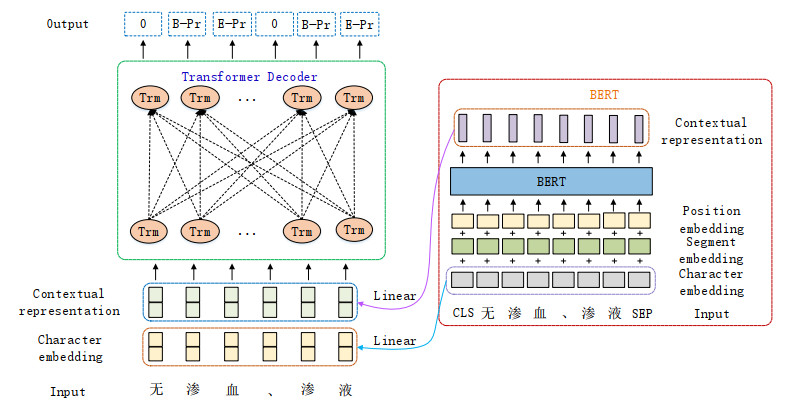
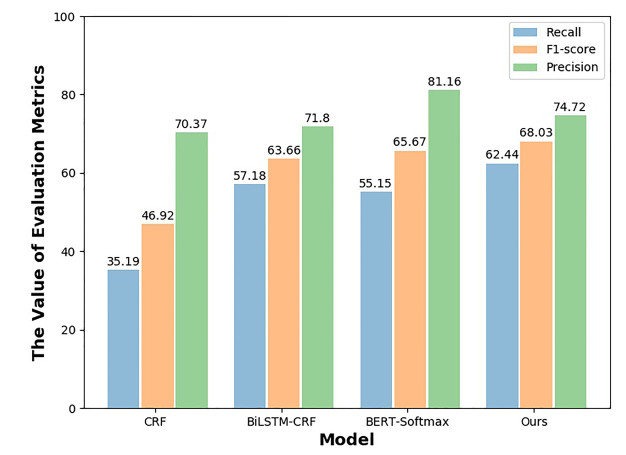
Clinical event detection (CED) is a hot topic and essential task in medical artificial intelligence, which has attracted the attention from academia and industry over the recent years. However, most studies focus on English clinical narratives. Owing to the limitation of annotated Chinese medical corpus, there is a lack of relevant research about Chinese clinical narratives. The existing methods ignore the importance of contextual information in semantic understanding. Therefore, it is urgent to research multilingual clinical event detection. In this paper, we present a novel encoder-decoder structure based on pre-trained language model for Chinese CED task, which integrates contextual representations into Chinese character embeddings to assist model in semantic understanding. Compared with existing methods, our proposed strategy can help model harvest a language inferential skill. Besides, we introduce the punitive weight to adjust the proportion of loss on each category for coping with class imbalance problem. To evaluate the effectiveness of our proposed model, we conduct a range of experiments on test set of our manually annotated corpus. We compare overall performance of our proposed model with baseline models on our manually annotated corpus. Experimental results demonstrate that our proposed model achieves the best precision of 83.73%, recall of 86.56% and F1-score of 85.12%. Moreover, we also evaluate the performance of our proposed model with baseline models on minority category samples. We discover that our proposed model obtains a significant increase on minority category samples.
Citation: Zhichang Zhang, Minyu Zhang, Tong Zhou, Yanlong Qiu. Pre-trained language model augmented adversarial training network for Chinese clinical event detection[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 2825-2841. doi: 10.3934/mbe.2020157
Clinical event detection (CED) is a hot topic and essential task in medical artificial intelligence, which has attracted the attention from academia and industry over the recent years. However, most studies focus on English clinical narratives. Owing to the limitation of annotated Chinese medical corpus, there is a lack of relevant research about Chinese clinical narratives. The existing methods ignore the importance of contextual information in semantic understanding. Therefore, it is urgent to research multilingual clinical event detection. In this paper, we present a novel encoder-decoder structure based on pre-trained language model for Chinese CED task, which integrates contextual representations into Chinese character embeddings to assist model in semantic understanding. Compared with existing methods, our proposed strategy can help model harvest a language inferential skill. Besides, we introduce the punitive weight to adjust the proportion of loss on each category for coping with class imbalance problem. To evaluate the effectiveness of our proposed model, we conduct a range of experiments on test set of our manually annotated corpus. We compare overall performance of our proposed model with baseline models on our manually annotated corpus. Experimental results demonstrate that our proposed model achieves the best precision of 83.73%, recall of 86.56% and F1-score of 85.12%. Moreover, we also evaluate the performance of our proposed model with baseline models on minority category samples. We discover that our proposed model obtains a significant increase on minority category samples.

| [1] | A. Vlachos, Evaluating and combining and biomedical named entity recognition systems, Proceedings of the Workshop on BioNLP: Biological, translational, and clinical language processing, Association for Computational Linguistics, 2007,199-206. Available from: https://dl.acm.org/doi/10.5555/1572392.1572430. |
| [2] | Z. F. Ju, J. Wang, F. Zhu, Named entity recognition from biomedical text using SVM, International Conference on Bioinformatics and Biomedical Engineering, Institute of Electrical and Electronics Engineers, 2011, 1-4. Available from: https://ieeexplore.ieee.xilesou.top/abstract/document/5779984. |
| [3] | A. McCallum, W. Li, Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons, Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL, Association for Computational Linguistics, 2003,188-191. Available from: https://dlacm.xilesou.top/doi/10.3115/1119176.1119206. |
| [4] | L. S. Li, L. K. Jin, Z. C Jiang, D. X. Song, D. G. Huang, Biomedical named entity recognition based on extended recurrent neural networks, International Conference on Bioinformatics and Biomedicine (BIBM), Institute of Electrical and Electronic Engineers Computer Society, 2015,649-652. Available from: https://ieeexplore.ieee.xilesou.top/abstract/document/7359761/authors#authors. |
| [5] | L. S. Li, Y. X. Jiang, Biomedical named entity recognition based on the two channels and sentencelevel reading control conditioned LSTM-CRF, International Conference on Bioinformatics and Biomedicine (BIBM), Institute of Electrical and Electronic Engineers Computer Society, 2017,380-385. Available from: https://ieeexplore.ieee.xilesou.top/abstract/document/8217679. |
| [6] |
B. Z. Tang, X. L. Wang, J. Yan, Q. C. Chen, Entity recognition in Chinese clinical text using attention-based CNN-LSTM-CRF, BMC Med. Inf. Decis. Making, 19 (2019), 74. doi: 10.1186/s12911-019-0787-y

|
| [7] |
X. S. Zhou, H. Q. Xiong, S. H. Zeng, X. L. Fu, J. Wu, An approach for medical event detection in Chinese clinical notes of electronic health records, BMC Med. Inf. Decis. Making, 19 (2019), 54. doi: 10.1186/s12911-019-0756-5
|
| [8] | E. Ouyang, Y. X. Li, L. Jin, Z. F. Li, X. Y. Zhang, Exploring n-gram character presentation in bidirectional RNN-CRF for Chinese clinical named entity recognition, CEUR Workshop Proceedings, Institute of Electrical and Electronic Engineers Computer Society, 2017, 37-42. Available from: http://ceur-ws.org/Vol-1976/paper07.pdf. |
| [9] | Y. F. Wang, S. Ananiadou, J. I. Tsujii, Improve Chinese clinical named entity recognition performance by using the graphical and phonetic feature, International Conference on Bioinformatics and Biomedicine (BIBM), Institute of Electrical and Electronic Engineers Computer Society, 2018, 1582-1586. Available from: https://ieeexplore.ieee.xilesou.top/abstract/document/8621201. |
| [10] | J. Devlin, M. W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, arXiv, 2018, arXiv: 1810.04805. |
| [11] | X. Wang, Y. Zhang, Q. Li, Cathy H. Wu, J. W. Han, PENNER: Pattern-enhanced nested named entity recognition in biomedical literature, International Conference on Bioinformatics and Biomedicine (BIBM), Institute of Electrical and Electronic Engineers Computer Society, 2018. Available from: https://ieeexplore.ieee.xilesou.top/abstract/document/8621485. |
| [12] |
M. Gerner, G. Nenadic, C. M. Bergman, LINNAEUS: A species name identification system for biomedical literature, BMC Bioinf., 11 (2010), 85. doi: 10.1186/1471-2105-11-85
|
| [13] | Z. H. Zhao, Z. H. Yang, L. Luo, Y. Zhang, L. Wang, H. F. Lin, et al., MLCNN: A novel deep learning based disease named entity recognition architecture, International Conference on Bioinformatics and Biomedicine (BIBM), Institute of Electrical and Electronic Engineers Computer Society, 2016,794-794. Available from: https://ieeexplore.ieee.xilesou.top/abstract/document/7822625. |
| [14] |
L. Luo, Z. H. Yang, P. Yang, Y. Zhang, L. Wang, H. F. Lin, et al., An attention-based BiLSTMCRF approach to document-level chemical named entity recognition, Bioinformatics, 34 (2018), 1381-1388. doi: 10.1093/bioinformatics/btx761
|
| [15] | P. F. Cao, Y. B. Chen, K. Liu, J. Zhao, S. P. Liu, Adversarial transfer learning for chinese named entity recognition with self-attention mechanism, Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, (2018), 182-192. Available from: https://www.aclweb.org/anthology/D18-1017/. |
| [16] | A. Johnson, P. Karanasou, J. Gaspers, D. Klakow, Cross-lingual transfer learning for Japanese named entity recognition, Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Industry Papers), Association for Computational Linguistics, 2019,182-189. Available from: https://www.aclweb.org/anthology/N19-2023/. |
| [17] | R. Leaman, C. H. Wei, C. Zou, Z. Y. Lu, Mining chemical patents with an ensemble of open systems, Database, 2016 (2016), baw065. |
| [18] | T. Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense object detection, The IEEE International Conference on Computer Vision (ICCV), 2017, 2980-2988. Available from: http://openaccess.thecvf.com/content_iccv_2017/html/Lin_Focal_Loss_for_ICCV_2017_paper.html. |
| [19] | H. Jeremy, R. Sebastian, Universal language model fine-tuning for text classification, arXiv, 2018, arXiv: 1801.06146. |
| [20] | A. Williams, N. Nangia, S. R. Bowman, A broad-coverage challenge corpus for sentence understanding through inference, arXiv, 2017, arXiv: 1704.05426. |
Figures(2) / Tables(12)

Zhichang Zhang, Minyu Zhang, Tong Zhou, Yanlong Qiu. Pre-trained language model augmented adversarial training network for Chinese clinical event detection[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 2825-2841. doi: 10.3934/mbe.2020157







 DownLoad:
DownLoad: