Citation: Agustín Halty, Rodrigo Sánchez, Valentín Vázquez, Víctor Viana, Pedro Piñeyro, Daniel Alejandro Rossit. Scheduling in cloud manufacturing systems: Recent systematic literature review[J]. Mathematical Biosciences and Engineering, 2020, 17(6): 7378-7397. doi: 10.3934/mbe.2020377

| [1] |
L. Atzori, A. Iera, G. Morabito, The internet of things: A survey, Comp. Netw., 54 (2010), 2787-2805. doi: 10.1016/j.comnet.2010.05.010

|
| [2] | P. Mell, T. Grance, The nist definition of cloud computing, 2011. |
| [3] | P. Wang, R. X. Gao, Z. Fan, Cloud computing for cloud manufacturing: Benefits and limitations, J. Manufac. Sci. Eng., 137 (2015), 1-9. |
| [4] | B. Li, L. Zhang, S. Wang, F. Tao, J. W. Cao, X. D. Jiang, et al., Cloud manufacturing: A new service-oriented networked manufacturing model, Compu. Inte. Manufac. Sys., 16 (2010), 1-7. |
| [5] |
X. Xu, From cloud computing to cloud manufacturing, Compu. Inte. Manufac. Sys., 28 (2012), 75-86. doi: 10.1016/j.rcim.2011.07.002
|
| [6] | Y. Yang, Y. D. Cai, Q. Lu, Y. Zhang, S. Koric, C. Shao, High-performance computing based big data analytics for smart manufacturing, In: ASME 2018 13th International Manufacturing Science and Engineering Conference. American Society of Mechanical Engineers Digital Collection, (2018). |
| [7] | L. Wang, X. V. Wang, Cloud-based cyber-physical systems in manufacturing, 1st edition, SpringerVerlag, 2018. |
| [8] |
Y. Liu, L. Wang, X. Wang, X. Xu, P. Jiang, Cloud manufacturing: key issues and future perspectives, Int. J. Compu. Inte. Manufac., 32 (2019), 858-874. doi: 10.1080/0951192X.2019.1639217
|
| [9] |
Y. Liu, L. Wang, X. V. Wang, Cloud manufacturing: Latest advancements and future trends, Proc. Manufac., 25 (2018), 62-73. doi: 10.1016/j.promfg.2018.06.058
|
| [10] |
D. Wu, D. W. Rosen, L. Wang, D. Schaefer, Cloud-based design and manufacturing: A new paradigm in digital manufacturing and design innovation, Compu. Aided Des., 59 (2015), 1-14. doi: 10.1016/j.cad.2014.07.006
|
| [11] |
Y. Liu, L. Wang, X. V. Wang, X. Xu, L. Zhang, Scheduling in cloud manufacturing: State-of-theart and research challenges, Cinter. J. Prod. Res., 57 (2019), 4854-4879. doi: 10.1080/00207543.2018.1449978
|
| [12] | L. Monostori, Cyber-physical production systems: Roots, expectations and r & d challenges, Proc. CIRP, 17 (2019), 9-13. |
| [13] |
D. A. Rossit, F. Tohmé, M. Frutos, Industry 4.0: Smart scheduling, Int. J. Prod. Res., 57 (2019), 3802-3813. doi: 10.1080/00207543.2018.1504248
|
| [14] | J. Lee, B. Bagheri, H. Kao, A cyber-physical systems architecture for industry 4.0-based manufacturing systems, Manufac. Let., 3 (2018), 18-23. |
| [15] | J.Wang, L. Zhang, L. Duan, R. X. Gao, A new paradigm of cloud-based predictive maintenance for intelligent manufacturing, J. Intel. Manufac., 28 (2019), 1125-1137. |
| [16] |
Y. Zhang, Y. Cheng, X. V. Wang, R. Y. Zhong, Y. Zhang, F. Tao, Data-driven smart production line and its common factors, Int. J. Adv. Manufac. Tech., 103 (2019), 1211-1223. doi: 10.1007/s00170-019-03469-9
|
| [17] |
D. A. Rossit, F. Tohmé, M. Frutos, Production planning and scheduling in cyber-physical produc-tion systems: A review, Int. J. Compu. Inte. Manufac., 32 (2019), 385-395. doi: 10.1080/0951192X.2019.1605199
|
| [18] |
J. Wang, K. Wang, Y. Wang, Z. Huang, R. Xue, Deep boltzmann machine based condition prediction for smart manufacturing, J. Amb. Intel. Hum. Compu., 10 (2019), 851-861. doi: 10.1007/s12652-018-0794-3
|
| [19] |
J. K. Lenstra, A. R. Kan, P. Brucker, Complexity of machine scheduling problems, An. Dis. Math., 1 (1977), 343-362. doi: 10.1016/S0167-5060(08)70743-X
|
| [20] | M. Pinedo, Scheduling, 5th edition, Springer-Verlag, 2016. |
| [21] |
A. Dolgui, D. Ivanov, S. P Sethi, B. Sokolov, Scheduling in production, supply chain and industry 4.0 systems by optimal control: Fundamentals, state-of-the-art and applications, Int. J. Prod. Res., 57 (2019), 411-432. doi: 10.1080/00207543.2018.1442948
|
| [22] | D. A. Rossit, F. Tohmé, M. Frutos, A data-driven scheduling approach to smart manufacturing, J. Indus. Infor. Int., 15 (2019), 69-79. |
| [23] |
D. A. Rossit, F. Tohmé., Scheduling research contributions to smart manufacturing, Manufac. Let., 15 (2018), 111-114. doi: 10.1016/j.mfglet.2017.12.005
|
| [24] |
H. Akbaripour, M. Houshmand, T. VanWoensel, N. Mutlu, Cloud manufacturing service selection optimization and scheduling with transportation considerations: Mixed-integer programming models, Int. J. Adv. Manufac. Tech., 95 (2018), 43-70. doi: 10.1007/s00170-017-1167-3
|
| [25] | Y. Liu, L. Zhang, L. Wang, Y. Xiao, X. Xu, M. Wang, A framework for scheduling in cloud manufacturing with deep reinforcement learning, in 2019 IEEE 17th International Conference on Industrial Informatics (INDIN), 1 (2019), 1775-1780. |
| [26] | S. Lin, Y. Laili, Y. Luo, Integrated optimization of supplier selection and service scheduling in cloud manufacturing environment, in 2018 4th International Conference on Universal Village, (2018), 1-6. |
| [27] |
H. Zhu, M. Li, Y. Tang, Y. Sun, A deep-reinforcement-learning-based optimization approach for real-time scheduling in cloud manufacturing, IEEE Access, 8 (2020), 9987-9997. doi: 10.1109/ACCESS.2020.2964955
|
| [28] | M. Petticrew, H. Roberts, Systematic reviews in the social sciences: A practical guide, John Wiley & Sons, (2008). |
| [29] | R. B. Briner, D. Denyer, Systematic review and evidence synthesis as a practice and scholarship too, Handb. Evid. Manag. Comp. Class. Res., (2012), 112-129. |
| [30] | D. Denyer, D. Tranfield, Producing a systematic review, (2009). |
| [31] |
J. Delaram, O. F. Valila, A mathematical model for task scheduling in cloud manufacturing systems focusing on global logistics, Proc. Manufact., 17 (2018), 387-394. doi: 10.1016/j.promfg.2018.10.061
|
| [32] | T. Suma, R. Murugesan, Study on multi-task oriented service composition and optimization problem of customer order scheduling problem using fuzzy min-max algorithm, Int. J. Mecha. Eng. Tech., 10 (2019), 219-231. |
| [33] |
B. Vahedi-Nouri, R. Tavakkoli-Moghaddam, M. Rohaninejad, A multi-objective scheduling model for a cloud manufacturing system with pricing, equity, and order rejection, IFAC-Paper, 52 (2019), 2177-2182. doi: 10.1016/j.ifacol.2019.11.528
|
| [34] |
L. Zhang, C. Yu, T. N. Wong, Cloud-based frameworks for the integrated process planning and scheduling, Int. J. Compu. Inte. Manufac., 32 (2019), 1192-1206. doi: 10.1080/0951192X.2019.1690682
|
| [35] | D. Wang, Y. Yu, Y. Yin, T. C. E. Cheng, Multi-agent scheduling problems under multitasking, Int. J. Produc. Res., (2020), 1-31. |
| [36] |
Y. Liu, L. Wang, Y. Wang, X. V. Wang, L. Zhang, Multi-agent-based scheduling in cloud manufacturing with dynamic task arrivals, Proc. CIRP, 72 (2018), 953-960. doi: 10.1016/j.procir.2018.03.138
|
| [37] |
J. Xiao, W. Zhang, S. Zhang, X. Zhuang, Game theory-based multi-task scheduling in cloud manufacturing using an extended biogeography-based optimization algorithm, Concur. Eng., 27 (2019), 314-330. doi: 10.1177/1063293X19882744
|
| [38] | J. Chen, G. Q Huang, J. Wang, C. Yang, A cooperative approach to service booking and scheduling in cloud manufacturing, Eur. J. Oper. Res., 273(3) (2019), 861-873. |
| [39] | Z. Liu, Z. Wang, C. Yang, Multi-objective resource optimization scheduling based on iterative double auction in cloud manufacturing, Adv. Manufac., 7(4) (2019), 374-388. |
| [40] | T. Bai, S. Liu, L. Zhang, A manufacturing task scheduling method based on public goods game on cloud manufacturing model, in 2018 4th International Conference on Universal Village (UV), (2018), 1-6. |
| [41] | Z. Liu, Z.Wang, A novel truthful and fair resource bidding mechanism for cloud manufacturing, IEEE Access, 8 (2019), 28888-28901. |
| [42] |
L. Zhou, L. Zhang, Y. Laili, C. Zhao, Y. Xiao, Multi-task scheduling of distributed 3d printing services in cloud manufacturing, Int. J. Adv. Manufac. Tech., 96 (2018), 3003-3017. doi: 10.1007/s00170-017-1543-z
|
| [43] |
A. Simeone, A. Caggiano, B. N. Deng, Y. Zeng, L. Boun, Resource efficiency optimization engine in smart production networks via intelligent cloud manufacturing platforms, Proc. CIRP, 78 (2018), 19-24. doi: 10.1016/j.procir.2018.10.003
|
| [44] |
P. Helo, D. Phuong, Y. Hao, Cloud manufacturing-scheduling as a service for sheet metal manufacturing, Comp. Oper. Res., 110 (2019), 208-219. doi: 10.1016/j.cor.2018.06.002
|
| [45] | T. Suma, R. Murugesan, Artificial immune algorithm for subtask industrial robot scheduling in cloud manufacturing, In J. Phys. Conf. Ser, 1000 (2018), 1-8. |
| [46] |
L. Zhou, L. Zhang, C. Zhao, Y. Laili, L. Xu, Diverse task scheduling for individualized requirements in cloud manufacturing, Enter. Infor. Sys., 12 (2018), 300-318. doi: 10.1080/17517575.2017.1364428
|
| [47] | M. Yuan, X. Cai, Z. Zhou, C. Sun, W. Gu, J. Huang, Dynamic service resources scheduling method in cloud manufacturing environment, Int. J. Produc. Res., 11 (2019), 1-18. |
| [48] |
W. He, G. Jia, H. Zong, J. Kong, Multi-objective service selection and scheduling with linguistic preference in cloud manufacturing, Sustainability, 11 (2019), 2619. doi: 10.3390/su11092619
|
| [49] | E. Jafarnejad-Ghomi, A. M. Rahmani, N. N. Qader, Service load balancing, scheduling, and logistics optimization in cloud manufacturing by using genetic algorithm, Concu. Compu. Prac. Exper., 31 (2019), 5329. |
| [50] |
Y. Hu, F. Zhu, L. Zhang, Y. Lui, Z. Wang, Scheduling of manufacturers based on chaos optimization algorithm in cloud manufacturing, Robo. Comp. Inte. Manufac., 58 (2019), 13-20. doi: 10.1016/j.rcim.2019.01.010
|
| [51] | F. Zhang, J. Hui, B. Zhu, Y. Guo, An improved firefly algorithm for collaborative manufacturing chain optimization problem, in Proceedings of the Institution of Mechanical Engineers, Part B: Journal of Engineering Manufacture, 233 (2019), 1711-1722. |
| [52] |
W. Zhang, J. Ding, Y. Wang, S. Zhang, Z. Xiong, Multi-perspective collaborative scheduling using extended genetic algorithm with interval-valued intuitionistic fuzzy entropy weight method, J. Manufac. Sys., 53 (2019), 249-260. doi: 10.1016/j.jmsy.2019.10.002
|
| [53] |
A. Elgendy, J. Yan, M. Zhang, Integrated strategies to an improved genetic algorithm for allocating and scheduling multi-task in cloud manufacturing environment, Proc. Manufac., 39 (2019), 1872- 1879. doi: 10.1016/j.promfg.2020.01.251
|
| [54] | Y. Du, J. L.Wang, L. Lei, Multi-objective scheduling of cloud manufacturing resources through the integration of cat swarm optimization and firefly algorithm, Adv. Prod. Eng. Manag., 14 (2019). |
| [55] | H. Zhang, C. Ma, S. Zhang, S. Liu, Research on the fjss problem with discrete equipment capability in cloud manufacturing environment, Int. J. Inter. Manufac. Ser., 6 (2019), 123-138. |
| [56] |
F. Li, L. Zhang, T. W. Liao, Y. Liu, Multi-objective optimisation of multi-task scheduling in cloud manufacturing, Int. J. Prod. Res., 57 (2019), 3847-3863. doi: 10.1080/00207543.2018.1538579
|
| [57] |
E. Jafarnejad-Ghomi, A. M. Rahmani, N. N. Qader, Service load balancing, task scheduling and transportation optimisation in cloud manufacturing by applying queuing system, Enter. Infor. Sys., 13 (2019), 865-894. doi: 10.1080/17517575.2019.1599448
|
| [58] | Y. Li, G. Luo, Solving flexible job shop scheduling problem in cloud manufacturing environment based on improved genetic algorithm, in IOP Conference Series: Materials Science and Engineering, 612 (2019). |
| [59] | Y. Shi, L. Luo, H. Guang, Research on scheduling of cloud manufacturing resources based on bat algorithm and cellular automata, in 2019 IEEE International Conference on Smart Manufacturing, Industrial & Logistics Engineering (SMILE), (2019), 174-177. |
| [60] | Y. Laili, S. Lin, D. Tang, Multi-phase integrated scheduling of hybrid tasks in cloud manufacturing environment, Rob. Compu.Inte. Manufac., 61 (2020). |
| [61] |
M. M. Fazeli, Y. Farjami, M. Nickray, An ensemble optimisation approach to service composition in cloud manufacturing, Int. J. Comp. Int. Manufac., 32 (2019), 83-91. doi: 10.1080/0951192X.2018.1550679
|
| [62] |
J. Ding, Y. Wang, S. Zhang, W. Zhang, Z. Xiong, Robust and stable multi-task manufacturing scheduling with uncertainties using a two-stage extended genetic algorithm, Enter. Infor. Systems, 13 (2019), 1442-1470. doi: 10.1080/17517575.2019.1656290
|
| [63] | F. Li, W. Liao, W. Cai, L. Zhang, Multi-task scheduling in consideration of fuzzy uncertainty of multiple criteria in service-oriented manufacturing, IEEE Trans. Fuz. Sys., (2020). |
| [64] |
S. Chen, S. Fang, R. Tang, A reinforcement learning based approach for multi-projects scheduling in cloud manufacturing, Int. J. Prod. Res., 57 (2019), 3080-3098. doi: 10.1080/00207543.2018.1535205
|
| [65] | T. Dong, F. Xue, C. Xiao, J. Li, Task scheduling based on deep reinforcement learning in a cloud manufacturing environment, Concur. Comp. Prac. Exper., 32 (2020), e5654. |
| [66] | C. Morariu, O. Morariu, S. Raileanu, T. Borangiu, Machine learning for predictive scheduling and resource allocation in large scale manufacturing systems, Compu. Indus., 120 (2020), e5654. |
| [67] | L. Zhou, L. Zhang, L. Ren, Simulation model of dynamic service scheduling in cloud manufacturing, in IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, (2018), 4199-4204. |
| [68] |
L. Zhou, L. Zhang, B. R. Sarker, Y. Laili, L. Ren, An event-triggered dynamic scheduling method for randomly arriving tasks in cloud manufacturing, Int. J. Compu. Inte. Manufac., 31 (2018), 318- 333. doi: 10.1080/0951192X.2017.1413252
|
| [69] | W. He, G. Jia, H. Zong, T. Huang, Multi-objective cloud manufacturing service selection and scheduling with different objective priorities, Sustainability, 11 (2019). |
| [70] |
Y. Wang, P. Zheng, X. Xu, H. Yang, J. Zou, Production planning for cloud-based additive manufacturing-a computer vision-based approach, Robo. Compu. Inte. Manufac., 58 (2019), 145-157. doi: 10.1016/j.rcim.2019.03.003
|
| [71] | L. Zhou, L. Zhang, Y. Fang, Logistics service scheduling with manufacturing provider selection in cloud manufacturing, Robo. Compu. Inte. Manufac., 65 (2020). |
| [72] |
J.Wang, Y. Ma, L. Zhang, R. X. Gao, D.Wu, Deep learning for smart manufacturing: Methods and applications, J. Manufac. Sys., 48 (2018), 144-156. doi: 10.1016/j.jmsy.2018.01.003
|
| [73] | K. Deb, Multi-objective optimization using evolutionary algorithms, John Wiley & Sons (2001). |
| [74] |
G. E. Vieira, J. W. Herrmann, E. Lin, Rescheduling manufacturing systems: A framework of strategies, policies, and methods, J. Schedu., 6 (2003), 39-62. doi: 10.1023/A:1022235519958
|
| [75] | F. Bonomi, R. Milito, J. Zhu, S. Addepalli, Fog computing and its role in the internet of things, in Proceedings of the first edition of the MCC workshop on Mobile cloud computing, (2012), 13-16. |
| [76] | S. Yi, C. Li, Q. Li, A survey of fog computing: concepts, applications and issues, in Proceedings of the 2015 workshop on mobile big data, (2015), 37-42. |
| [77] | F. Al-Haidari, M. Sqalli, K. Salah, Impact of cpu utilization thresholds and scaling size on autoscaling cloud resources, in 2013 IEEE 5th International Conference on Cloud Computing Technology and Science, 2 (2013), 256-261. |
| [78] | K. Salah, J. M. A. Calero, S. Zeadally, S. Al-Mulla, M. Alzaabi, Using cloud computing to implement a security overlay network, IEEE Secu. Pri., 11 (2012), 44-53. |
| [79] | C. Xu, G. Zhu, Intelligent manufacturing lie group machine learning: Real-time and efficient inspection system based on fog computing, J. Intel. Manufac., 11 (2020), 1-13. |
| [80] | K. Salah, A queueing model to achieve proper elasticity for cloud cluster jobs, in 2013 IEEE Sixth International Conference on Cloud Computing, (2013), 755-761. |
| [81] |
S. El-Kafhali, K. Salah, Efficient and dynamic scaling of fog nodes for iot devices, J. Supercomp., 73 (2017), 5261-5284. doi: 10.1007/s11227-017-2083-x
|
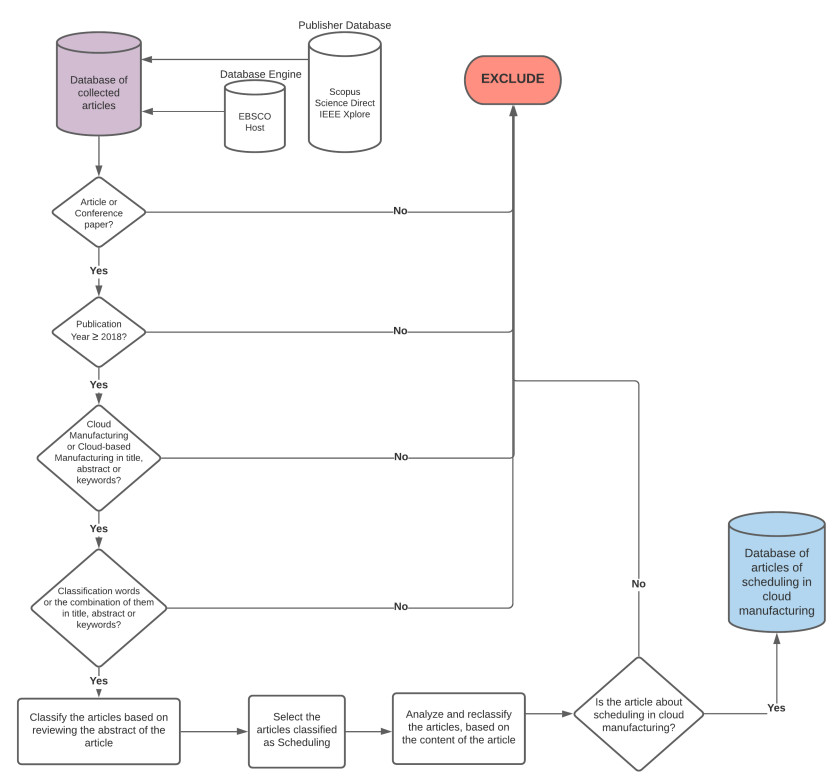
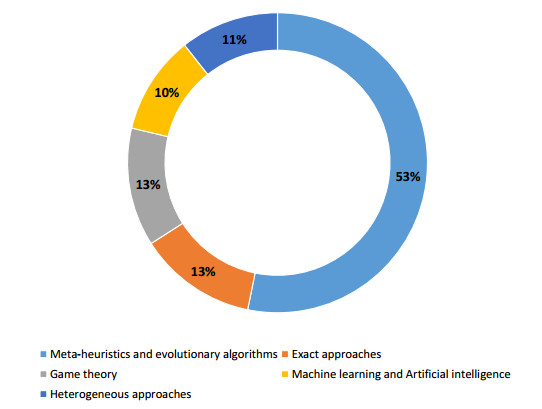
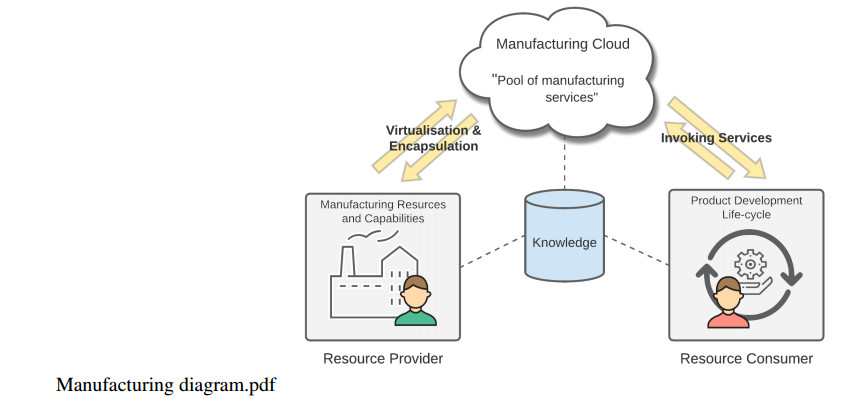
Figures(3)

Agustín Halty, Rodrigo Sánchez, Valentín Vázquez, Víctor Viana, Pedro Piñeyro, Daniel Alejandro Rossit. Scheduling in cloud manufacturing systems: Recent systematic literature review[J]. Mathematical Biosciences and Engineering, 2020, 17(6): 7378-7397. doi: 10.3934/mbe.2020377







 DownLoad:
DownLoad: