Citation: Yuan Tian, Biao Song, Mznah Al Rodhaan, Chen Rong Huang, Mohammed A. Al-Dhelaan, Abdullah Al-Dhelaan, Najla Al-Nabhan. A stochastic location privacy protection scheme for edge computing[J]. Mathematical Biosciences and Engineering, 2020, 17(3): 2636-2649. doi: 10.3934/mbe.2020144

| [1] | M. Satyanarayanan, The emergence of edge computing, Computer, 50 (2017), 30-39. |
| [2] | L. Xiong, Y. Shi, On the Privacy-Preserving Outsourcing Scheme of Reversible Data Hiding over Encrypted Image Data in Cloud Computing, CMC Comput. Mater. Con., 55 (2018), 523-539. |
| [3] | A. Alabdulkarim, M. Al-Rodhaan, Y. Tian A. Al-Dhelaan, A Privacy-Preserving Algorithm for Clinical Decision-Support Systems Using Random Forest, CMC Comput. Mater. Con., 58 (2019), 585-601. |
| [4] | X. Du, H. H. Chen, Security in Wireless Sensor Networks, IEEE Wireless Commun., 15 (2008), 60-66. |
| [5] | A. J. Paverd, A. Martin, I. Brown, Modelling and automatically analysing privacy properties for honest-but-curious adversaries, Univ. Oxford Tech. Rep., 2014 (2014). |
| [6] | H. Kido, Y. Yanagisawa, T. Satoh, An anonymous communication technique using dummies for location-based services, ICPS '05, International Conference on Pervasive Services, 2005, 88-97. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/1506394. |
| [7] | T. Ma, Y. Zhang, J. Cao, J. Shen, M. Tang, Y. Tian, KDVEM: A k-degree anonymity with Vertex and Edge Modification algorithm, Computing, 97 (2015): 1165-1184. |
| [8] | M. Gruteser, D. Grunwald, Anonymous usage of location-based services through spatial and temporal cloaking, Proceedings of the 1st international conference on Mobile systems, applications and services, ACM, 2003, 31-42. |
| [9] | R. Shokri, C. Troncoso, C. Diaz, J. Freudiger, J. P. Hubaux, Unraveling an Old Cloak: K-anonymity for Location Privacy, Proceeding WPES'10 Proceedings of the 9th annual ACM workshop on Privacy in the electronic society, 2010, 115-118. Available from: https://dl_acm.xilesou.top/citation.cfm?id=1866936. |
| [10] | B. Gedik, L. Liu, Protecting location privacy with personalized k-anonymity: Architecture and algorithms, IEEE Trans. Mobile Comput., 7 (2008), 1-18. |
| [11] | M. F. Mokbel, C. Y. Chow, W. G. Aref, The new casper: Query processing for location services without compromising privacy, VLDB '06 Proceedings of the 32nd international conference on Very large data bases, 763-774. Available from: https://dl_acm.xilesou.top/citation.cfm?id=1164193. |
| [12] | K. W. Tan, Y. Lin, K. Mouratidis, Spatial cloaking revisited: Distinguishing information leakage from anonymity, International Symposium on Spatial and Temporal Databases. Springer, Berlin, Heidelberg, 2009, 117-134. Available from: https://link_springer.xilesou.top/chapter/10.1007/978-3-642-02982-0_10. |
| [13] | T. Xu, Y. Cai, Feeling-based location privacy protection for location-based services, CCS '09 Proceedings of the 16th ACM conference on Computer and communications security, 2009. 348-357. Available from: https://dl_acm.xilesou.top/citation.cfm?id=1653704. |
| [14] | C. Bettini, X. S. Wang, S. Jajodia, Protecting privacy against location-based personal identification, Workshop on Secure Data Management, Springer, Berlin, Heidelberg, 2005, 185-199. Available from: https://link_springer.xilesou.top/chapter/10.1007/11552338_13. |
| [15] | K. Sampigethaya, L. Huang, M. Li, R. Poovendran, K. Matsuura, K. Sezaki, Caravan: Providing location privacy for VANET, Proceeding Embedded Security in Cars (ESCAR) Workshop, 2005, 13-15. Available from: https://labs.ece.uw.edu/nsl/papers/ESCAR-05.pdf. |
| [16] | G. Ghinita, P. Kalnis, S. Skiadopoulos, Prive: Anonymous location-based queries in distributed mobile systems, WWW '07 Proceedings of the 16th international conference on World Wide Web, 371-380, 2007. Available from: https://dl_acm.xilesou.top/citation.cfm?id=1242572.1242623. |
| [17] | J. Xu, X. Tang, H. Hu, J. Du, Privacy-consious location-based queries in mobile environments, IEEE Trans. Parallel Distrib. Syst., 21 (2010), 313-326. |
| [18] | T. Ma, J. Jia, Y. Xue, Y. Tian, A. Al-Dhelaan, M. Al-Rodhaan, Protection of location privacy for moving kNN queries in social networks, Appl. Soft Comput., 66 (2018), 525-532. |
| [19] | Y. Tian, M. M. Kaleemullah, M. A. Rodhaan, B. Song, A. Al-Dhelaan, T. Ma, A privacy preserving location service for cloud-of-things system, J. Parallel Distrib. Comput., 123 (2019), 215-222. |
| [20] | T. Wang, J. Zeng, Z. A. Bhuiyan, H. Tian, Y. Cai; Y. Chen, et al., Trajectory Privacy Preservation Based on a Fog Structure for Cloud Location Services, IEEE Access, 5 (2017), 7692-7701. |
| [21] | C. Dwork, M. Naor, T. Pitassi, G. N. Rothblum, Differential privacy under continual observation, STOC '10 Proceedings of the forty-second ACM symposium on Theory of computing, 715-724, 2010. Available from: https://dl_acm.xilesou.top/citation.cfm?id=1806787. |
| [22] | C. Dwork, The promise of different privacy: A tutorial on algorithmic techniques, 2011 IEEE 52nd Annual Symposium on Foundations of Computer Science, 2011. Available from: https://www.microsoft.com/en-us/research/wp-content/uploads/2011/10/PID2016981.pdf. |
| [23] | N. Li, T. Li, S. Venkatasubramanian, t-closeness: Pricavy beyond k-anonymity and l-diversity, 2007 IEEE 23rd International Conference on Data Engineering, 2007, 106-115. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/4221659. |
| [24] | L. Zheng, H. Yue, Z. Li, X. Pan, M. Wu, F. Yang, k-Anonymity Location Privacy Algorithm Based on Clustering, IEEE Access, 6 (2017), 28328-28338. |
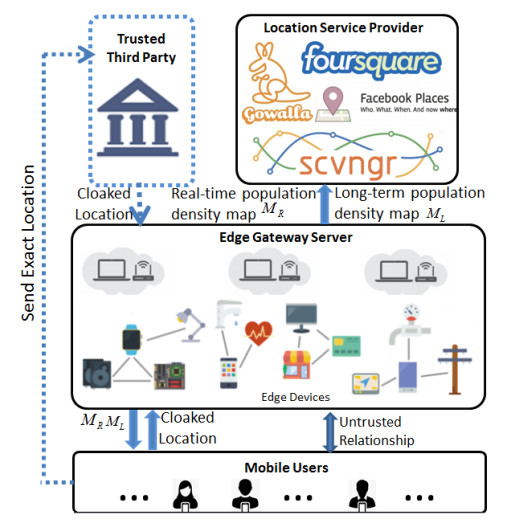
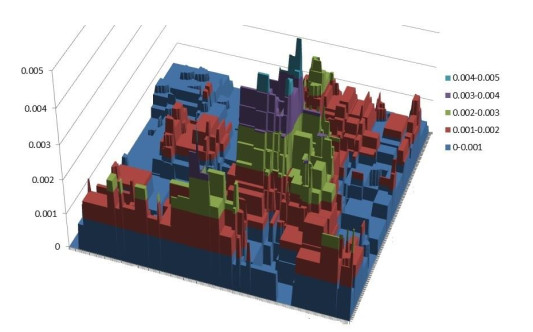
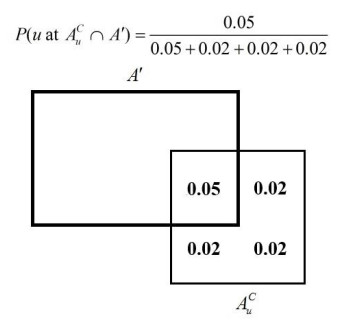
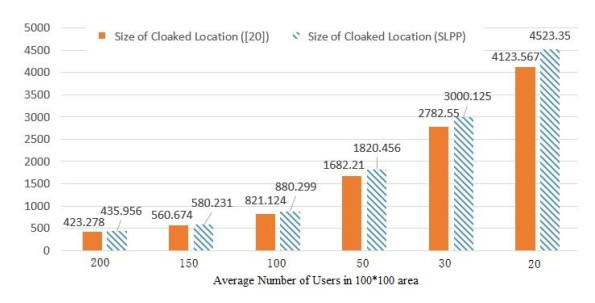
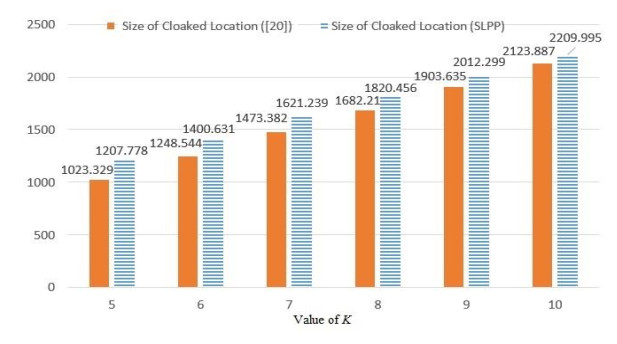
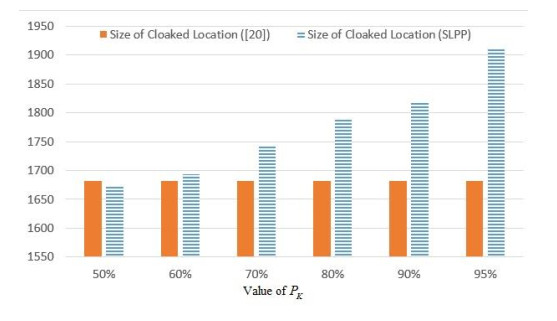
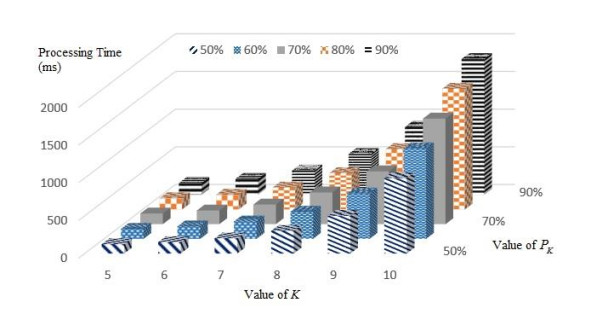
Figures(8)

Yuan Tian, Biao Song, Mznah Al Rodhaan, Chen Rong Huang, Mohammed A. Al-Dhelaan, Abdullah Al-Dhelaan, Najla Al-Nabhan. A stochastic location privacy protection scheme for edge computing[J]. Mathematical Biosciences and Engineering, 2020, 17(3): 2636-2649. doi: 10.3934/mbe.2020144







 DownLoad:
DownLoad: