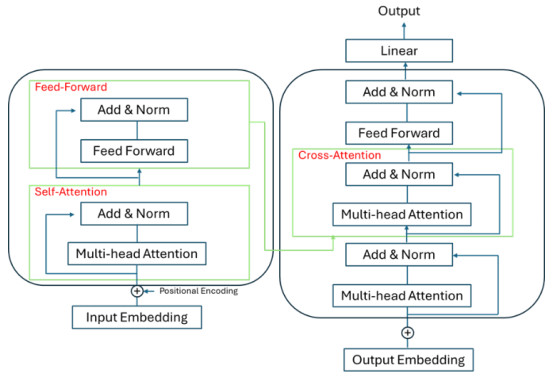
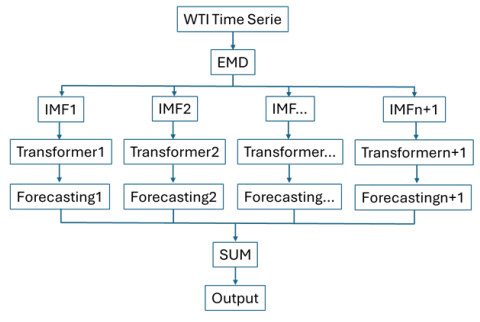
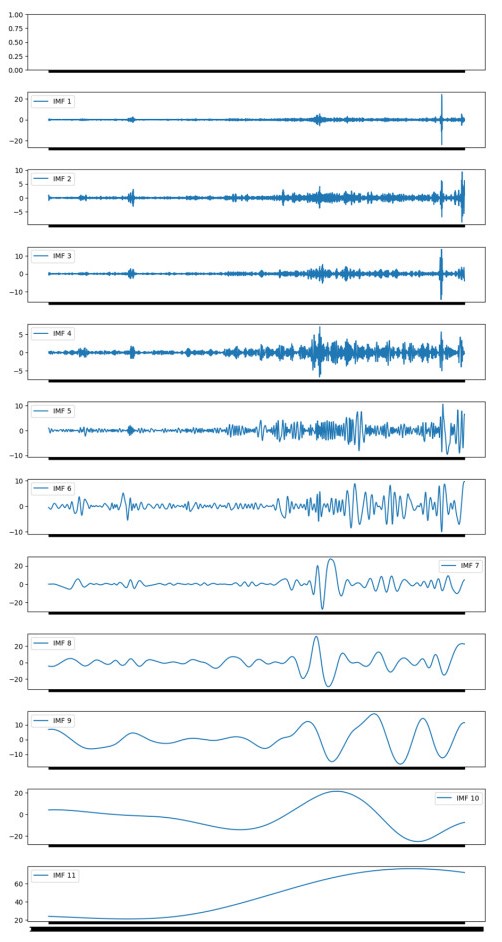
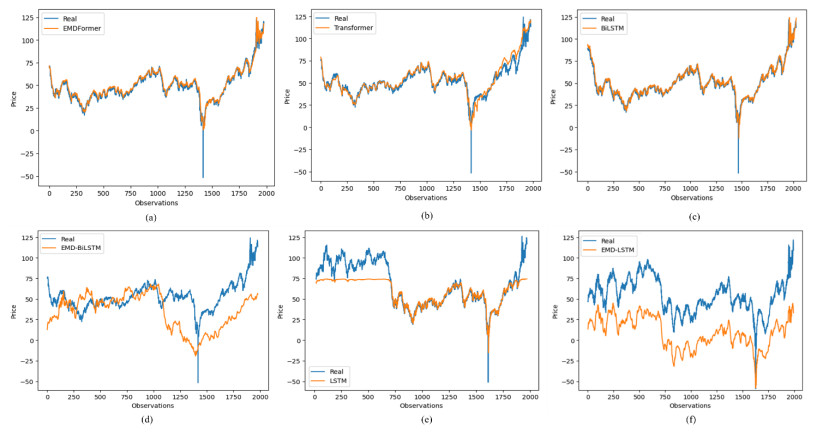
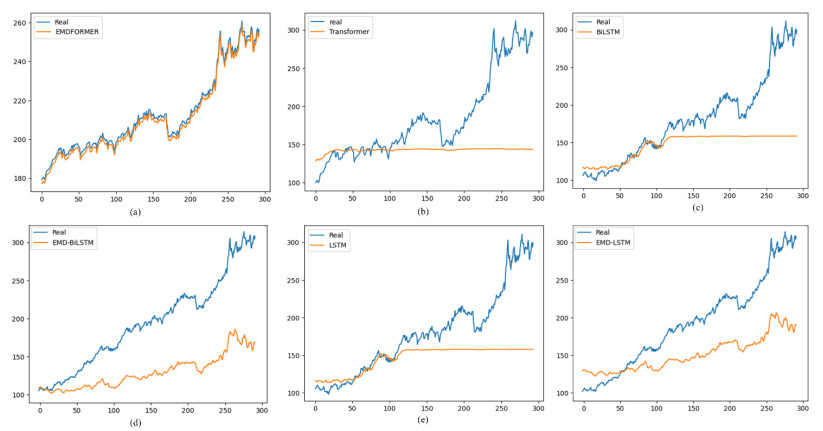
The adjusted precision of economic values is essential in the global economy. In recent years, researchers have increased their interest in making accurate predictions in this type of time series; one of the reasons is that the characteristics of this type of time series makes predicting a complicated task due to its non-linear nature. The evolution of artificial neural network models enables us to research the suitability of models generated for other purposes, applying their potential to time series prediction with promising results. Specifically, in this field, the application of transformer models is assuming an innovative approach with great results. To improve the performance of this type of networks, in this work, the empirical model decomposition (EMD) methodology was used as data preprocessing for prediction with a transformer type network. The results confirmed a better performance of this approach compared to networks widely used in this field, the bidirectional long short term memory (BiLSTM), and long short term memory (LSTM) networks using and without EMD preprocessing, as well as the comparison of a Transformer network without applying EMD to the data, with a lower error in all the error metrics used: The root mean square error (RMSE), the root mean square error (MSE), the mean absolute percentage error (MAPE), and the R-square (R2). Finding a model that provides results that improve the literature allows for a greater adjustment in the predictions with minimal preprocessing.
Citation: Ana Lazcano de Rojas, Miguel A. Jaramillo-Morán, Julio E. Sandubete. EMDFormer model for time series forecasting[J]. AIMS Mathematics, 2024, 9(4): 9419-9434. doi: 10.3934/math.2024459
The adjusted precision of economic values is essential in the global economy. In recent years, researchers have increased their interest in making accurate predictions in this type of time series; one of the reasons is that the characteristics of this type of time series makes predicting a complicated task due to its non-linear nature. The evolution of artificial neural network models enables us to research the suitability of models generated for other purposes, applying their potential to time series prediction with promising results. Specifically, in this field, the application of transformer models is assuming an innovative approach with great results. To improve the performance of this type of networks, in this work, the empirical model decomposition (EMD) methodology was used as data preprocessing for prediction with a transformer type network. The results confirmed a better performance of this approach compared to networks widely used in this field, the bidirectional long short term memory (BiLSTM), and long short term memory (LSTM) networks using and without EMD preprocessing, as well as the comparison of a Transformer network without applying EMD to the data, with a lower error in all the error metrics used: The root mean square error (RMSE), the root mean square error (MSE), the mean absolute percentage error (MAPE), and the R-square (R2). Finding a model that provides results that improve the literature allows for a greater adjustment in the predictions with minimal preprocessing.

| [1] |
J. Lago, F. De Ridder, B. De Schutter, Forecasting spot electricity prices: deep learning approaches and empirical comparison of traditional algorithms, Appl. Energy, 221 (2018), 386–405. https://doi.org/10.1016/j.apenergy.2018.02.069 doi: 10.1016/j.apenergy.2018.02.069

|
| [2] | G. E. Box, G. M. Jenkins, G. C. Reinsel, G. M. Ljung, Time series analysis: forecasting and control, John Wiley & Sons, 2015. |
| [3] |
J. Contreras, R. Espinola, F. Nogales, A. Conejo, ARIMA models to predict next-day electricity prices, IEEE Power Eng. Rev., 22 (2002), 57–57. https://doi.org/10.1109/MPER.2002.4312577 doi: 10.1109/MPER.2002.4312577
|
| [4] |
S. Saab, E. Badr, G. Nasr, Univariate modeling and forecasting of energy consumption: the case of electricity in Lebanon, Energy, 26 (2001), 1–14. https://doi.org/10.1016/S0360-5442(00)00049-9 doi: 10.1016/S0360-5442(00)00049-9
|
| [5] |
Lucas, K. Pegios, E. Kotsakis, D. Clarke, Price forecasting for the balancing energy market using machine-learning regression, Energies, 13 (2020), 5420. https://doi.org/10.3390/en13205420 doi: 10.3390/en13205420
|
| [6] |
B. Zhu, D. Han, P. Wang, Z. Wu, T. Zhang, Y. Wei, Forecasting carbon price using empirical mode decomposition and evolutionary least squares support vector regression, Appl. Energy, 191 (2017), 521–530. https://doi.org/10.1016/j.apenergy.2017.01.076 doi: 10.1016/j.apenergy.2017.01.076
|
| [7] |
T. Hill, M. O'Connor, W. Remus, Neural network models for time series forecasts, Manage. Sci., 42 (1996), 1082–1092. https://doi.org/10.1287/mnsc.42.7.1082 doi: 10.1287/mnsc.42.7.1082
|
| [8] |
M. Khashei, M. Bijari, An artificial neural network (p, d, q) model for timeseries forecasting, Expert Syst. Appl., 37 (2010), 479–489. https://doi.org/10.1016/j.eswa.2009.05.044 doi: 10.1016/j.eswa.2009.05.044
|
| [9] |
S. Bhardwaj, E. Chandrasekhar, P. Padiyar, V. M. Gadre, A comparative study of wavelet-based ANN and classical techniques for geophysical time-series forecasting, Comput. Geosci., 138 (2020), 104461. https://doi.org/10.1016/j.cageo.2020.104461 doi: 10.1016/j.cageo.2020.104461
|
| [10] |
A. D. Piazza, M. C. D. Piazza, G. L. Tona, M. Luna, An artificial neural network-based forecasting model of energy-related time series for electrical grid management, Math. Comput. Simul., 184 (2021), 294–305. https://doi.org/10.1016/j.matcom.2020.05.010 doi: 10.1016/j.matcom.2020.05.010
|
| [11] |
B. K. Rajput, P. Sunil, N. Yadav, A novel hybrid model combining βSARMA and LSTM for time series forecasting, Appl. Soft Comput., 134 (2023), 110019. https://doi.org/10.1016/j.asoc.2023.110019 doi: 10.1016/j.asoc.2023.110019
|
| [12] |
E. Egrioglu, E. Bas, A new hybrid recurrent artificial neural network for time series forecasting, Neural Comput. Appl., 35 (2023), 2855–2865. https://doi.org/10.1007/s00521-022-07753-w doi: 10.1007/s00521-022-07753-w
|
| [13] | P. H. Borghi, O. Zakordonets, J. P. Teixeira, A COVID-19 time series forecasting model based on MLP ANN, Proc. Comput. Sci., 181 (2021), 940–947. https://doi.org/110.1016/j.procs.2021.01.250 |
| [14] |
S. A. Chen, C. L. Li, N. Yoder, S. O. Arik, T. Pfister, Tsmixer: an all-MLP architecture for time series forecasting, arXiv, 2023. https://doi.org/10.48550/arXiv.2303.06053 doi: 10.48550/arXiv.2303.06053
|
| [15] |
C. Voyant, M. L. Nivet, C. Paoli, M. Muselli, G. Notton, Meteorological time series forecasting based on MLP modelling using heterogeneous transfer functions, J. Phys., 574 (2015), 012064. https://doi.org/10.1088/1742-6596/574/1/012064 doi: 10.1088/1742-6596/574/1/012064
|
| [16] |
K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators, Neural Networks, 2 (1989), 359–366. https://doi.org/10.1016/0893-6080(89)90020-8 doi: 10.1016/0893-6080(89)90020-8
|
| [17] |
T. Ciechulski, S. Osowski, High precision LSTM model for short-time load forecasting in power systems, Energies, 14 (2021), 2983. https://doi.org/10.3390/en14112983 doi: 10.3390/en14112983
|
| [18] |
B. S. Kwon, R. J. Park, K. B. Song, Short-term load forecasting based on deep neural networks using LSTM layer, J. Electron. Eng. Technol., 15 (2020), 1501–1509. https://doi.org/10.1007/s42835-020-00424-7 doi: 10.1007/s42835-020-00424-7
|
| [19] |
S. Siami-Namini, N. Tavakoli, A. S. Namin, The performance of LSTM and BiLSTM in forecasting time series, 2019 IEEE International Conference on Big Data (Big Data), 2019, 3285–3292. https://doi.org/10.1109/BigData47090.2019.9005997 doi: 10.1109/BigData47090.2019.9005997
|
| [20] |
J. Kim, N. Moon, BiLSTM model based on multivariate time series data in multiple field for forecasting trading area, J. Ambient Intell. Humanized Comput., 2019. https://doi.org/10.1007/s12652-019-01398-9 doi: 10.1007/s12652-019-01398-9
|
| [21] |
M. Yang, J. Wang, Adaptability of financial time series prediction based on BiLSTM, Proc. Comput. Sci., 199 (2022), 18–25. https://doi.org/10.1016/j.procs.2022.01.003 doi: 10.1016/j.procs.2022.01.003
|
| [22] |
D. Salinas, V. Flunkert, J. Gasthaus, T. Januschowski, DeepAR: probabilistic forecasting with autoregressive recurrent networks, Int. J. Forecast., 36 (2020), 1181–1191. https://doi.org/10.1016/j.ijforecast.2019.07.001 doi: 10.1016/j.ijforecast.2019.07.001
|
| [23] |
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, arXiv, 2017. https://doi.org/10.48550/arXiv.1706.03762 doi: 10.48550/arXiv.1706.03762
|
| [24] |
J. Devlin, M. W. Chang, K. Lee, K. Toutanova, Bert: pre-training of deep bidirectional transformers for language understanding, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019, 4171–4186. https://doi.org/10.18653/v1/N19-1423 doi: 10.18653/v1/N19-1423
|
| [25] |
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, et al., An image is worth 16×16 words: transformers for image recognition at scale, arXiv, 2020. https://doi.org/10.48550/arXiv.2010.11929 doi: 10.48550/arXiv.2010.11929
|
| [26] |
P. Ran, K. Dong, X. Liu, J. Wang, Short-term load forecasting based on CEEMDAN and transformer, Electr. Power Syst. Res., 214 (2023) 108885. https://doi.org/10.1016/j.epsr.2022.108885 doi: 10.1016/j.epsr.2022.108885
|
| [27] |
L. Li, X. Su, X. Bi, Y. Lu, X. Sun, A novel transformer-based network forecasting method for building cooling loads, Energy Build., 296 (2023), 113409. https://doi.org/10.1016/j.enbuild.2023.113409 doi: 10.1016/j.enbuild.2023.113409
|
| [28] |
M. J. Walczewski, H. Wöhrle, Prediction of electricity generation using onshore wind and solar energy in Germany, Energies, 17 (2024), 844. https://doi.org/10.3390/en17040844 doi: 10.3390/en17040844
|
| [29] |
A. Rosato, R. Araneo, A. Andreotti, F. Succetti, M. Panella, 2-D convolutional deep neural network for the multivariate prediction of photovoltaic time series, Energies, 14 (2021), 2392. https://doi.org/10.3390/en14092392 doi: 10.3390/en14092392
|
| [30] |
P. Wibawa, A. B. P. Utama, H. Elmunsyah, U. Pujianto, F. A. Dwiyanto, L. Hernandez, Time-series analysis with smoothed convolutional neural network, J. Big Data, 9 (2022), 44. https://doi.org/10.1186/s40537-022-00599-y doi: 10.1186/s40537-022-00599-y
|
| [31] |
S. Jung, J. Moon, S. Park, E. Hwang, An attention-based multilayer GRU model for multistep-ahead short-term load forecasting, Sensors, 21 (2021), 1639. https://doi.org/10.3390/s21051639 doi: 10.3390/s21051639
|
| [32] |
S. Ungureanu, V. Topa, A. Cziker, Deep learning for short-term load forecasting-industrial consumer case study, Appl. Sci., 11 (2021), 10126. https://doi.org/10.3390/app112110126 doi: 10.3390/app112110126
|
| [33] |
Y. Chen, F. Ding, L. Zhai, Multi-scale temporal features extraction based graph convolutional network with attention for multivariate time series prediction, Expert Syst. Appl., 200 (2022), 117011. https://doi.org/10.1016/j.eswa.2022.117011 doi: 10.1016/j.eswa.2022.117011
|
| [34] |
A. Lazcano, P. J. Herrera, M. Monge, A combined model based on recurrent neural networks and graph convolutional networks for financial time series forecasting, Mathematics, 11 (2023), 224. https://doi.org/10.3390/math11010224 doi: 10.3390/math11010224
|
| [35] |
X. Guo, Q. Zhao, D. Zheng, Y. Ning, Y. Gao, A short-term load forecasting model of multi-scale CNN-LSTM hybrid neural network considering the real-time electricity price, Energy Reports, 6 (2020), 1046–1053, https://doi.org/10.1016/j.egyr.2020.11.078 doi: 10.1016/j.egyr.2020.11.078
|
| [36] |
W. Yang, J. Shi, S. Li, Z. Song, Z. Zhang, Z. Chen, A combined deep learning load forecasting model of single household resident user considering multi-time scale electricity consumption behavior, Appl. Energy, 307 (2022), 118197. https://doi.org/10.1016/j.apenergy.2021.118197 doi: 10.1016/j.apenergy.2021.118197
|
| [37] |
L. Ji, Y. Zou, K. He, B. Zhu, Carbon futures price forecasting based with ARIMA-CNN-LSTM model, Proc. Comput. Sci., 62 (2019), 33–38. https://doi.org/10.1016/j.procs.2019.11.254 doi: 10.1016/j.procs.2019.11.254
|
| [38] |
Z. Zeng, R. Kaur, S. Siddagangappa, S. Rahimi, T. Balch, M. Veloso, Financial time series forecasting using CNN and transformer, arXiv, 2023. https://doi.org/10.48550/arXiv.2304.04912 doi: 10.48550/arXiv.2304.04912
|
| [39] | S. Kotsiantis, D. Kanellopoulos, P. Pintelas, Data preprocessing for supervised learning, Int. J. Comput. Sci., 1 (2006), 111–117. |
| [40] |
D. Yang, J. Guo, S. Sun, J. Han, S. Wang, An interval decomposition-ensemble approach with data-characteristic-driven reconstruction for short-term load forecasting, Appl. Energy, 306 (2022), 117992. https://doi.org/10.1016/j.apenergy.2021.117992 doi: 10.1016/j.apenergy.2021.117992
|
| [41] |
Neeraj, J. Mathew, R. J. Behera, EMD-Att-LSTM: a data-driven strategy combined with deep learning for short-term load forecasting, J. Mod. Power Syst. Clean Energy, 10 (2022), 1229–1240. https://doi.org/10.35833/MPCE.2020.000626 doi: 10.35833/MPCE.2020.000626
|
| [42] |
N. Li, J. Dong, L. Liu, H. Li, J. Yan, A novel EMD and causal convolutional network integrated with Transformer for ultra short-term wind power forecasting, Int. J. Electr. Power Energy Syst., 154 (2023), 109470. https://doi.org/10.1016/j.ijepes.2023.109470 doi: 10.1016/j.ijepes.2023.109470
|
| [43] |
X. Wang, S. Dong, R. Zhang, An integrated time series prediction model based on empirical mode decomposition and two attention mechanisms, Information, 14 (2023), 610. https://doi.org/10.3390/info14110610 doi: 10.3390/info14110610
|
| [44] |
Z. Zhao, W. Chen, X. Wu, P. C. Y. Chen, J. Liu, LSTM network: a deep learning approach for short-term traffic forecast, IET Intell. Transp. Syst., 11 (2017), 68–75. https://doi.org/10.1049/iet-its.2016.0208 doi: 10.1049/iet-its.2016.0208
|
| [45] |
Y. Ren, P. N. Suganthan, N. Srikanth, A comparative study of empirical mode decomposition-based short-term wind speed forecasting methods, IEEE Trans. Sustain. Energy, 6 (2014), 236–244. https://doi.org/10.1109/TSTE.2014.2365580 doi: 10.1109/TSTE.2014.2365580
|
| [46] |
N. E. Huang, Z. Shen, S. R. Long, M. C. Wu, H. H. Shih, Q. Zhen, et al., The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis, Proc. R. Soc. London, 454 (1998), 903–995. https://doi.org/10.1098/rspa.1998.0193 doi: 10.1098/rspa.1998.0193
|
| [47] |
C. Li, G. Qian, Stock price prediction using a frequency decomposition based GRU Transformer neural network, Appl. Sci., 13 (2022), 222. https://doi.org/10.3390/app13010222 doi: 10.3390/app13010222
|
| [48] | D. C. Frechtling, Practical tourism forecasting, Oxford: Butterworth-Heinemann, 1996. |
| [49] |
R. Sun, Optimization for deep learning: theory and algorithms, arXiv, 2019. https://doi.org/10.48550/arXiv.1912.08957 doi: 10.48550/arXiv.1912.08957
|
| [50] |
I. Goodfellow, Nips 2016 tutorial: generative adversarial networks, arXiv, 2016. https://doi.org/10.48550/arXiv.1701.00160 doi: 10.48550/arXiv.1701.00160
|
| [51] | J. V. Beck, K. J. Arnold, Parameter estimation in engineering and science, James Beck, 1977. https://doi.org/10.2307/1403212 |
| [52] |
L. N. Smith, A disciplined approach to neural network hyper-parameters: part 1-learning rate, batch size, momentum, and weight decay, arXiv, 2018. https://doi.org/10.48550/arXiv.1803.09820 doi: 10.48550/arXiv.1803.09820
|
| [53] |
M. Pirani, P. Thakkar, P. Jivrani, M. H. Bohara, D. Garg, A comparative analysis of ARIMA, GRU, LSTM and BiLSTM on financial time series forecasting, 2022 IEEE International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), 2022. https://doi.org/10.1109/ICDCECE53908.2022.9793213 doi: 10.1109/ICDCECE53908.2022.9793213
|
Figures(5) / Tables(3)

Ana Lazcano de Rojas, Miguel A. Jaramillo-Morán, Julio E. Sandubete. EMDFormer model for time series forecasting[J]. AIMS Mathematics, 2024, 9(4): 9419-9434. doi: 10.3934/math.2024459







 DownLoad:
DownLoad: