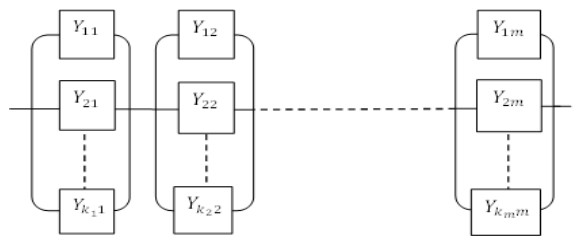
It is of great importance for physicists and engineers to assess a lifetime distribution of a series-parallel system when its components' lifetimes are subject to a finite mixture of distributions. The present article addresses this problem by introducing a new distribution called "Poisson-geometric-Lomax distribution". Important properties of the proposed distribution are discussed. When the stress is an increasing nonlinear function of time, the progressive-stress model is considered and the inverse power-law model has suggested a relationship between the stress and the scale parameter of the proposed distribution. Based on the progressive type-II censoring with binomial removals, estimation of the included parameters is discussed using maximum likelihood and Bayes methods. An example, based on two real data sets, demonstrates the superiority of the proposed distribution over some other known distributions. To compare the performance of the implemented estimation methods, a simulation study is carried out. Finally, some concluding remarks followed by certain features and motivations to the proposed distribution are presented.
Citation: Tahani A. Abushal, Alaa H. Abdel-Hamid. Inference on a new distribution under progressive-stress accelerated life tests and progressive type-II censoring based on a series-parallel system[J]. AIMS Mathematics, 2022, 7(1): 425-454. doi: 10.3934/math.2022028
It is of great importance for physicists and engineers to assess a lifetime distribution of a series-parallel system when its components' lifetimes are subject to a finite mixture of distributions. The present article addresses this problem by introducing a new distribution called "Poisson-geometric-Lomax distribution". Important properties of the proposed distribution are discussed. When the stress is an increasing nonlinear function of time, the progressive-stress model is considered and the inverse power-law model has suggested a relationship between the stress and the scale parameter of the proposed distribution. Based on the progressive type-II censoring with binomial removals, estimation of the included parameters is discussed using maximum likelihood and Bayes methods. An example, based on two real data sets, demonstrates the superiority of the proposed distribution over some other known distributions. To compare the performance of the implemented estimation methods, a simulation study is carried out. Finally, some concluding remarks followed by certain features and motivations to the proposed distribution are presented.

| [1] | W. Nelson, Accelerated testing: Statistical models, test plans and data analysis, New York: Wiley, 1990. doi: 10.1002/9780470316795. |
| [2] | V. Bagdonavicius, M. Nikulin, Accelerated life models: Modeling and statistical analysis, USA: CRC Press, 2002. doi: 10.1201/9781420035872. |
| [3] |
X. K. Yin, B. Z. Sheng, Some aspects of accelerated life testing by progressive stress, IEEE Trans. Reliab., 36 (1987), 150–155. doi: 10.1109/TR.1987.5222320. doi: 10.1109/TR.1987.5222320

|
| [4] |
A. H. Abdel-Hamid, E. K. AL-Hussaini, Inference and optimal design based on step-partially accelerated life tests for the generalized Pareto distribution under progressive type-I censoring, Commun. Statist.-Simul. Comput., 44 (2014), 1750–1769. doi: 10.1080/03610918.2013.826363. doi: 10.1080/03610918.2013.826363
|
| [5] |
A. H. Abdel-Hamid, T. A. Abushal, Inference on progressive-stress model for the exponentiated exponential distribution under type-II progressive hybrid censoring, J. Statist. Comput. Simul., 85 (2015), 1165–1186. doi: 10.1080/00949655.2013.868463. doi: 10.1080/00949655.2013.868463
|
| [6] |
E. K. AL-Hussaini, A. H. Abdel-Hamid, A. F. Hashem, One-sample Bayesian prediction intervals based on progressively type-II censored data from the half-logistic distribution under progressive-stress model, Metrika, 78 (2015), 771–783. doi: 10.1007/s00184-014-0526-4. doi: 10.1007/s00184-014-0526-4
|
| [7] |
A. H. Abdel-Hamid, A. F. Hashem, A new lifetime distribution for a series-parallel system: Properties, applications and estimations under progressive type-II censoring, J. Statist. Comput. Simul., 87 (2017), 993–1024. doi: 10.1080/00949655.2016.1243683. doi: 10.1080/00949655.2016.1243683
|
| [8] |
A. H. Abdel-Hamid, A. F. Hashem, A new compound distribution based on a mixture of distributions and a mixed system, C. R. Acad. Bulg. Sci., 71 (2018), 1439–1450. doi: 10.7546/CRABS.2018.11.01. doi: 10.7546/CRABS.2018.11.01
|
| [9] |
S. Nadarajah, A. H. Abdel-Hamid, A. F. Hashem, Inference for a geometric-Poisson-Rayleigh distribution under progressive-stress model based on type-I progressive hybrid censoring with binomial removals, Qual. Reliab. Eng. Int., 34 (2018), 649–680. doi: 10.1002/qre.2279. doi: 10.1002/qre.2279
|
| [10] |
Y. Hu, Y. Ding, F. Wen, L. Liu, Reliability assessment in distributed multi-state series-parallel systems, Energy Procedia, 159 (2019), 104–110. doi: 10.1016/j.egypro.2018.12.026, doi: 10.1016/j.egypro.2018.12.026,
|
| [11] |
A. F. Hashem, S. A. Alyami, Inference on a new lifetime distribution under progressive type II censoring for a parallel-series structure, Complexity, 2021 (2021), 6684918. doi: 10.1155/2021/6684918. doi: 10.1155/2021/6684918
|
| [12] |
H. Teicher, On the mixture of distributions, Ann. Math. Statist., 31 (1960), 55–73. doi: 10.1214/aoms/1177705987. doi: 10.1214/aoms/1177705987
|
| [13] | R. A. Fisher, The mathematical theory of probabilities and its applications to frequency-curves and statistical methods, New York: The Macmillan Company, 1922. |
| [14] | D. M. Titterington, A. F. M. Smith, U. E. Makov, Statistical analysis of finite mixture distributions, New York: Wiley, 1985. |
| [15] | G. J. McLachlan, K. E. Basford, Mixture models: Inferences and applications to clustering, New York: Marcel Dekker, 1988. |
| [16] |
E. K. AL-Hussaini, A. H. Abdel-Hamid, Generation of distribution functions: A survey, J. Statist. Appl., 7 (2018), 91–103. doi: 10.18576/jsap/070109. doi: 10.18576/jsap/070109
|
| [17] | C. Canuto, M. Y. Hussaini, A. Quarteroni, T. A. Zang, Spectral methods: Fundamentals in single domains, New York: Springer-Verlag, 2006. doi: 10.1007/978-3-540-30726-6. |
| [18] | B. C. Arnold, N. Balakrishnan, H. N. Nagaraja, A first course in order statistics, Society of Industrial and Applied Mathematics, 1992. doi: 10.1137/1.9780898719062. |
| [19] | H. A. David, H. A. Nagaraja, Order statistics, Hoboken (NJ): John Wiley & Sons, 2003. |
| [20] |
H. K. Yuen, S. K. Tse, Parameters estimation for Weibull distributed lifetimes under progressive censoring with random removals, J. Stat. Comput. Simul., 55 (1996), 57–71. doi: 10.1080/00949659608811749. doi: 10.1080/00949659608811749
|
| [21] |
H. A. Zeinab, Bayesian inference for the pareto lifetime model under progressive censoring with binomial removals, J. Appl. Stat., 35 (2008), 1203–1217. doi: 10.1080/09537280802187634. doi: 10.1080/09537280802187634
|
| [22] | N. Balakrishnan, R. Aggarwala, Progressive censoring: Theory, methods, and applications, Boston: Birkh$\ddot{\text a}$user, 2000. |
| [23] |
A. Zellner, Bayesian estimation and prediction using asymmetric loss function, J. Am. Stat. Assoc., 81 (1986), 446–451. doi: 10.1080/01621459.1986.10478289
|
| [24] |
R. Srivastava, V. Tanna, An estimation procedure for error variance incorporating PTS for random effects model under LINEX loss function, Commun. Stat. Theor. Meth., 30 (2001), 2583–2599. doi: 10.1081/STA-100108449. doi: 10.1081/STA-100108449
|
| [25] | H. R. Varian, Bayesian approach to real estate assessment, In: L. J. Savage, S. E. Feinderg, A. Zellner, Studies in Bayesian econometrics and statistics, North-Holland, Amsterdam, (1975), 195–208. |
| [26] |
R. Calabria, G. Pulcini, An engineering approach to Bayes estimation for the Weibull distribution, Microelectron. Reliab., 34 (1994), 789–802. doi: 10.1016/0026-2714(94)90004-3. doi: 10.1016/0026-2714(94)90004-3
|
| [27] |
S. K. Upadhyay, A. A. Gupta, Bayes analysis of modified Weibull distribution via Markov chain Monte Carlo simulation, J. Stat. Comput. Simul., 80 (2010), 241–254. doi: 10.1080/00949650802600730. doi: 10.1080/00949650802600730
|
| [28] |
B. Al-Zahrani, H. Sagor, The poisson-lomax distribution, Rev. Colomb. Estad., 37 (2014), 223–243. doi: 10.15446/rce.v37n1.44369. doi: 10.15446/rce.v37n1.44369
|
| [29] | I. B. Abdul-Moniem, H. F. Abdel-Hameed, On exponentiated Lomax distribution, Int. J. Math. Educ., 3 (2012), 2144–2150. |
| [30] |
V. Choulakian, M. A. Stephens, Goodness-of-fit for the generalized Pareto distribution, Technometrics, 43 (2001), 478–484. doi: 10.1198/00401700152672573. doi: 10.1198/00401700152672573
|
| [31] |
R. D. Gupta, D. Kundu, A new class of weighted exponential distributions, Statistics, 43 (2009), 621–634. doi: 10.1080/02331880802605346. doi: 10.1080/02331880802605346
|
| [32] | N. Balakrishnan, R. A. Sandhu, A simple simulation algorithm for generating progressive type-II censored samples, Am. Stat., 49 (1995), 229–230. |
| [33] | J. S. Maritz, T. Lwin, Empirical bayes methods, 2 Eds, London: Chapman and Hall/CRC, 1989. doi: 10.1201/9781351071666. |
| [34] | J. M. Bernardo, A. F. M. Smith, Bayesian theory, New York: John Wiley & Sons, 1994. |



Figures(4) / Tables(4)

Tahani A. Abushal, Alaa H. Abdel-Hamid. Inference on a new distribution under progressive-stress accelerated life tests and progressive type-II censoring based on a series-parallel system[J]. AIMS Mathematics, 2022, 7(1): 425-454. doi: 10.3934/math.2022028







 DownLoad:
DownLoad: