Citation: Mengya Zhang, Qing Wu, Zezhou Xu. Tuning extreme learning machine by an improved electromagnetism-like mechanism algorithm for classification problem[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 4692-4707. doi: 10.3934/mbe.2019235

| [1] | W. Cao, X. Wang, Z. Ming, et al., A review on neural networks with random weights, Neurocomputing, (2017), S0925231217314613. |
| [2] | G. Camps-Valls, D. Tuia, L. Bruzzone, et al., Advances in hyperspectral image classification: earth monitoring with statistical learning methods, IEEE Signal Proc. Mag., 31 (2013), 45–54. |
| [3] | L. Wang, Y. Zeng and T. Chen, Back propagation neural network with adaptive differential evolution algorithm for time series forecasting, Expert Syst. Appl., 42 (2015), 855–863. |
| [4] | E. Maggiori, Y. Tarabalka, G. Charpiat, et al., Convolutional neural networks for large-scale remote sensing image classification, IEEE T. Geosci. Remote, 55 (2016), 645–657. |
| [5] | G. B. Huang, Q. Y. Zhu and C. K. Siew, Extreme learning machine: theory and applications, Neurocomputing, 70 (2006), 489–501. |
| [6] | J. Zhang, Y. F. Lu, B. Q. Zhang, et al., Device-free localization using empirical wavelet transform-based extreme learning machine, Proceedings of the 30th Chinese Control and Decision Conference, (2018), 2585–2590. |
| [7] | Y. J. Li, S. Zhang, Y. X. Yin, et al., A soft sensing scheme of gas utilization prediction for blast furnace via improved extreme learning machine, Neural Process. Lett. (2018), 10.1007/s11063-018-9888-3. |
| [8] | J. Zhang, Y. F. Xu, J. Q. Xue, et al., Real-time prediction of solar radiation based on online sequential extreme learning machine, Proceedings of the 13th IEEE Conference on Industrial Electronics and Applications, (2018), 53–57. |
| [9] | R. Z. Song, W. D. Xiao, Q. L. Wei, et al., Neural-network-based approach to finite-time optimal control for a class of unknown nonlinear systems, Soft Comput., 18 (2014), 1645–1653. |
| [10] | J. Zhang, W. D. Xiao, Y. J. Li, et al., Multilayer probability extreme learning machine for device-free localization. Neurocomputing, (2019), 10.1016/j.neucom.2018.11.106. |
| [11] | Y. Park, and H. S. Yang, Convolutional neural network based on an extreme learning machine for image classification, Neurocomputing, 339 (2019), 66–76. |
| [12] | G. B. Huang, H. Zhou, X. Ding, et al., Extreme learning machine for regression and multiclass classification, IEEE T. Syst. Man Cy. B., 42 (2012), 513–529. |
| [13] | F. Han, H. F. Yao and Q. H. Ling, An improved evolutionary extreme learning machine based on particle swarm optimization, Neurocomputing, 116 (2013), 87–93. |
| [14] | A. Rashno, B. Nazari, S. Sadri, et al., Effective pixel classification of mars images based on ant colony optimization feature selection and extreme learning machine, Neurocomputing, 226 (2017), 66–79. |
| [15] | G. Li, P. Niu, Y. Ma, et al., Tuning extreme learning machine by an improved artificial bee colony to model and optimize the boiler efficiency, Knowl-Based Syst., 67 (2014), 278–289. |
| [16] | İ. B. Ş, and S. Fang, An electromagnetism-like mechanism for global optimization, J. Global Optim., 25 (2003), 263–282. |
| [17] | C. J. Zhang, X. Y. Li, L. Gao, et al., An improved electromagnetism-like mechanism algorithm for constrained optimization, Expert Syst. Appl., 40 (2013), 5621–5634. |
| [18] | C. T. Tseng, C. H. Lee, Y. S. P. Chiu, et al., A discrete electromagnetism-like mechanism for parallel machine scheduling under a grade of service provision, Int. J. Prod. Res., 55 (2017), 3149–3163. |
| [19] | X. Y. Li, L. Gao, Q. K. Pan, et al., An effective hybrid genetic algorithm and variable neighborhood search for integrated process planning and scheduling in a packaging machine workshop, IEEE T. Syst. Man Cy. Syst., (2018), 10.1109/TSMC.2018.2881686. |
| [20] | X. Y. Li, C. Lu, L. Gao, et al., An Effective Multi-Objective Algorithm for Energy Efficient Scheduling in a Real-Life Welding Shop, IEEE T. Ind. Inform., 14 (2018), 5400–5409. |
| [21] | X. Y. Li, S. Q. Xiao, C. Y. Wang, et al., Mathematical Modeling and a Discrete Artificial Bee Colony Algorithm for the Welding Shop Scheduling Problem, Memetic Comp., (2019), 10.1007/s12293-019-00283-4. |
| [22] | Q. Wu, L. Gao, X. Y. Li, et al., Applying an electromagnetism-like mechanism algorithm on parameter optimisation of a multi-pass milling process, Int. J. Prod. Res., 51 (2013), 1777–1788. |
| [23] | K. J. Wang, A. M. Adrian, K. H. Chen, et al., An improved electromagnetism-like mechanism algorithm and its application to the prediction of diabetes mellitus, J. Biomed. Inform., 54 (2015), 220–229. |
| [24] | S. Mirjalili, Dragonfly algorithm: a new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems, Neural Comput. Appl., 27 (2016), 1053–1073. |
| [25] | G. Huang, G. B. Huang, S. Song, et al., Trends in extreme learning machines: a review, Neural Networks, 61 (2015), 32–48. |
| [26] | P. L. Bartlett, The sample complexity of pattern classification with neural networks: the size of the weights is more important than the size of the network, IEEE T. Inform. Theory, 44 (2002), 525–536. |
| [27] | Q. Y. Zhu, A. K. Qin, P. N. Suganthan, et al., Evolutionary extreme learning machine, Pattern Recogn., 38 (2005), 1759–1763. |
| [28] | D. Dua, and E. K. Taniskidou, UCI Machine Learning Repository Irvine, CA: University of California, School of Information and Computer Science, 2017. Available from: http://archive.ics.uci.edu/ml. |
| [29] | Y. Wang, A. Wang, Q. Ai, et al., A novel artificial bee colony optimization strategy-based extreme learning machine algorithm, Prog. Artif. Intell., 6 (2016), 1–12. |
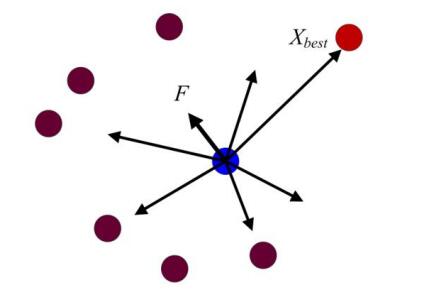
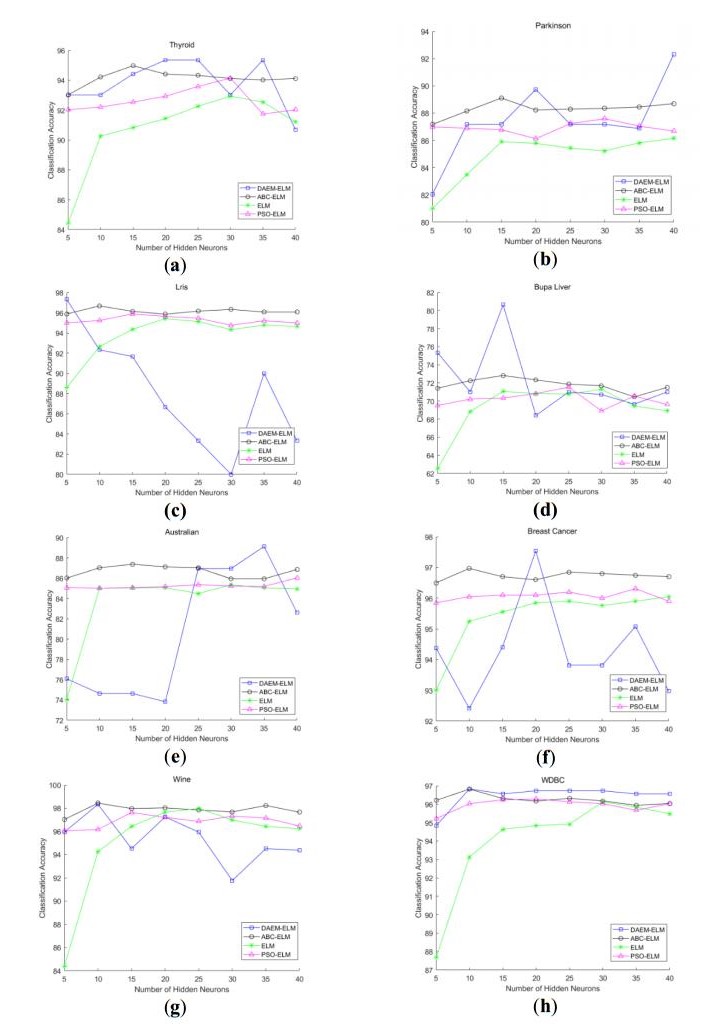
Figures(2) / Tables(4)

Mengya Zhang, Qing Wu, Zezhou Xu. Tuning extreme learning machine by an improved electromagnetism-like mechanism algorithm for classification problem[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 4692-4707. doi: 10.3934/mbe.2019235







 DownLoad:
DownLoad: