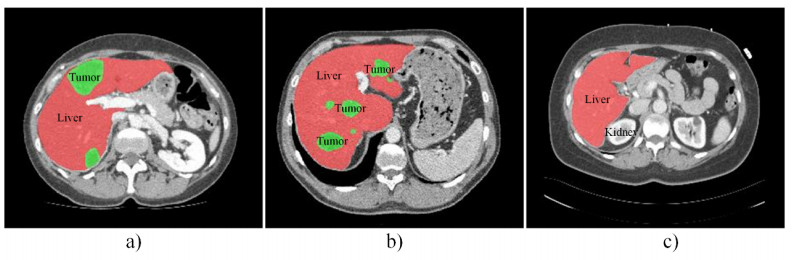
The existing 2D/3D strategies still have limitations in human liver and tumor segmentation efficiency. Therefore, this paper proposes a 2.5D network combing cascaded context module (CCM) and Ladder Atrous Spatial Pyramid Pooling (L-ASPP), named CCLNet, for automatic liver and tumor segmentation from CT. First, we utilize the 2.5D mode to improve the training efficiency; Second, we employ the ResNet-34 as the encoder to enhance the segmentation accuracy. Third, the L-ASPP module is used to enlarge the receptive field. Finally, the CCM captures more local and global feature information. We experimented on the LiTS17 and 3DIRCADb datasets. Experimental results prove that the method skillfully balances accuracy and cost, thus having good prospects in liver and liver segmentation in clinical assistance.
Citation: Rongrong Bi, Liang Guo, Botao Yang, Jinke Wang, Changfa Shi. 2.5D cascaded context-based network for liver and tumor segmentation from CT images[J]. Electronic Research Archive, 2023, 31(8): 4324-4345. doi: 10.3934/era.2023221
The existing 2D/3D strategies still have limitations in human liver and tumor segmentation efficiency. Therefore, this paper proposes a 2.5D network combing cascaded context module (CCM) and Ladder Atrous Spatial Pyramid Pooling (L-ASPP), named CCLNet, for automatic liver and tumor segmentation from CT. First, we utilize the 2.5D mode to improve the training efficiency; Second, we employ the ResNet-34 as the encoder to enhance the segmentation accuracy. Third, the L-ASPP module is used to enlarge the receptive field. Finally, the CCM captures more local and global feature information. We experimented on the LiTS17 and 3DIRCADb datasets. Experimental results prove that the method skillfully balances accuracy and cost, thus having good prospects in liver and liver segmentation in clinical assistance.

| [1] |
J. Ferlay, M. Colombet, I. Soerjomataram, D. M. Parkin, M. Piñeros, A. Znaor, et al., Cancer statistics for the year 2020: An overview, Int. J. Cancer, 149 (2021), 778–789. https://doi.org/10.1002/ijc.33588 doi: 10.1002/ijc.33588

|
| [2] |
P. Bilic, P. Christ, B. H. Li, E. Vorontsov, A. Ben-Cohen, G. Kaissis, et al., The liver tumor segmentation benchmark (LiTs), Med. Image Anal., 84 (2023), 102680. https://doi.org/10.1016/j.media.2022.102680 doi: 10.1016/j.media.2022.102680
|
| [3] |
J. Calderaro, M. Ziol, V. Paradis, J. Zucman-Rossi, Molecular and histological correlations in liver cancer, J. Hepatol., 71 (2019), 616–630. https://doi.org/10.1016/j.jhep.2019.06.001 doi: 10.1016/j.jhep.2019.06.001
|
| [4] | J. Long, E. Shelhamer, T. Darrell, Fully convolutional networks for semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Boston, USA, (2015), 3431–3440. https://doi.org/10.1109/CVPR.2015.7298965 |
| [5] | A. Ben-Cohen, I. Diamant, E. Klang, M. Amitai, H. Greenspan, Fully convolutional network for liver segmentation and lesions detection, in Deep Learning and Data Labeling for Medical Applications, Springer, Athens, Greece, (2016), 77–85. https://doi.org/10.1007/978-3-319-46976-8_9 |
| [6] | Y. Zhang, Z. He, C. Zhong, Y. Zhang, Z. Shi, Fully convolutional neural network with post-processing methods for automatic liver segmentation from CT, in 2017 Chinese Automation Congress (CAC), IEEE, Jinan, China, (2017), 3864–3869. https://doi.org/10.1109/CAC.2017.8243454 |
| [7] |
H. Jiang, T. Shi, Z. Bai, L. Huang, Ahcnet: an application of attention mechanism and hybrid connection for liver tumor segmentation in CT volumes, IEEE Access, 7 (2019), 24898–24909. https://doi.org/10.1109/access.2019.2899608 doi: 10.1109/access.2019.2899608
|
| [8] | F. P. Christ, A. E. M. Elshaer, F. Ettlinger, S. Tatavarty, M. Bickel, P. Bilic, et al., Automatic liver and lesion segmentation in CT using cascaded fully convolutional neural networks and 3D conditional random fields, in International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, Athens, Greece, (2016), 415–423. https://doi.org/10.1007/978-3-319-46723-8_48 |
| [9] | O. Ronneberger, P. Fischer, T. Brox, U-net: convolutional networks for biomedical image segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, Munich, Germany, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |
| [10] |
H. Seo, C. Huang, M. Bassenne, R. Xiao, L. Xing, Modified U-Net (mU-Net) with incorporation of object-dependent high level features for improved liver and liver-tumor segmentation in CT images, IEEE Trans. Med. Imaging, 39 (2019), 1316–1325. https://doi.org/10.1109/TMI.2019.2948320 doi: 10.1109/TMI.2019.2948320
|
| [11] |
J. Wang, P. Lv, H. Wang, C. Shi, SAR-U-Net: squeeze-and-excitation block and atrous spatial pyramid pooling based residual U-Net for automatic liver segmentation in computed tomography, Comput. Methods Programs Biomed., 208 (2021), 106268. https://doi.org/10.1016/j.cmpb.2021.106268 doi: 10.1016/j.cmpb.2021.106268
|
| [12] |
Q. Jin, Z. Meng, C. Sun, H. Cui, R. Su, RA-UNet: a hybrid deep attention-aware network to extract liver and tumor in CT scans, Front. Bioeng. Biotechnol., 8 (2020), 1471. https://doi.org/10.3389/fbioe.2020.605132 doi: 10.3389/fbioe.2020.605132
|
| [13] |
X. Li, H. Chen, X. Qi, Q. Dou, C. W. Fu, P. A. Heng, H-DenseUNet: hybrid densely connected Unet for liver and tumor segmentation from CT volumes, IEEE Trans. Med. Imaging, 37 (2018), 2663–2674. https://doi.org/10.1109/TMI.2018.2845918 doi: 10.1109/TMI.2018.2845918
|
| [14] |
P. Lv, J. Wang, H. Wang, 2.5D lightweight RIU-Net for automatic liver and tumor segmentation from CT, Biomed. Signal Process. Control, 75 (2022), 103567. https://doi.org/10.1016/j.bspc.2022.103567 doi: 10.1016/j.bspc.2022.103567
|
| [15] |
L. Meng, Q. Zhang, S. Bu. Two-stage liver and tumor segmentation algorithm based on convolutional neural network, Diagnostics, 11 (2021), 1806. https://doi.org/10.3390/diagnostics11101806 doi: 10.3390/diagnostics11101806
|
| [16] |
F. Özcan, N. O. Uçan, S. Karaçam, D. Tunçman, Fully automatic liver and tumor segmentation from CT image using an AIM-Unet, Bioengineering, 10 (2023), 215. https://doi.org/10.3390/bioengineering10020215 doi: 10.3390/bioengineering10020215
|
| [17] |
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, et al., Generative adversarial networks, Commun. ACM, 63 (2020), 139–144. https://doi.org/10.1007/978-3-030-50017-7_16 doi: 10.1007/978-3-030-50017-7_16
|
| [18] |
Y. Enokiya, Y. Iwamoto, W. Y. Chen, X. H. Han, Automatic liver segmentation using U-net with Wasserstein GANs, Int. J. Image Graphics, 6 (2018), 152–159. https://doi.org/10.18178/joig.7.3.94-101 doi: 10.18178/joig.7.3.94-101
|
| [19] | D. Yang, D. Xu, S. K. Zhou, B. Georgescu, M. Chen, S. Grbic, et al., Automatic liver segmentation using an adversarial image-to-image network, in 20th International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, Quebe, Canada, (2017), 507–515. https://doi.org/10.1007/978-3-319-66179-7_58 |
| [20] | U. Demir, Z. Zhang, B. Wang, M. Antalek, E. Keles, D. Jha, et al., Transformer based generative adversarial network for liver segmentation, arXiv preprint, (2022), arXiv: 2205.10663. https://doi.org/10.48550/arXiv.2205.10663 |
| [21] |
C. Xu, Y. Wang, D. Zhang, L. Han, Y. Zhang, J. Chen, et al., BMAnet: boundary mining with adversarial learning for semi-supervised 2D myocardial infarction segmentation, IEEE J. Biomed. Health. Inf., 27 (2022), 87–96. https://doi.org/10.1109/JBHI.2022.3215536 doi: 10.1109/JBHI.2022.3215536
|
| [22] |
L. Chen, H. Song, C. Wang, Y. Cui, J. Yang, X. Hu, et al., Liver tumor segmentation in CT volumes using an adversarial densely connected network, BMC Bioinf., 20 (2019), 1–13. https://doi.org/10.1186/s12859-019-3069-x doi: 10.1186/s12859-019-3069-x
|
| [23] | A. G Roy, N. Navab, C. Wachinger, Concurrent spatial and channel 'squeeze & excitation' in fully convolutional networks, in 21th International Conference on Medical Image Computin and Computer-Assisted Intervention, Springer, Granada, Spain, (2018), 421–429. https://doi.org/10.1007/978-3-030-00928-1_48 |
| [24] |
T. Lei, R. Wang, Y. Zhang, Y. Wan, C. Liu, A. K. Nandi, DefED-Net: deformable encoder-decoder network for liver and liver tumor segmentation, IEEE Trans. Radiat. Plasma Med. Sci., 6 (2021), 68–78. https://doi.org/10.1109/TRPMS.2021.3059780 doi: 10.1109/TRPMS.2021.3059780
|
| [25] | T. C. Nguyen, T. P. Nguyen, G. H. Diep, A. H. Tran-Dinh, T. V. Nguyen, M. T. Tran, Ccbanet: cascading context and balancing attention for polyp segmentation, in 24th International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, Strasbourg, France, (2021), 633–643. https://doi.org/10.1007/978-3-030-87193-2_60 |
| [26] |
T. Heimann, B. Van Ginneken, M. Styner, Y. Arzhaeva, V. Aurich, C. Bauer, et al., Comparison and evaluation of methods for liver segmentation from CT datasets, IEEE Trans. Med. Imaging, 28 (2009), 1251–1265. https://doi.org/10.1109/TMI.2009.2013851 doi: 10.1109/TMI.2009.2013851
|
| [27] |
M. W. Li, D. Y. Xu, J. Geng, W. C. Hong, A hybrid approach for forecasting ship motion using CNN–GRU–AM and GCWOA, Appl. Soft Comput., 114 (2022), 108084. https://doi.org/10.1016/j.asoc.2021.108084 doi: 10.1016/j.asoc.2021.108084
|
| [28] | Y. Qiu, Y. Liu, S. Li, J. Xu, Miniseg: An extremely minimum network for efficient covid-19 segmentation, in Proceedings of the AAAI Conference on Artificial Intelligence, AAAI, (2021), 4846–4854. https://doi.org/10.1609/aaai.v35i6.16617 |
| [29] | O. Oktay, J. Schlemper, L. L. Folgoc, M. Lee, M. Heinrich, K. Misawa, et al., Attention U-Net: learning where to look for the pancreas, arXiv preprint, (2018), arXiv: 1804.03999. https://doi.org/10.48550/arXiv.1804.03999 |
| [30] |
D. T. Kushnure, S. N. Talbar, HFRU-Net: High-level feature fusion and recalibration unet for automatic liver and tumor segmentation in CT images, Comput. Methods Programs Biomed., 213 (2022), 106501. https://doi.org/10.1016/j.cmpb.2021.106501 doi: 10.1016/j.cmpb.2021.106501
|
| [31] |
Y. Chen, C. Zheng, F. Hu, T. Zhou, L. Feng, G. Xu, et al., Efficient two-step liver and tumour segmentation on abdominal CT via deep learning and a conditional random field, Comput. Biol. Med., 150 (2022), 106076. https://doi.org/10.1016/j.compbiomed.2022.106076 doi: 10.1016/j.compbiomed.2022.106076
|
| [32] |
R. K. Meleppat, C. R. Fortenbach, Y. Jian, E. S. Martinez, K. Wagner, B. S. Modjtahedi, et al., In Vivo imaging of retinal and choroidal morphology and vascular plexuses of vertebrates using swept-source optical coherence tomography, Transl. Vision Sci. Technol., 11 (2022), 11. https://doi.org/10.1167/tvst.11.8.11 doi: 10.1167/tvst.11.8.11
|
| [33] |
K. M. Ratheesh, L. K. Seah, V. M. Murukeshan, Spectral phase-based automatic calibration scheme for swept source-based optical coherence tomography systems, Phys. Med. Biol., 61 (2016), 7652. https://doi.org/10.1088/0031-9155/61/21/7652 doi: 10.1088/0031-9155/61/21/7652
|
| [34] |
R. K. Meleppat, K. E. Ronning, S. J. Karlen, K. K. Kothandat, M. E. Burns, E. N. Pugh, et al., In situ morphologic and spectral characterization of retinal pigment epithelium organelles in mice using multicolor confocal fluorescence imaging, Invest. Ophthalmol. Visual Sci., 61 (2020), 1. https://doi.org/10.1167/iovs.61.13.1 doi: 10.1167/iovs.61.13.1
|
| [35] |
R. K. Meleppat, C. Shearwood, S. L. Keey, M. V. Matham, Quantitative optical coherence microscopy for the in situ investigation of the biofilm, J. Biomed. Opt., 21 (2016), 127002–127002. https://doi.org/10.1117/1.JBO.21.12.127002 doi: 10.1117/1.JBO.21.12.127002
|
| [36] | V. M. Murukeshan, L. K. Seah, C. Shearwood, Quantification of biofilm thickness using a swept source based optical coherence tomography system, in International Conference on Optical and Photonic Engineering (icOPEN 2015), SPIE, Singapore, (2015), 683–688. https://doi.org/10.1117/12.2190106 |










Figures(11) / Tables(10)
Rongrong Bi, Liang Guo, Botao Yang, Jinke Wang, Changfa Shi. 2.5D cascaded context-based network for liver and tumor segmentation from CT images[J]. Electronic Research Archive, 2023, 31(8): 4324-4345. doi: 10.3934/era.2023221







 DownLoad:
DownLoad: