In this paper, we integrated machine learning into the field of quantitative investment and established a set of automatic stock selection and investment timing models. Based on the validity test of factors, a multi-factor stock selection model was established to select stocks with the highest investment value to create a stock pool. By comparing the cumulative returns and the overall market returns of different timing signals over the same time period, both the decision tree and the long short-term memory (LSTM) models had great results. Finally, empirical research was reported to show that it is a good combination to introduce machine learning algorithms into quantitative timing.
Citation: Yufei Duan, Xian-Ming Gu, Tingyu Lei. Application of machine learning in quantitative timing model based on factor stock selection[J]. Electronic Research Archive, 2024, 32(1): 174-192. doi: 10.3934/era.2024009
In this paper, we integrated machine learning into the field of quantitative investment and established a set of automatic stock selection and investment timing models. Based on the validity test of factors, a multi-factor stock selection model was established to select stocks with the highest investment value to create a stock pool. By comparing the cumulative returns and the overall market returns of different timing signals over the same time period, both the decision tree and the long short-term memory (LSTM) models had great results. Finally, empirical research was reported to show that it is a good combination to introduce machine learning algorithms into quantitative timing.

| [1] | A. McAfee, E. Brynjolfsson, T. H. Patil, D. Barton, Big data: the management revolution, Harv. Bus. Rev., 90 (2012), 60–68. |
| [2] |
E. A. Gerlein, M. McGinnity, A. Belatreche, S. Coleman, Evaluating machine learning classification for financial trading: An empirical approach, Expert Syst. Appl., 54 (2016), 193–207. https://doi.org/10.1016/j.eswa.2016.01.018 doi: 10.1016/j.eswa.2016.01.018

|
| [3] |
S. M. Zhao, H. L. Yan, K. Zhang, Does fama-french five factor model outperform three factor model? Evidence from China's A-share market, Nankai Econ. Stud., 32 (2016), 41–59. https://doi.org/10.14116/j.nkes.2016.02.003 doi: 10.14116/j.nkes.2016.02.003
|
| [4] |
J. J. Wang, Z. Z. Zhuang, L. Feng, Intelligent optimization based multi-factor deep learning stock selection model and quantitative trading strategy, Mathematics, 10 (2022), 566. https://doi.org/10.3390/math10040566 doi: 10.3390/math10040566
|
| [5] |
N. Nguyen, D. Nguyen, Global stock selection with hidden Markov model, Risks, 9 (2020), 9. https://doi.org/10.3390/risks9010009 doi: 10.3390/risks9010009
|
| [6] |
A. Baykasoǧlu, Í. Gölcük, Development of a novel multiple-attribute decision making model via fuzzy cognitive maps and hierarchical fuzzy TOPSIS, Inf. Sci., 301 (2015), 75–98. https://doi.org/10.1016/j.ins.2014.12.048 doi: 10.1016/j.ins.2014.12.048
|
| [7] |
X. Zhong, D. Enke, Forecasting daily stock market return using dimensionality reduction, Expert. Syst. Appl., 67 (2017), 126–139. https://doi.org/10.1016/j.eswa.2016.09.027 doi: 10.1016/j.eswa.2016.09.027
|
| [8] |
F. W. Jiang, H. Xue, M. Zhou, Does big data improve multi-factor asset pricing models? Exploration of China's A-share market with machine learning, Syst. Eng.-Theory Pract., 42 (2022), 2037–2048. https://doi.org/10.12011/SETP2021-2552 doi: 10.12011/SETP2021-2552
|
| [9] |
W. W. Jiang, Applications of deep learning in stock market prediction: recent progress, Expert Syst. Appl., 184 (2021), 115537. https://doi.org/10.1016/j.eswa.2021.115537 doi: 10.1016/j.eswa.2021.115537
|
| [10] |
G. Sonkavde, D. S. Dharrao, A. M. Bongale, S. T. Deokate, D. Doreswamy, S. K. Bhat, Forecasting stock market prices using machine learning and deep learning models: A systematic review, performance analysis and discussion of implications, Int. J. Financial Stud., 11 (2023), 94. https://doi.org/10.3390/ijfs11030094 doi: 10.3390/ijfs11030094
|
| [11] |
P. Tenti, Forecasting foreign exchange rates using recurrent neural networks, Appl. Artif. Intell., 10 (1996), 567–582. https://doi.org/10.1080/088395196118434 doi: 10.1080/088395196118434
|
| [12] |
F. E. Tay, L. Cao, Application of support vector machines in financial time series forecasting, Omega, 29 (2001), 309–317. https://doi.org/10.1016/S0305-0483(01)00026-3 doi: 10.1016/S0305-0483(01)00026-3
|
| [13] |
Y. Deng, F. Bao, Y. Kong, Z. Ren, Q. Dai, Deep direct reinforcement learning for financial signal representation and trading, IEEE Trans. Neural Netw. Learn. Syst., 28 (2016), 653–664. https://doi.org/10.1109/TNNLS.2016.2522401 doi: 10.1109/TNNLS.2016.2522401
|
| [14] | J. Kamruzzaman, R. Sarker, Comparing ANN based models with ARIMA for prediction of forex rates, Asor Bulletin, 22 (2003), 2–11. |
| [15] |
J. Patel, S. Shah, P. Thakkar, K. Kotecha, Predicting stock and stock price index movement using trend deterministic data preparation and machine learning techniques, Expert Syst. Appl., 42 (2015), 259–268. https://doi.org/10.1016/j.eswa.2014.07.040 doi: 10.1016/j.eswa.2014.07.040
|
| [16] |
G. J. Jiang, G. R. Zaynutdinova, H. Zhang, Stock-selection timing, J. Bank. Finance, 125 (2021), 106089. https://doi.org/10.1016/j.jbankfin.2021.106089 doi: 10.1016/j.jbankfin.2021.106089
|
| [17] |
K. C. Rasekhschaffe, R. C. Jones, Machine learning for stock selection, Financ. Anal. J., 75 (2019), 70–88. https://doi.org/10.1080/0015198X.2019.1596678 doi: 10.1080/0015198X.2019.1596678
|
| [18] |
M. Li, H. Xu, Y. Deng, Evidential decision tree based on belief entropy, Entropy, 21 (2019), 897. https://doi.org/10.3390/e21090897 doi: 10.3390/e21090897
|
| [19] |
S. G. Deb, A. Banerjee, B. B. Chakrabarti, Market timing and stock selection ability of mutual funds in India: an empirical investigation, Vikalpa, 32 (2007), 39–52. https://doi.org/10.1177/0256090920070204 doi: 10.1177/0256090920070204
|
| [20] | M. J. Zhang, H. C. Rao, J. X. Nan, G. D. Wang, Quantitative trading timing strategy based on decision tree, Syst. Eng., 40 (2022), 118–130. |
| [21] | S. Hochreiter, J. Schmidhuber, LSTM can solve hard long time lag problems, in Proceedings of the 9th International Conference on Neural Information Processing Systems, MIT Press, Cambridge, MA, (1996), 473–479. |
| [22] |
H. Yao, S. Xia, H. Liu, Six-factor asset pricing and portfolio investment via deep learning: Evidence from Chinese stock market, Pac. Basin. Finance J., 76 (2022), 101886. https://doi.org/10.1016/j.pacfin.2022.101886 doi: 10.1016/j.pacfin.2022.101886
|
| [23] |
A. Suáez, J. F. Lutsko, Globally optimal fuzzy decision trees for classification and regression, IEEE Trans. Pattern Anal. Mach. Intell., 21 (1999), 1297–1311. https://doi.org/10.1109/34.817409 doi: 10.1109/34.817409
|
| [24] |
C. Ma, G. Dai, J. Zhou, Short-term traffic flow prediction for urban road sections based on time series analysis and LSTM_BILSTM method, IEEE Trans. Intell. Transp. Syst., 23 (2021), 5615–5624. https://doi.org/10.1109/tits.2021.3055258 doi: 10.1109/tits.2021.3055258
|

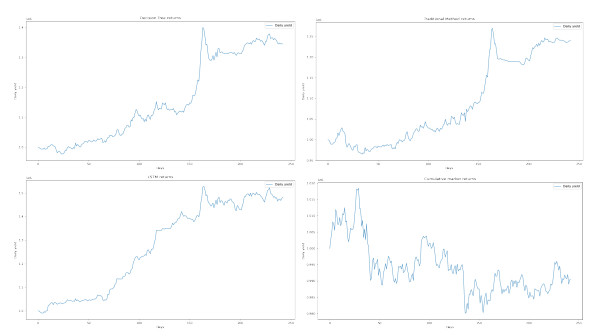
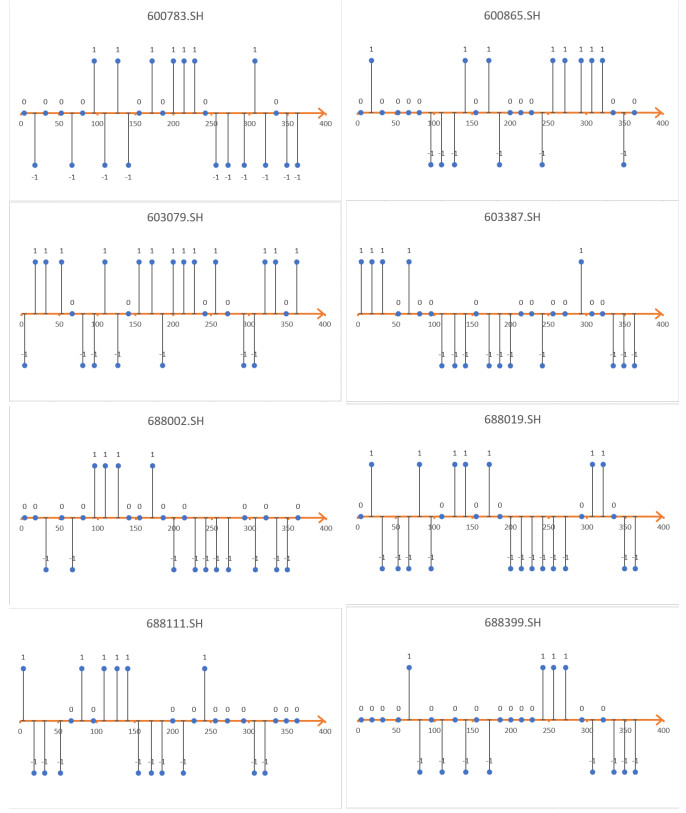
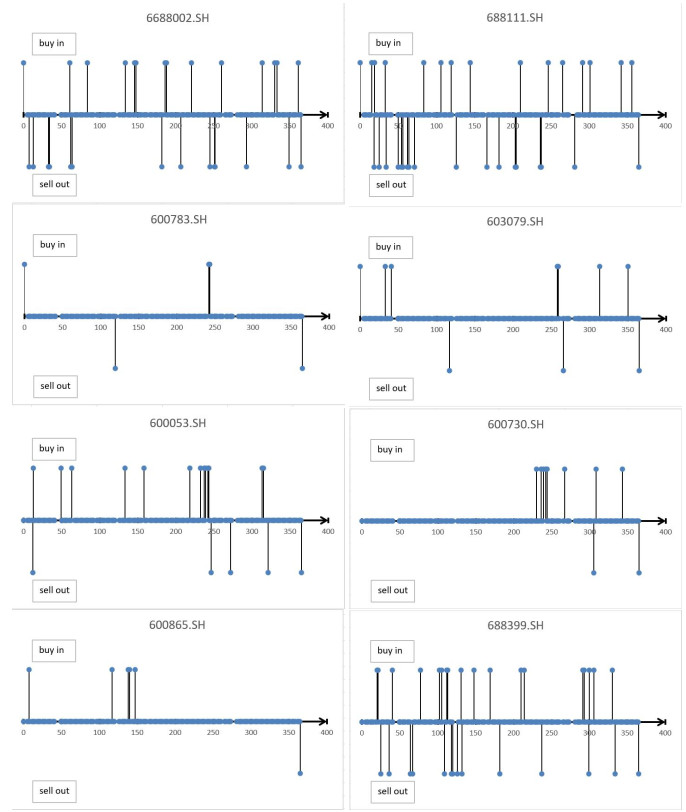
Figures(16) / Tables(5)
Yufei Duan, Xian-Ming Gu, Tingyu Lei. Application of machine learning in quantitative timing model based on factor stock selection[J]. Electronic Research Archive, 2024, 32(1): 174-192. doi: 10.3934/era.2024009







 DownLoad:
DownLoad: