Citation: Haifeng Song, Weiwei Yang, Songsong Dai, Haiyan Yuan. Multi-source remote sensing image classification based on two-channel densely connected convolutional networks[J]. Mathematical Biosciences and Engineering, 2020, 17(6): 7353-7377. doi: 10.3934/mbe.2020376

| [1] |
X. Yang, Y. Ye, X. Li, R. Y. K. Lau, X. Zhang, X. Huang, Hyperspectral image classification with deep learning models, IEEE Trans. Geosci. Remote Sens., 56 (2018), 5408-5423. doi: 10.1109/TGRS.2018.2815613

|
| [2] |
J. A. Benediktsson, I. Kanellopoulos, Classification of multisource and hyperspectral data based on decision fusion, IEEE Trans. Geosci. Remote Sens., 37 (1999), 1367-1377. doi: 10.1109/36.763301
|
| [3] |
B. Chen, B. Huang, B. Xu, Multi-source remotely sensed data fusion for improving land cover classification, Isprs J. Photogramm. Remote Sens., 124 (2017), 27-39. doi: 10.1016/j.isprsjprs.2016.12.008
|
| [4] |
Z. Mahmood, M. A. Akhter, G. Thoonen, P. Scheunders, Contextual subpixel mapping of hyperspectral images making use of a high resolution color image. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 6 (2013), 779-791. doi: 10.1109/JSTARS.2012.2236539
|
| [5] |
D. G. Goodenough, A. Dyk, K. O. Niemann, J. S. Pearlman, H. Chen, T. Han, et al., Processing hyperion and ali for forest classification, IEEE Trans. Geosci. Remote Sens., 41 (2003), 1321- 1331. doi: 10.1109/TGRS.2003.813214
|
| [6] |
D. G. Stavrakoudis, E. Dragozi, I. Z. Gitas, C. Karydas, Decision fusion based on hyperspectral and multispectral satellite imagery for accurate forest species mapping, Remote Sens., 6 (2014), 6897-6928. doi: 10.3390/rs6086897
|
| [7] | T. Kattenborn, J. Maack, F. E. Fassnacht, F. Enssle, Corrigendum to mapping forest biomass from space fusion of hyperspectraleo1-hyperion data and tandem-x and worldview-2 canopy heightmodels [Int. J. Appl. Earth Obs. Geoinf. Issue no. 35 (2015) 359-367]. Int. J. Appl. Earth Obs. Geoinf., 41 (2014). |
| [8] |
S. Delalieux, P. J. Zarco-Tejada, L. Tits, M. A. Jimenez Bello, D. Intrigliolo, B. Somers, Unmixing-based fusion of hyperspatial and hyperspectral airborne imagery for early detection of vegetation stress, IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 7 (2014), 2571-2582. doi: 10.1109/JSTARS.2014.2330352
|
| [9] | C. D. Packard, T. S. Viola, M. D. Klein. Hyperspectral target detection analysis of a cluttered scene from a virtual airborne sensor platform using muses, Proceedings of Target and Background Signatures, 2017. |
| [10] |
J. R. Kaufman, M. T. Eismann, M. Celenk, Assessment of spatialspectral feature-level fusion for hyperspectral target detection, IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 8 (2015), 2534-2544. doi: 10.1109/JSTARS.2015.2420651
|
| [11] |
N. B. Chang, B. Vannah, Y. J. Yang, Comparative sensor fusion between hyperspectral and multispectral satellite sensors for monitoring microcystin distribution in lake erie, IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 7 (2014), 2426-2442. doi: 10.1109/JSTARS.2014.2329913
|
| [12] |
M. Dalponte, L. Bruzzone, D. Gianelle, Fusion of hyperspectral and lidar remote sensing data for classification of complex forest areas, IEEE Trans. Geosci. Remote Sens., 46 (2008), 1416-1427. doi: 10.1109/TGRS.2008.916480
|
| [13] |
A. Merentitis, C. Debes, R. Heremans, Ensemble learning in hyperspectral image classification: Toward selecting a favorable bias-variance tradeoff. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 7 (2014), 1089-1102. doi: 10.1109/JSTARS.2013.2295513
|
| [14] |
C. Debes, A. Merentitis, R. Heremans, J. Hahn, N. Frangiadakis, T. van Kasteren, et al., Hyperspectral and lidar data fusion: Outcome of the 2013 grss data fusion contest, IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 7 (2014), 2405-2418. doi: 10.1109/JSTARS.2014.2305441
|
| [15] | C. Chen, X. Fan, C. Zheng, L. Xiao, M. Cheng, C. Wang, Sdcae: Stack denoising convolutional autoencoder model for acc, 2018 Sixth International Conference on Advanced Cloud and Big Data (CBD), 2018. |
| [16] | A. Krizhevsky, I. Sutskever, G. Hinton, Imagenet classification with deep convolutional neural networks, Advances in neural information processing systems, 2012. |
| [17] |
Y. Chen, Z. Lin, X. Zhao, G. Wang, Y. Gu, Deep learning-based classification of hyperspectral data, IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 7 (2014), 2094-2107. doi: 10.1109/JSTARS.2014.2329330
|
| [18] |
X. Ma, H. Wang, J. Geng, Spectralspatial classification of hyperspectral image based on deep auto-encoder, IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 9 (2016), 4073-4085. doi: 10.1109/JSTARS.2016.2517204
|
| [19] | A. Mughees, L. Tao. Efficient deep auto-encoder learning for the classification of hyperspectral images, In 2016 International Conference on Virtual Reality and Visualization (ICVRV), 2016. |
| [20] | J. Leng, T. Li, G. Bai, Q. Dong, D. Han. Cube-cnn-svm: A novel hyperspectral image classification method, In 2016 IEEE 28th International Conference on Tools with Artificial Intelligence (ICTAI), 2016. |
| [21] |
Y. Li, H. Zhang, Q. Shen, Spectralspatial classification of hyperspectral imagery with 3d convolutional neural network, Remote Sens., 9 (2017), 67. doi: 10.3390/rs9010067
|
| [22] |
J. Yue, W. Zhao, S. Mao, and H. Liu, Spectral-spatial classification of hyperspectral images using deep convolutional neural networks. Remote Sens. Lett., 6 (2015), 468-477. doi: 10.1080/2150704X.2015.1047045
|
| [23] |
W. Zhao, S. Du. Spectralspatial feature extraction for hyperspectral image classification: A dimension reduction and deep learning approach, IEEE Trans. Geosci. Remote Sens., 54 (2016), 4544-4554. doi: 10.1109/TGRS.2016.2543748
|
| [24] |
A. Santara, K. Mani, P. Hatwar, A. Singh, A. Garg, K. Padia, et al., Bass net: Band-adaptive spectral-spatial feature learning neural network for hyperspectral image classification, IEEE Trans. Geosci. Remote Sens., 55 (2017), 5293-5301. doi: 10.1109/TGRS.2017.2705073
|
| [25] |
Y. Chen, H. Jiang, C. Li, X. Jia, P. Ghamisi, Deep feature extraction and classification of hyperspectral images based on convolutional neural networks, IEEE Trans. Geosci. Remote Sens., 54 (2016), 6232-6251. doi: 10.1109/TGRS.2016.2584107
|
| [26] |
S. Wu, S. Zhong, Y. Liu, Deep residual learning for image steganalysis, Multimedia Tools Appl., 77 (2018), 10437-10453. doi: 10.1007/s11042-017-4476-5
|
| [27] | X. Glorot, Y. Bengio, Understanding the difficulty of training deep feedforward neural networks, Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 2010. |
| [28] |
Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proc. IEEE, 86 (1998), 2278-2324. doi: 10.1109/5.726791
|
| [29] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition. Comput. Sci., 2015 (2015), 1-14. |
| [30] | G. Huang, Z. Liu, L. van der Maaten, K. Q. Weinberger, Densely connected convolutional networks, 2018 IEEE Conference on Computer Vision and Pattern Recognition, 2017. |
| [31] | S. Ioffe, C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, Proceedings of the 32nd International Conference on Machine Learning, 2015. |
| [32] | G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, R. R. Salakhutdinov, Improving neural networks by preventing co-adaptation of feature detectors, Comput. Sci., 2012 (2012), 212-223. |
| [33] | W. Hu, Y. Huang, L. Wei, F. Zhang, H. Li, Deep convolutional neural networks for hyperspectral image classification, J. Sensors, 2015(2015):112, 2015. |
| [34] |
W. Jing, S. Huo, Q. Miao, X. Chen, A model of parallel mosaicking for massive remote sensing images based on spark, IEEE Access, 5 (2017), 18229-18237. doi: 10.1109/ACCESS.2017.2746098
|
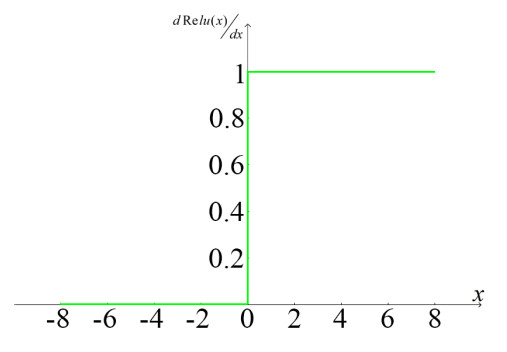
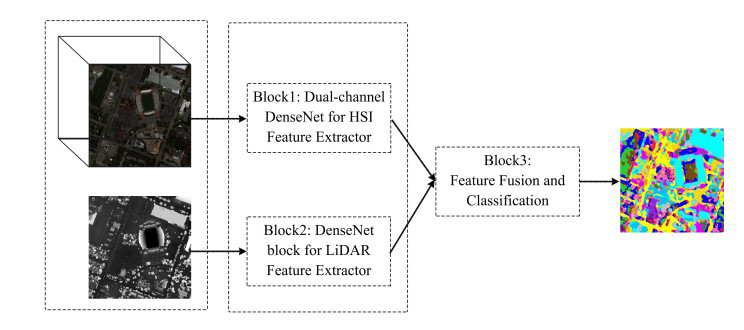
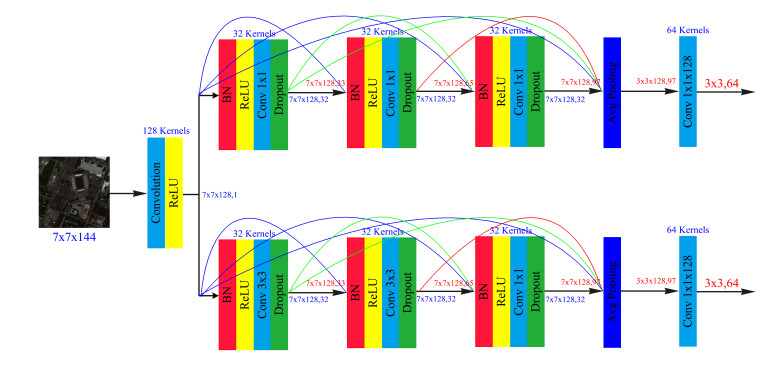
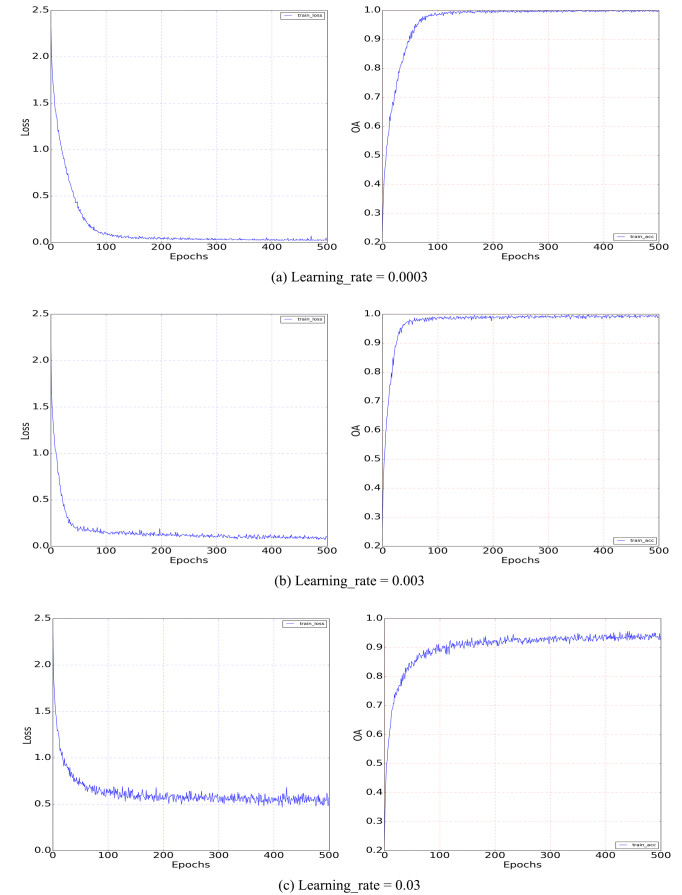
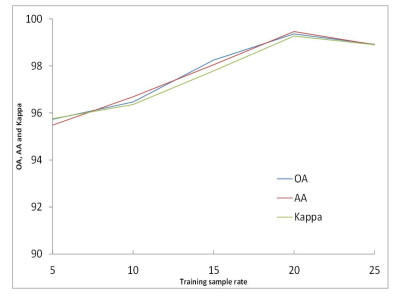

Figures(15) / Tables(5)

Haifeng Song, Weiwei Yang, Songsong Dai, Haiyan Yuan. Multi-source remote sensing image classification based on two-channel densely connected convolutional networks[J]. Mathematical Biosciences and Engineering, 2020, 17(6): 7353-7377. doi: 10.3934/mbe.2020376







 DownLoad:
DownLoad: