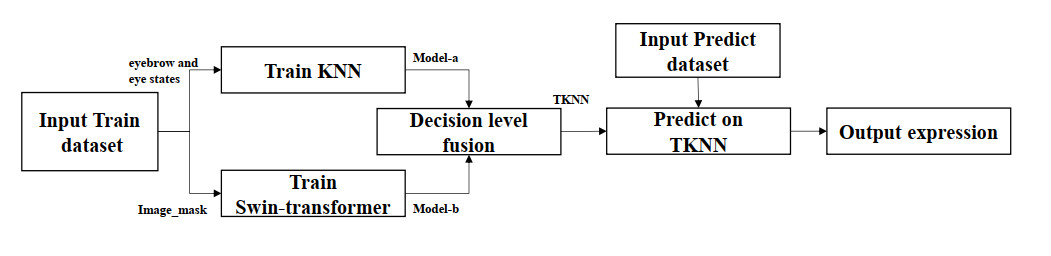
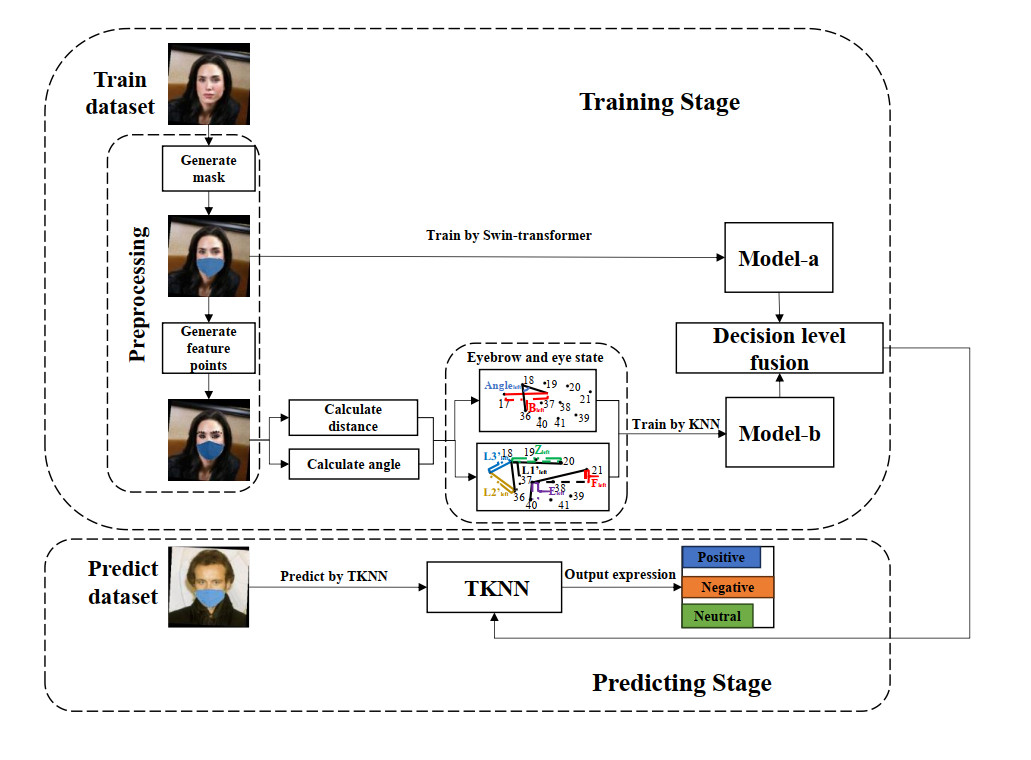
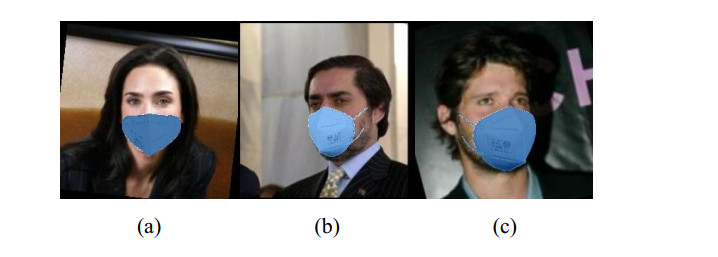
Facial expression recognition plays a crucial role in human-computer intelligent interaction. Due to the problem of missing facial information caused by face masks, the average accuracy of facial expression recognition algorithms in mask-obscured scenes is relatively low. At present, most deep learning-based facial expression recognition methods primarily focus on global facial features, thus they are less suitable for scenarios where facial expressions are obscured by masks. Therefore, this paper proposes a facial expression recognition method, TransformerKNN (TKNN), which integrates eyebrow and eye state information in mask-obscured scenes. The proposed method utilizes facial feature points in the eyebrow and eye regions to calculate various relative distances and angles, capturing the state information of eyebrows and eyes. Subsequently, the original face images with masks are used to train a Swin-transformer model, and the eyebrow and eye state information is used to train a k-Nearest Neighbor (KNN) model. These models are then fused at the decision layer to achieve automated emotion computation in situations when facial expressions are obscured by masks. The TKNN method offers a novel approach by leveraging both local and global facial features, thereby enhancing the performance of facial expression recognition in mask-obscured scenes. Experimental results demonstrate that the average accuracy of the TKNN method is 85.8% and 70.3%, respectively. This provides better support for facial expression recognition in scenarios when facial information is partially obscured.
Citation: Kun Zheng, Li Tian, Zichong Li, Hui Li, Junjie Zhang. Incorporating eyebrow and eye state information for facial expression recognition in mask-obscured scenes[J]. Electronic Research Archive, 2024, 32(4): 2745-2771. doi: 10.3934/era.2024124
Facial expression recognition plays a crucial role in human-computer intelligent interaction. Due to the problem of missing facial information caused by face masks, the average accuracy of facial expression recognition algorithms in mask-obscured scenes is relatively low. At present, most deep learning-based facial expression recognition methods primarily focus on global facial features, thus they are less suitable for scenarios where facial expressions are obscured by masks. Therefore, this paper proposes a facial expression recognition method, TransformerKNN (TKNN), which integrates eyebrow and eye state information in mask-obscured scenes. The proposed method utilizes facial feature points in the eyebrow and eye regions to calculate various relative distances and angles, capturing the state information of eyebrows and eyes. Subsequently, the original face images with masks are used to train a Swin-transformer model, and the eyebrow and eye state information is used to train a k-Nearest Neighbor (KNN) model. These models are then fused at the decision layer to achieve automated emotion computation in situations when facial expressions are obscured by masks. The TKNN method offers a novel approach by leveraging both local and global facial features, thereby enhancing the performance of facial expression recognition in mask-obscured scenes. Experimental results demonstrate that the average accuracy of the TKNN method is 85.8% and 70.3%, respectively. This provides better support for facial expression recognition in scenarios when facial information is partially obscured.

| [1] |
P. Ekman, Facial expression and emotion, Am. Psychol., 48 (1993), 384392. https://doi.org/10.1037/0003-066X.48.4.384 doi: 10.1037/0003-066X.48.4.384

|
| [2] |
L. Zhang, B. K. Verma, D. Tjondronegoro, V. Chandran, Facial expression analysis under partial occlusion: A survey, ACM Comput. Surv., 51 (2018), 1−49. https://doi.org/10.1145/3158369 doi: 10.1145/3158369
|
| [3] |
I. Kotsia, I. Buciu, I. Pitas, An analysis of facial expression recognition under partial facial image occlusion, Image Vision Comput., 26 (2008), 10521067. https://doi.org/10.1016/j.imavis.2007.11.004 doi: 10.1016/j.imavis.2007.11.004
|
| [4] |
H. K. Wong, A. J. Estudillo, Face masks affect emotion categorisation, age estimation, recognition, and gender classification from faces, Cognit. Res. Princ. Implic., 7 (2022). https://doi.org/10.1186/s41235-022-00438-x doi: 10.1186/s41235-022-00438-x
|
| [5] |
H. Cooper, A. Brar, H. Beyaztas, B. J. Jennings, R. J. Bennetts, The effects of face coverings, own-ethnicity biases, and attitudes on emotion recognition, Cogn. Res., 7 (2022). https://doi.org/10.1186/s41235-022-00400-x doi: 10.1186/s41235-022-00400-x
|
| [6] |
F. Grundmann, K. Epstude, S. Scheibe, Face masks reduce emotion-recognition accuracy and perceived closeness, Plos One, 16 (2021), e0249792. https://doi.org/10.1371/journal.pone.0249792 doi: 10.1371/journal.pone.0249792
|
| [7] |
M. Marini, A. Ansani, F. Paglieri, F. Caruana, M. Viola, The impact of facemasks on emotion recognition, trust attribution and re-identification, Sci. Rep., 11 (2021), 5577. https://doi.org/10.1038/s41598-021-84806-5 doi: 10.1038/s41598-021-84806-5
|
| [8] |
L. Zhang, D. Tjondronegoro, V. Chandran, Random Gabor based templates for facial expression recognition in images with facial occlusion, Neurocomputing, 145 (2014), 451464. https://doi.org/10.1016/j.neucom.2014.05.008 doi: 10.1016/j.neucom.2014.05.008
|
| [9] | P. Lucey, J. F. Cohn, T. Kanade, J. Saragih, Z. Ambada, The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression, in 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, IEEE, (2010), 94−101. |
| [10] | M. Lyons, S. Akamatsu, M. Kamachi, J. Gyoba, Coding facial expressions with Gabor wavelets, in Proceedings of The 3rd IEEE International Conference on Automatic Face and Gesture Recognition, IEEE, (1998), 200205. https://doi.org/10.1109/AFGR.1998.670949 |
| [11] | H. Ding, P. Zhou, R. Chellappa, Occlusion-adaptive deep network for robust facial expression recognition, in 2020 IEEE International Joint Conference on Biometrics (IJCB), IEEE, (2020). https://doi.org/10.1109/IJCB48548.2020.9304923 |
| [12] | E. Barsoum, C. Zhang, C. C. Ferrer, Z. Y. Zhang, Training deep networks for facial expression recognition with crowd-sourced label distribution, in 18th ACM International Conference on Multimodal Interaction, ACM, (2016), 279283. https://doi.org/10.1145/2993148.2993165 |
| [13] | A. Mollahosseini, B. Hasani, M. H. Mahoor, Affectnet: A database for facial expression, valence, and arousal computing in the wild, IEEE Trans. Affective Comput., 10 (2017), 18–31. https://doi.org/10.1109/TAFFC.2017.2740923 |
| [14] |
K. Wang, X. J. Peng, J. F. Yang, D. Meng, Y. Qiao, Region attention networks for pose and occlusion robust facial expression recognition, IEEE Trans. Image Process., 29 (2020), 4057–4069. https://doi.org/10.1109/TIP.2019.2956143 doi: 10.1109/TIP.2019.2956143
|
| [15] | S. Li, W. Deng, J. P. Du, Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild, in Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition, IEEE, (2017), 2852–2861. |
| [16] |
A. Dapogny, K. Bailly, S. Dubuisson, Confidence-weighted local expression predictions for occlusion handling in expression recognition and action unit detection, Int. J. Comput. Vision, 126 (2018), 255–271. https://doi.org/10.1007/s11263-017-1010-1 doi: 10.1007/s11263-017-1010-1
|
| [17] | H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, H. Jegou, Training data-efficient image transformers & distillation through attention, in International Conference on Machine Learning, (2021), 10347–10357 |
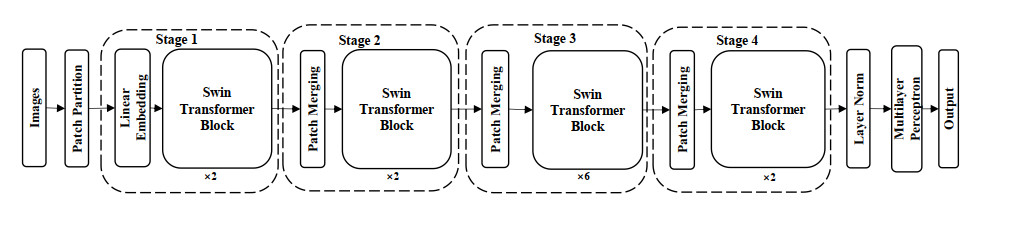
| [18] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in Proceedings of The IEEE/CVF International Conference on Computer Vision, IEEE, (2021), 10012–10022. https://doi.org/10.1109/ICCV48922.2021.00986 |
| [19] | D. Poux, B. Allaert, N. Ihaddadene, I. M. Bilasco, C. Djeraba, M. Bennamoun, et al., Dynamic facial expression recognition under partial occlusion with optical flow reconstruction, IEEE Trans. Image Process., 31 (2021), 446–457. https://doi.org/10.1109/TIP.2021.3129120 |
| [20] |
J. Lou, Y. Wang, C. Nduka, M. Hamedi, I. Mavridou, F. Y. Wang, Realistic facial expression reconstruction for VR HMD users, IEEE Trans. Multimedia, 22 (2019), 730–743. https://doi.org/10.1109/TMM.2019.2933338 doi: 10.1109/TMM.2019.2933338
|
| [21] |
L. Itti, C. Koch, Computational modelling of visual attention, Nat. Rev. Neurosci., 2 (2001), 194–203. https://doi.org/10.1038/35058500 doi: 10.1038/35058500
|
| [22] | Y. Li, J. Zeng, S. Shan, X. Chen, Occlusion aware facial expression recognition using CNN with attention mechanism. IEEE Trans. Image Process., 28 (2018), 2439–2450. |
| [23] |
S. Liu, W. Guo, Y. Zhang, X. Cheng, Robust regularized encoding for random occlusion facial expression recognition, CAAI Trans. Intell. Syst., 13 (2018), 261–268. https://doi.org/10.11992/tis.201609002 doi: 10.11992/tis.201609002
|
| [24] | X. Ben, M. Yang, P. Zhang, J. Li, Overview of automatic micro-expression recognition, J. Comput. Aided Design Comput. Graphics, 26 (2014), 1385–1395. |
| [25] |
S. Ramachandra, S. Ramachandran, Region specific and subimage based neighbour gradient feature extraction for robust periocular recognition, J. King Saud. Univ. Comput. Inf. Sci., 34 (2022), 7961–7973. https://doi.org/10.1016/j.jksuci.2022.07.013 doi: 10.1016/j.jksuci.2022.07.013
|
| [26] |
M. Okawa, Synergy of foreground-background images for feature extraction: Offline signature verification using Fisher vector with fused KAZE features, Pattern Recognit., 79 (2018), 480–489. https://doi.org/10.1016/j.patcog.2018.02.027 doi: 10.1016/j.patcog.2018.02.027
|
| [27] | N. Dalal, B. Triggs, Histograms of oriented gradients for human detection, in Proceedings of The 2005 IEEE Computer Society Conference on Computer Vision And Pattern Recognition, (2005), 886–893. https://doi.org/10.1109/CVPR.2005.177f |
| [28] | B. Huang, Z. Wang, G. Wang, Z. Han, K. Jiang, Local eyebrow feature attention network for masked face recognition, ACM Trans. Multimedia Comput. Commun. Appl., 19 (2023). https://doi.org/10.1145/3569943 |
| [29] | K. Zheng, K. Ci, H. Li, L. Shao, G. Sun, J. Liu, et al., Heart rate prediction from facial video with masks using eye location and corrected by convolutional neural networks, Biomed. Signal Process. Control, 75 (2022), 103609. https://doi.org/10.1016/j.bspc.2022.103609 |
| [30] |
P. Viola, M. J. Jones, Robust real-time face detection, Int. J. Comput. Vision, 57 (2004), 137–154. https://10.1023/B:VISI.0000013087.49260.fb doi: 10.1023/B:VISI.0000013087.49260.fb
|
| [31] | D. Li, Y. Ren, T. Du, W. Liu, Eyebrow semantic description via clustering based on Axiomatic Fuzzy Set, Wiley Int. Rev. Data Mining Knowl. Discovery, 8 (2018), e1275. https://doi.org/10.1002/widm.1275 |
| [32] |
J. Zhang, K. Zheng, S. Mazhar, X. Fu, J. Kong, Trusted emotion recognition based on multiple signals captured from video, Expert Syst. Appl., 233 (2023), 120948. https://doi.org/10.1016/j.eswa.2023.120948 doi: 10.1016/j.eswa.2023.120948
|
| [33] |
H. Tao, Q. Duan, M. Lu, Z. Hu, Learning discriminative feature representation with pixel-level supervision for forest smoke recognition, Pattern Recognit., 143 (2023), 109761. https://doi.org/10.1016/j.patcog.2023.109761 doi: 10.1016/j.patcog.2023.109761
|
| [34] | H. Tao, Q. Duan, Hierarchical attention network with progressive feature fusion for facial expression recognition, Neural Networks, 170 (2024), 337–348. |
| [35] | A. Anwar, A. Raychowdhury, Masked face recognition for secure authentication, preprint, arXiv: 2008.11104. https://arXiv.org/2008.11104v1. |
| [36] | V. Kazemi, J. Sullivan, One millisecond face alignment with an ensemble of regression trees, in Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition, (2014), 1867–1874. https://doi.org/10.1109/CVPR.2014.241 |
| [37] | B. Yang, J. Wu, G. Hattori, Facial expression recognition with the advent of face masks, in Proceedings of The 19th International Conference on Mobile And Ubiquitous Multimedia, (2020), 335–337. https://doi.org/10.1145/3428361.3432075 |
| [38] | B. Huang, M. Mattar, T. Berg, E. Learned-Miller, Labeled faces in the wild: A database for studying face recognition in unconstrained environments, in Workshop on Faces In 'Real-Life' Images: Detection, Alignment, And Recognition, (2008). |
| [39] |
K. Zhang, Z. Zhang, Z. Li, Y. Qiao, Joint face detection and alignment using multitask cascaded convolutional networks, IEEE Signal Process. Lett., 23 (2016), 1499–1503. https://doi.org/10.1109/LSP.2016.2603342 doi: 10.1109/LSP.2016.2603342
|
| [40] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition, (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [41] | K. Zheng, B. Li, Y. Li, P. Chang, G. Sun, H. Li, et al., Fall detection based on dynamic key points incorporating preposed attention, Math. Biosci. Eng., 20 (2023), 11238–11259. https://doi.org/10.3934/mbe.2023498 |





Figures(13) / Tables(11)
Kun Zheng, Li Tian, Zichong Li, Hui Li, Junjie Zhang. Incorporating eyebrow and eye state information for facial expression recognition in mask-obscured scenes[J]. Electronic Research Archive, 2024, 32(4): 2745-2771. doi: 10.3934/era.2024124







 DownLoad:
DownLoad: