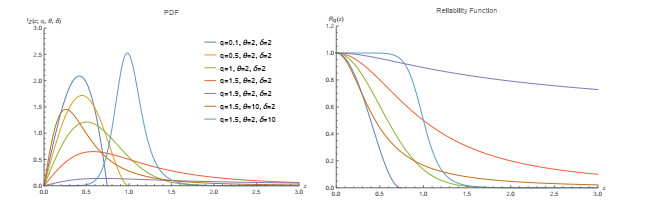
This work utilizes generalized order statistics (GOSs) to study the $ q $-Weibull distribution from several statistical perspectives. First, we explain how to obtain the maximum likelihood estimates (MLEs) and utilize Bayesian techniques to estimate the parameters of the model. The Fisher information matrix (FIM) required for asymptotic confidence intervals (CIs) is generated by obtaining explicit expressions. A Monte Carlo simulation study is conducted to compare the performances of these estimates based on type Ⅱ censored samples. Two well-established measures of information are presented, namely extropy and weighted extropy. In this context, the order statistics (OSs) and sequential OSs (SOSs) for these two measures are studied based on this distribution. A bivariate $ q $-Weibull distribution based on the Farlie-Gumbel-Morgenstern (FGM) family and its relevant concomitants are studied. Finally, two concrete instances of medical real data are ultimately provided.
Citation: M. Nagy, H. M. Barakat, M. A. Alawady, I. A. Husseiny, A. F. Alrasheedi, T. S. Taher, A. H. Mansi, M. O. Mohamed. Inference and other aspects for $ q- $Weibull distribution via generalized order statistics with applications to medical datasets[J]. AIMS Mathematics, 2024, 9(4): 8311-8338. doi: 10.3934/math.2024404
This work utilizes generalized order statistics (GOSs) to study the $ q $-Weibull distribution from several statistical perspectives. First, we explain how to obtain the maximum likelihood estimates (MLEs) and utilize Bayesian techniques to estimate the parameters of the model. The Fisher information matrix (FIM) required for asymptotic confidence intervals (CIs) is generated by obtaining explicit expressions. A Monte Carlo simulation study is conducted to compare the performances of these estimates based on type Ⅱ censored samples. Two well-established measures of information are presented, namely extropy and weighted extropy. In this context, the order statistics (OSs) and sequential OSs (SOSs) for these two measures are studied based on this distribution. A bivariate $ q $-Weibull distribution based on the Farlie-Gumbel-Morgenstern (FGM) family and its relevant concomitants are studied. Finally, two concrete instances of medical real data are ultimately provided.

| [1] |
U. Kamps, A concept of generalized order statistics, J. Statist. Plan. Inf., 48 (1995), 1–23. https://doi.org/10.1016/0378-3758(94)00147-N doi: 10.1016/0378-3758(94)00147-N

|
| [2] |
C. A. Charalambides, Discrete q-distributions on Bernoulli trials with a geometrically varying success probability, J. Statist. Plann. Inf., 140 (2010), 2355–2383. https://doi.org/10.1016/j.jspi.2010.03.024 doi: 10.1016/j.jspi.2010.03.024
|
| [3] |
R. Diaz, E. Pariguan, On the Gaussian q-distribution, J. Math. Anal. Appl., 358 (2009), 1–9. https://doi.org/10.1016/j.jmaa.2009.04.046 doi: 10.1016/j.jmaa.2009.04.046
|
| [4] |
R. Diaz, C. Ortiz, E. Pariguan, On the k-gamma q-distribution, Cent. Eur. J. Math., 8 (2010), 448–458. https://doi.org/10.2478/s11533-010-0029-0 doi: 10.2478/s11533-010-0029-0
|
| [5] |
X. Jia, S. Nadarajah, B. Guo, Inference on q-Weibull parameters, Statist. Papers, 61 (2020), 575–593. http://doi.org/10.1007/s00362-017-0951-3 doi: 10.1007/s00362-017-0951-3
|
| [6] |
B. Singh, R. U. Khan, M. A. Khan, Characterizations of q-Weibull distribution based on generalized order statistics, J. Statist. Manag. Sys., 22 (2019), 1573–1595. http://doi.org/10.1080/09720510.2019.1643554 doi: 10.1080/09720510.2019.1643554
|
| [7] |
X. Jia, Reliability analysis for q-Weibull distribution with multiply type-Ⅰ censored data, Qual. Reliab. Eng. Int., 37 (2021), 2790–2817. http://doi.org/10.1002/qre.2890 doi: 10.1002/qre.2890
|
| [8] |
F. Lad, G. Sanflippo, G. Agro, Extropy: complementary dual of entropy, Statist. Sci., 30 (2015), 40–58. http://doi.org/10.1214/14-sts430 doi: 10.1214/14-sts430
|
| [9] |
I. A. Husseiny, A. H. Syam, The extropy of concomitants of generalized order statistics from Huang-Kotz-Morgenstern bivariate distribution, J. Math., 2022 (2022), 6385998. http://dx.doi.org/10.1155/2022/6385998 doi: 10.1155/2022/6385998
|
| [10] |
S. Bansal, N. Gupta, Weighted extropies and past extropy of order statistics and k-record values, Commun. Statist. Theory Meth., 51 (2022), 6091–6108. http://dx.doi.org/10.1080/03610926.2020.1853773 doi: 10.1080/03610926.2020.1853773
|
| [11] |
S. Picoli, R. S. Mendes, L. C. Malacarne, q-exponential, Weibull, and q-Weibull distributions: an empirical analysis, Phys. A, 324 (2003), 678–688. http://doi.org/10.1016/s0378-4371(03)00071-2 doi: 10.1016/s0378-4371(03)00071-2
|
| [12] |
Z. A. Aboeleneen, Inference for Weibull distribution under generalized order statistics, Math. Comput. Sim., 81 (2010), 26–36. http://dx.doi.org/10.1016/j.matcom.2010.06.013 doi: 10.1016/j.matcom.2010.06.013
|
| [13] | A. A. Jafari, H. Zakerzadeh, Inference on the parameters of the Weibull distribution using records, SORT, 39 (2015), 3–18. |
| [14] |
P. H. Garthwaite, J. B. Kadane, A. OHagan, Statistical methods for eliciting probability distributions, J. Am. Stat. Assoc., 100 (2005), 680–701. http://dx.doi.org/10.1198/016214505000000105 doi: 10.1198/016214505000000105
|
| [15] |
K. M. Hamdia, X. Zhuang, P. He, T. Rabczuk, Fracture toughness of polymeric particle nanocomposites: Evaluation of models performance using Bayesian method, Composites Sci. Tech., 126 (2016), 122–129. http://dx.doi.org/10.1016/j.compscitech.2016.02.012 doi: 10.1016/j.compscitech.2016.02.012
|
| [16] |
X. Jia, D. Wang, P. Jiang, B. Guo, Inference on the reliability of Weibull distribution with multiply type-Ⅰ censored data, Reliab. Eng. Syst. Saf., 150 (2016), 171–181. http://doi.org/10.1016/j.ress.2016.01.025 doi: 10.1016/j.ress.2016.01.025
|
| [17] |
M. Xu, E. L. Droguett, I. D. Lins, M. das Chagas Moura, On the q-Weibull distribution for reliability applications: An adaptive hybrid artificial bee colony algorithm for parameter estimation, Reliab. Eng. Syst. Saf., 158 (2017), 93–105. http://doi.org/10.1016/j.ress.2016.10.012 doi: 10.1016/j.ress.2016.10.012
|
| [18] | R. B. Nelsen, An Introduction to Copulas, New York: Springer-Verlag, 2006. |
| [19] | A. Sklar, Random variables, joint distribution functions, and copulas, Kybernetika, 9 (1973), 449–460. |
| [20] | E. J. Gumbel, Bivariate exponential distributions, J. Am. Stat. Assoc., 55 (1960), 698–707. |
| [21] |
M. A. Alawady, H. M. Barakat, M. A. Abd Elgawad, Concomitants of generalized order statistics from bivariate Cambanis family of distributions under a general setting, Bull. Malays. Math. Sci. Soc., 44 (2021), 3129–3159. http://dx.doi.org/10.1007/s40840-021-01102-1 doi: 10.1007/s40840-021-01102-1
|
| [22] |
M. A. Alawady, H. M. Barakat, S. Xiong, M. A. Abd Elgawad, Concomitants of generalized order statistics from iterated Farlie-Gumbel-Morgenstern type bivariate distribution, Commun. Statist. Theory Meth., 51 (2022), 5488–5504. http://dx.doi.org/10.1080/03610926.2020.1842452 doi: 10.1080/03610926.2020.1842452
|
| [23] |
S. P. Arun, C. Chesneau, R. Maya, M. R. Irshad, Farlie-Gumbel-Morgenstern bivariate moment exponential distribution and its inferences based on concomitants of order statistics, Stats, 6 (2023), 253–267. http://dx.doi.org/10.3390/stats6010015 doi: 10.3390/stats6010015
|
| [24] |
H. M. Barakat, M. A. Alawady, I. A. Husseiny, G. M. Mansour, Sarmanov family of bivariate distributions: statistical properties, concomitants of order statistics, and information measures, Bull. Malays. Math. Sci. Soc., 45 (2022), 49–83. http://dx.doi.org/10.1007/s40840-022-01241-z doi: 10.1007/s40840-022-01241-z
|
| [25] |
H. M. Barakat, E. M. Nigm, M. A. Alawady, I. A. Husseiny, Concomitants of order statistics and record values from the generalization of FGM bivariate-generalized exponential distribution, J. Statist. Theory Appl., 18 (2019), 309–322. http://dx.doi.org/10.2991/jsta.d.190822.001 doi: 10.2991/jsta.d.190822.001
|
| [26] |
H. M. Barakat, E. M. Nigm, M. A. Alawady, I. A. Husseiny, Concomitants of order statistics and record values from the iterated FGM type bivariate-generalized exponential distribution, REVSTAT Statist. J., 19 (2021), 291–307. http://dx.doi.org/10.2298/fil1809313b doi: 10.2298/fil1809313b
|
| [27] |
S. Cambanis, Some properties and generalizations of multivariate Eyraud-Gumbel-Morgenstern distributions, J. Mul. Anal., 7 (1977), 551–559. http://dx.doi.org/10.1016/0047-259x(77)90066-5 doi: 10.1016/0047-259x(77)90066-5
|
| [28] |
I. A. Husseiny, H. M. Barakat, G. M. Mansour, M. A. Alawady, Information measures in record and their concomitants arising from Sarmanov family of bivariate distributions, J. Comput. Appl. Math., 408 (2022), 114120. http://doi.org/10.1016/j.cam.2022.114120 doi: 10.1016/j.cam.2022.114120
|
| [29] |
I. A. Husseiny, M. A. Alawady, H. M. Barakat, M. A. Abd Elgawad, Information measures for order statistics and their concomitants from Cambanis bivariate family, Commun. Statist. Theory Meth., 53 (2024), 865–881. http://doi.org/10.1080/03610926.2022.2093909 doi: 10.1080/03610926.2022.2093909
|
| [30] | J. Scaria, B. Thomas, Second order concomitants from the Morgenstern family of distributions, J. Appl. Statist. Sci., 21 (2014), 63–76. |
| [31] |
W. Schucany, W. C. Parr, J. E. Boyer, Correlation structure in Farlie-Gumbel-Morgenstern distributions, Biometrika, 65 (1978), 650–653. http://doi.org/10.1093/biomet/65.3.650 doi: 10.1093/biomet/65.3.650
|
| [32] |
R. A. Attwa, T. Radwan, E. O. Abo Zaid, Bivariate q-extended Weibull Morgenstern family and correlation coefficient formulas for some of its sub-models, AIMS Math., 8 (2023), 25325–25342. http://dx.doi.org/10.3934/math.20231292 doi: 10.3934/math.20231292
|
| [33] | M. Gurvich, A. Dibenedetto, S. Ranade, A new statistical distribution for characterizing the random strength of brittle materials, J. Mater. Sci., 32 (1997), 2559–2564. |
| [34] | H. A. David, Concomitants of order statistics, Bull. Int. Statist. Inst., 45 (1973), 295–300. |
| [35] |
I. Bairamov, S. Kotz, M. Becki, New generalized Farlie-Gumbel-Morgenstern distributions and concomitants of order statistics, J. Appl. Statist., 28 (2001), 521–536. http://dx.doi.org/10.1080/02664760120047861 doi: 10.1080/02664760120047861
|
| [36] |
M. I. Beg, M. Ahsanullah, Concomitants of generalized order statistics from Farlie-Gumbel-Morgenstern distributions, Statist. Methodol., 5 (2008), 1–20. http://dx.doi.org/10.1016/j.stamet.2007.04.001 doi: 10.1016/j.stamet.2007.04.001
|
| [37] |
F. Domma, S. Giordano, Concomitants of m-generalized order statistics from generalized Farlie-Gumbel-Morgenstern distribution family, J. Comput. Appl. Math., 294 (2016), 413–435. http://dx.doi.org/10.1016/j.cam.2015.08.022 doi: 10.1016/j.cam.2015.08.022
|
| [38] |
S. Eryilmaz, On an application of concomitants of order statistics, Commun. Statist. Theory Meth., 45 (2016), 5628–5636. http://dx.doi.org/10.1080/03610926.2014.948201 doi: 10.1080/03610926.2014.948201
|
| [39] |
J. Scaria, N. U. Nair, Distribution of extremes of rth concomitant from the Morgenstern family, Statist. Papers, 49 (2008), 109–119. http://doi.org/10.1007/s00362-006-0365-0 doi: 10.1007/s00362-006-0365-0
|
| [40] |
S. Tahmasebi, A. A. Jafari, Concomitants of order statistics and record values from Morgenstern type bivariate-generalized exponential distribution, Bull. Malays. Math. Sci. Soc., 38 (2015), 1411–1423. http://doi.org/10.1007/s40840-014-0087-8 doi: 10.1007/s40840-014-0087-8
|
| [41] |
H. S. Klakattawi, W. H. Aljuhani, L. A. Baharith, Alpha power exponentiated new Weibull-Pareto distribution: Its properties and applications, Pakistan J. Statist. Oper. Res., 18 (2022), 703–720. http://doi.org/10.18187/pjsor.v18i3.3937 doi: 10.18187/pjsor.v18i3.3937
|
| [42] | E. T. Lee, J. Wang, Statistical Methods for Survival Data Analysis, New york: John Wiley & Sons, 2003. |









Figures(10) / Tables(7)

M. Nagy, H. M. Barakat, M. A. Alawady, I. A. Husseiny, A. F. Alrasheedi, T. S. Taher, A. H. Mansi, M. O. Mohamed. Inference and other aspects for $ q- $Weibull distribution via generalized order statistics with applications to medical datasets[J]. AIMS Mathematics, 2024, 9(4): 8311-8338. doi: 10.3934/math.2024404







 DownLoad:
DownLoad: