, L. Caputo, A. G. Nobile, E. Pirozzi, Restricted ornstein uhlenbeck process and applications in neuronal models with periodic input signals, J. Comput. Appl. Math., 285 (2015), 59–71. doi: 10.1016/j.cam.2015.01.042
|
| [11] |
V. Giorno, S. Spina, On the return process with refractoriness for non-homogeneous Ornstein-Uhlenbeck neuronal model, Math. Biosci. En., 11 (2014), 285–302. doi: 10.3934/mbe.2014.11.285
|
| [12] |
R. Gutiérrez, R. Gutiérrez-Sánchez, A. Nafidi, A. Pascual, Detection, modelling and estimation of non linear trends by using a non-homogeneous Vasicek stochastic diffusion. Application to $CO_2 $ emissions in Morocco, Stoch. Environ. Res. Risk Assess., 26 (2012), 533–543. doi: 10.1007/s00477-011-0499-z
|
| [13] |
G. Albano, V. Giorno, Inference on the effect of non homogeneous inputs in Ornstein Uhlenbeck neuronal modeling, Math. Biosci. Eng., 17 (2020), 328–348. doi: 10.3934/mbe.2020018
|
| [14] |
D. W. K. Andrews, R. C. Fair, Inference in nonlinear econometric models with structural change, Rev. Econ. Stud., 55 (1988), 615–639. doi: 10.2307/2297408
|
| [15] | E. Hansen, Approximate asymptotic $p$ values for structural-change tests, J. Bus. Econ. Stat., 15 (1997), 60–67. |
| [16] |
M. L. Parrella, G. Albano, M. La Rocca, C. Perna, Reconstructing missing data sequences in multivariate time series: an application to environmental data, Stat. Methods Appl., 28 (2019), 359–383. doi: 10.1007/s10260-018-00435-9
|
| [17] |
G. Albano, V. Giorno, P. Román-Pomán, S. Román-Pomán, J. J. Serrano-Pérez, F. Torres-Ruiz, Inference on an heteroscedastic Gompertz tumor growth model, Math. Biosci., 328 (2020), 108428. doi: 10.1016/j.mbs.2020.108428
|
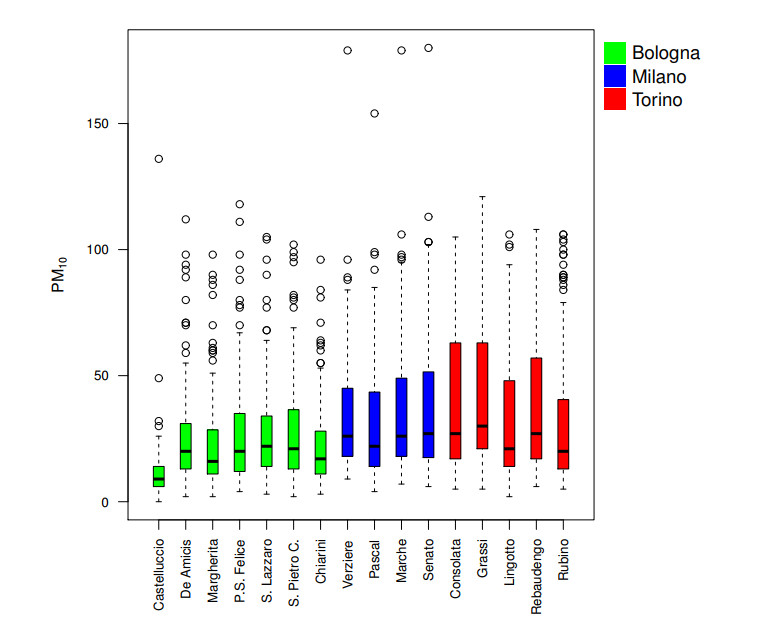
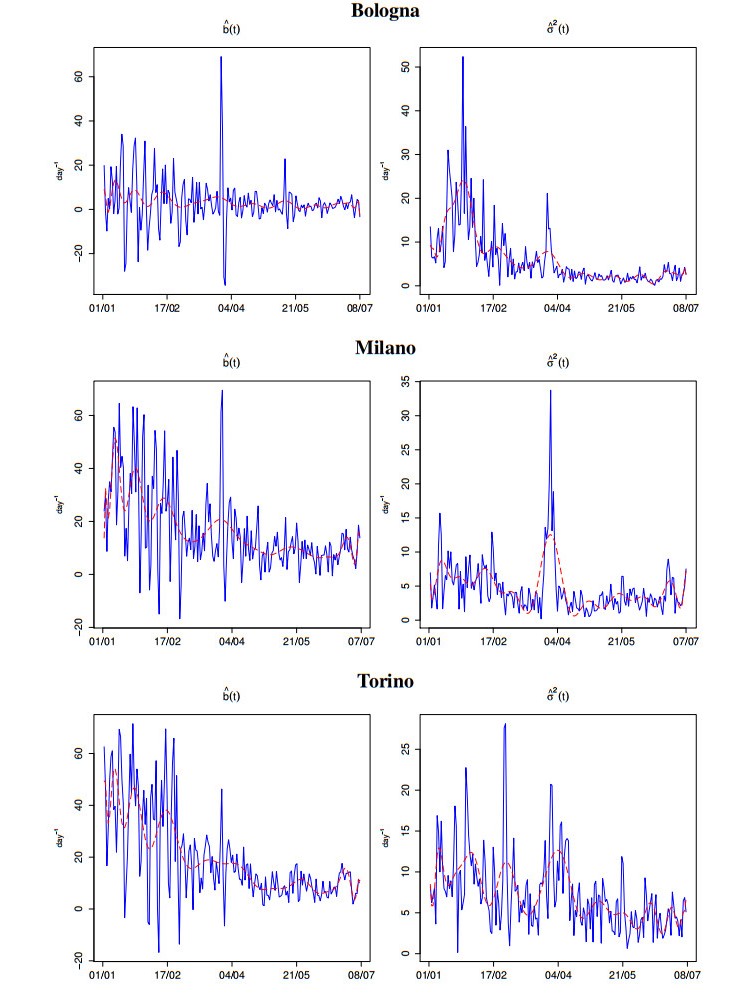
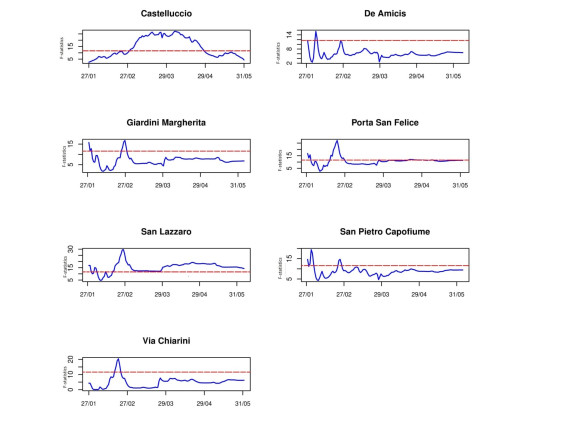
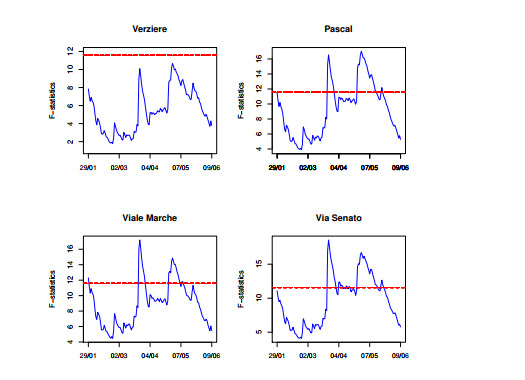
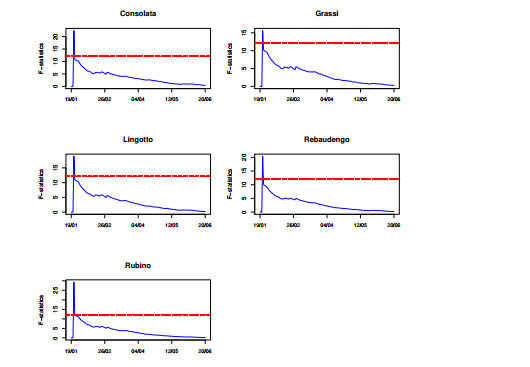
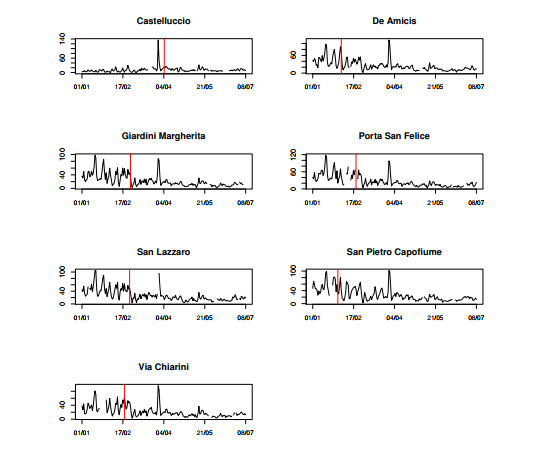
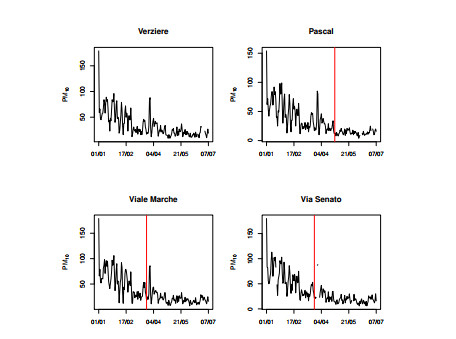
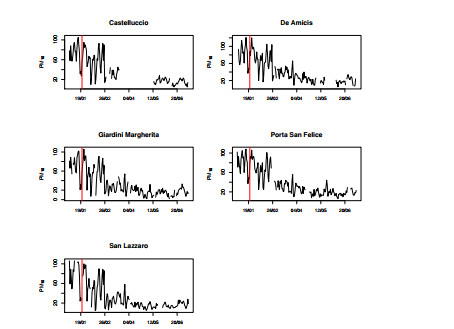
Figures(9) / Tables(2)

Giuseppina Albano. Detecting time-changes in $ PM_{10} $ during Covid pandemic by means of an Ornstein Uhlenbeck type process[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 888-903. doi: 10.3934/mbe.2021047







 DownLoad:
DownLoad: