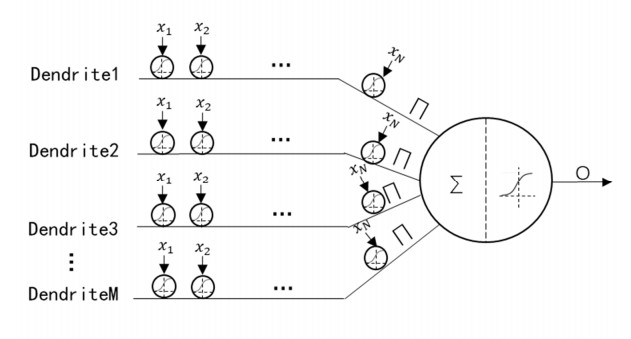
With the rapid development of meteorology, there requires a great need to better forecast dew point temperatures contributing to mild building surface and rational chemical control, while researches on time series forecasting barely catch the attention of meteorology. This paper would employ the seasonal-trend decomposition-based simplified dendritic neuron model (STLDNM*) to predict the dew point temperature. We utilize the seasonal-trend decomposition based on LOESS (STL) to extract three subseries from the original sequence, among which the residual part is considered as an input of an improved dendritic neuron model (DNM*). Then the back-propagation algorithm (BP) is used for training DNM* and the output is added to another two series disposed. Four datasets, which record dew points of four cities, along with eight algorithms are put into the experiments for comparison. Consequently, the combination of STL and simplified DNM achieves the best speed and accuracy.
Citation: Dongbao Jia, Zhongxun Xu, Yichen Wang, Rui Ma, Wenzheng Jiang, Yalong Qian, Qianjin Wang, Weixiang Xu. Application of intelligent time series prediction method to dew point forecast[J]. Electronic Research Archive, 2023, 31(5): 2878-2899. doi: 10.3934/era.2023145
With the rapid development of meteorology, there requires a great need to better forecast dew point temperatures contributing to mild building surface and rational chemical control, while researches on time series forecasting barely catch the attention of meteorology. This paper would employ the seasonal-trend decomposition-based simplified dendritic neuron model (STLDNM*) to predict the dew point temperature. We utilize the seasonal-trend decomposition based on LOESS (STL) to extract three subseries from the original sequence, among which the residual part is considered as an input of an improved dendritic neuron model (DNM*). Then the back-propagation algorithm (BP) is used for training DNM* and the output is added to another two series disposed. Four datasets, which record dew points of four cities, along with eight algorithms are put into the experiments for comparison. Consequently, the combination of STL and simplified DNM achieves the best speed and accuracy.

| [1] |
M. Fathi, M. H. Kashani, S. M. Jameii, E. Mahdipour, Big data analytics in weather forecasting: A systematic review, Arch. Comput. Methods Eng., 29 (2022), 1247–1275. https://doi.org/10.1007/s11831-021-09616-4 doi: 10.1007/s11831-021-09616-4

|
| [2] |
J. S. Leu, K. W. Su, C. T. Chen, Ambient mesoscale weather forecasting system featuring mobile augmented reality, Multimedia Tools Appl., 72 (2014), 1585–1609. https://doi.org/10.1007/s11042-013-1462-4 doi: 10.1007/s11042-013-1462-4
|
| [3] |
P. Roudier, B. Muller, P. d'Aquino, C. Roncoli, M. A. Soumaré, L. Batté, et al., The role of climate forecasts in smallholder agriculture: Lessons from participatory research in two communities in Senegal, Clim. Risk Manage., 2 (2014), 42–55. https://doi.org/10.1016/j.crm.2014.02.001 doi: 10.1016/j.crm.2014.02.001
|
| [4] |
S. C. Gao, M. C. Zhou, Z. Q. Wang, D. Sugiyama, J. Cheng, J. Wang, et al., Fully complex-valued dendritic neuron model, IEEE Trans. Neural Networks Learn. Syst., 2021 (2021), 1–14. https://doi.org/10.1109/TNNLS.2021.3105901 doi: 10.1109/TNNLS.2021.3105901
|
| [5] |
J. Shi, W. J. Lee, Y. Liu, Y. Yang, P. Wang, Forecasting power output of photovoltaic systems based on weather classification and support vector machines, IEEE Trans. Ind. Appl., 48 (2012), 1064–1069. https://doi.org/10.1109/TIA.2012.2190816 doi: 10.1109/TIA.2012.2190816
|
| [6] |
D. Lazos, A. B. Sproul, M. Kay, Optimisation of energy management in commercial buildings with weather forecasting inputs: A review, Renewable Sustainable Energy Rev., 39 (2014), 587–603. https://doi.org/10.1016/j.rser.2014.07.053 doi: 10.1016/j.rser.2014.07.053
|
| [7] |
D. B. Jia, W. X. Xu, D. Z. Liu, Z. X. Xu, Z. M. Zhong, X. X. Ban, Verification of classification model and dendritic neuron model based on machine learning, Discrete Dyn. Nat. Soc., 2022 (2022). https://doi.org/10.1155/2022/3259222 doi: 10.1155/2022/3259222
|
| [8] |
Q. H. Li, X. L. Wang, H. B. Yang, X. C. Liu, Research on water vapor release and adsorption mechanism to improve the measurement of dew Point humidity sensor, IEEE Sens. J., 21 (2021), 14666–14676. https://doi.org/10.1109/JSEN.2021.3074647 doi: 10.1109/JSEN.2021.3074647
|
| [9] |
J. J. Cheng, G. Y. Yuan, M. C. Zhou, S. Gao, C. Liu, H. Duan, A fluid mechanics-based data flow model to estimate VANET capacity, IEEE Trans. Intell. Transp. Syst., 21 (2020), 2603–2614. https://doi.org/10.1109/TITS.2019.2921074 doi: 10.1109/TITS.2019.2921074
|
| [10] |
M. G. Schultz, C. Betancourt, B. Gong, F. Kleinert, M. Langguth, L. H. Leufen, et al., Can deep learning beat numerical weather prediction, Phil. Trans. R. Soc. A, 379 (2021). https://doi.org/10.1098/rsta.2020.0097 doi: 10.1098/rsta.2020.0097
|
| [11] |
J. J. Cheng, X. Wu, M. C. Zhou, S. C. Gao, Z. H. Huang, C. Liu, A novel method for detecting new overlapping community in complex evolving networks, IEEE Trans. Syst. Man Cybern. Syst., 49 (2019), 1832–1844. https://doi.org/10.1109/TSMC.2017.2779138 doi: 10.1109/TSMC.2017.2779138
|
| [12] |
D. B. Jia, Y. Fujishita, C. H. Li, Y. Todo, H. W. Dai, Validation of large-scale classification problem in dendritic neuron model using particle antagonism mechanism, Electronics, 9 (2020). https://doi.org/10.3390/electronics9050792 doi: 10.3390/electronics9050792
|
| [13] |
J. J. Cheng, M. J. Chen, M. C. Zhou, S. C. Gao, C. N. Liu, C Liu, Overlapping community change-point detection in an evolving network, IEEE Trans. Big Data, 6 (2020), 189–200. https://doi.org/10.1109/TBDATA.2018.2880780 doi: 10.1109/TBDATA.2018.2880780
|
| [14] |
K. Fu, H. Li, P. Deng, Chaotic time series prediction using DTIGNet based on improved temporal-inception and GRU, Chaos, Solitons Fractals, 159 (2022), 2022, 112183. https://doi.org/10.1016/j.chaos.2022.112183 doi: 10.1016/j.chaos.2022.112183
|
| [15] |
H. Abbasimehr, F. S. Baghery, A novel time series clustering method with fine-tuned support vector regression for customer behavior analysis, Expert Syst. Appl., 204 (2022), 117584. https://doi.org/10.1016/j.eswa.2022.117584 doi: 10.1016/j.eswa.2022.117584
|
| [16] |
M. M. Öztürk, Initializing hyper-parameter tuning with a metaheuristic-ensemble method: A case study using time series weather data, Evol. Intell., 2022 (2022). https://doi.org/10.1007/s12065-022-00717-y doi: 10.1007/s12065-022-00717-y
|
| [17] |
D. B. Jia, H. W. Dai, Y. Takashima, T. Nishio, K. Hirobayashi, M. Hasegawa, et al., EEG processing in internet of medical things using non-harmonic analysis: Application and evolution for SSVEP responses, IEEE Access, 7 (2019), 11318–11327. https://doi.org/10.1109/ACCESS.2019.2892188 doi: 10.1109/ACCESS.2019.2892188
|
| [18] |
W. X. Xu, D. B. Jia, Z. M. Zhong, C. H. Li, Z. X. Xu, Intelligent dendritic neural model for classification problems, Symmetry, 14 (2022). https://doi.org/10.3390/sym14010011 doi: 10.3390/sym14010011
|
| [19] |
M. Rabbani, M. Musarat, W. Alaloul, M. Rabbani, A. Maqsoom, S. Ayub, et al., A comparison between seasonal autoregressive integrated moving average (SARIMA) and exponential smoothing (ES) based on time series model for forecasting road accidents, Arabian J. Sci. Eng., 46 (2021), 11113–11138. https://doi.org/10.1007/s13369-021-05650-3 doi: 10.1007/s13369-021-05650-3
|
| [20] |
J. N. K. Liu, B. N. L. Li, T. S. Dillon, An improved naive Bayesian classifier technique coupled with a novel input solution method[rainfall prediction], IEEE Trans. Syst. Man Cybern. Part C Appl. Rev., 31 (2021), 249–256. https://doi.org/10.1109/5326.941848 doi: 10.1109/5326.941848
|
| [21] |
F. Wang, Z. Zhen, Z. Mi, H. Sun, S. Su, G. Yang, Solar irradiance feature extraction and support vector machines based weather status pattern recognition model for short-term photovoltaic power forecasting, Energy Build., 86 (2015), 427–438. https://doi.org/10.1016/j.enbuild.2014.10.002 doi: 10.1016/j.enbuild.2014.10.002
|
| [22] |
J. An, F. Yin, M. Wu, J. She, X. Chen, Multisource wind speed fusion method for short-term wind power prediction, IEEE Trans. Ind. Inf., 17 (2021), 5927–5937. https://doi.org/10.1109/TⅡ.2020.3006928 doi: 10.1109/TⅡ.2020.3006928
|
| [23] |
J. Sun, S. C. Gao, H. W. Dai, J. Cheng, M. Zhou, J. Wang, Bi-objective elite differential evolution algorithm for multivalued logic networks, IEEE Trans. Cybern., 50 (2020), 233–246. https://doi.org/10.1109/TCYB.2018.2868493 doi: 10.1109/TCYB.2018.2868493
|
| [24] |
S. C. Gao, Y. Yu, Y. Wang, J. Wang, J. Cheng, M. Zhou, Chaotic local search-based differential evolution algorithms for optimization, IEEE Trans. Syst. Man Cybern.: Syst., 51 (2021), 3954–3967. https://doi.org/10.1109/TSMC.2019.2956121 doi: 10.1109/TSMC.2019.2956121
|
| [25] |
D. B. Jia, K. Yanagisawa, M. Hasegawa, S. Hirobayashi, H. Tagoshi, T. Narikawa, et al., Time-frequency based non-harmonic analysis to reduce line noise impact for LIGO observation system, Astron. Comput., 25 (2018), 238–246. https://doi.org/10.1016/j.ascom.2018.10.003 doi: 10.1016/j.ascom.2018.10.003
|
| [26] | Y. Cheng, R. Wu, The research of aviation dangerous weather forecast for fog and haze based on BP neural network, in Proceedings of the 5th International Conference on Electrical Engineering and Automatic Control, Springer, 367 (2016), 877–883. https://doi.org/10.1007/978-3-662-48768-6_97 |
| [27] |
X. M. Zhang, Y. Q. Zhou, H. J. Huang, Q. F. Luo, Enhanced salp search algorithm for optimization extreme learning machine and application to dew point temperature prediction, Int. J. Comput. Intell. Syst., 15 (2022). https://doi.org/10.1007/s44196-022-00160-y doi: 10.1007/s44196-022-00160-y
|
| [28] |
S. Gul, M. Khan, N. B. Yoma, S. W. Shah, Sheheryar, Enhancing the correlation between the quality and intelligibility objective metrics with the subjective scores by shallow feed forward neural network for time–frequency masking speech separation algorithms, Appl. Acoust., 188 (2022), 108539. https://doi.org/10.1016/j.apacoust.2021.108539 doi: 10.1016/j.apacoust.2021.108539
|
| [29] |
D. B. Jia, K. Yanagisawa, Y. Ono, K. Hirobayashi, M. Hasegawa, S. Hirobayashi, et al., Multiwindow nonharmonic analysis method for gravitational waves, IEEE Access, 6 (2018), 48645–48655. https://doi.org/10.1109/ACCESS.2018.2867494 doi: 10.1109/ACCESS.2018.2867494
|
| [30] |
B. R. Murlidar, H. Nguyen, J. Rostami, X. N. Bui, D. J. Armaghani, P. Ragam, et al., Prediction of flyrock distance induced by mine blasting using a novel Harris Hawks optimization-based multi-layer perceptron neural network, J. Rock Mech. Geotech. Eng., 13 (2021), 1413–1427. https://doi.org/10.1016/j.jrmge.2021.08.005 doi: 10.1016/j.jrmge.2021.08.005
|
| [31] |
J. J. Cheng, G. Y. Yuan, S. C. Gao, M. C. Zhou, C. Liu, H. Duan, et al., Accessibility analysis and modeling for IoV in an urban scene, IEEE Trans. Veh. Technol., 69 (2020), 4246–4256. https://doi.org/10.1109/TVT.2020.2970553 doi: 10.1109/TVT.2020.2970553
|
| [32] |
X. X. Qian, Y. R. Wang, S. C. Gao, Y. K. Todo, S. C. Gao, Mr2DNM: A novel mutual information-based dendritic neuron model, Comput. Intell. Neurosci., 2019 (2019). https://doi.org/10.1155/2019/7362931 doi: 10.1155/2019/7362931
|
| [33] |
M. Dong, H. Wu, H. Hu, R. Azzam, L. Zhang, Z. Zheng, et al., Deformation prediction of unstable slopes based on real-time monitoring and DeepAR model, Sensors, 21 (2021). https://doi.org/10.3390/s21010014 doi: 10.3390/s21010014
|
| [34] |
R. B. Jin, Z. H. Chen, K. Y. Wu, M. Wu, X. L. Li, R. Q. Yan, Bi-LSTM-based two-stream network for machine remaining useful life prediction, IEEE Trans. Instrum. Meas., 71 (2022), 1–10. https://doi.org/10.1109/TIM.2022.3167778 doi: 10.1109/TIM.2022.3167778
|
| [35] |
Q. Li, J. H. Tan, J. Wang, H. C. Chen, A multimodal event-driven lstm model for stock prediction using online news, IEEE Trans. Knowl. Data Eng., 33 (2021), 3323–3337. https://doi.org/10.1109/TKDE.2020.2968894 doi: 10.1109/TKDE.2020.2968894
|
| [36] |
F. G. Liu, Z. W. Zhang, R. L. Zhou, Automatic modulation recognition based on CNN and GRU, Tsinghua Sci. Technol., 27 (2022), 422–431. https://doi.org/10.26599/TST.2020.9010057 doi: 10.26599/TST.2020.9010057
|
| [37] |
X. Lin, F. R. Bi, X. Yang, X. Y. Bi, An echo state network with improved topology for time series prediction, IEEE Sens. J., 22 (2022), 5869–5878. https://doi.org/10.1109/JSEN.2022.3148742 doi: 10.1109/JSEN.2022.3148742
|
| [38] |
X. S. Yao, Y. N. Shao, S. Y. Fan, S. X. Cao, Echo state network with multiple delayed outputs for multiple delayed time series prediction, J. Franklin Inst. 359 (2022), 11089–11107. https://doi.org/10.1016/j.jfranklin.2022.09.059 doi: 10.1016/j.jfranklin.2022.09.059
|
| [39] |
W. Chen, J. Sun, S. Gao, J. J. Cheng, J. Wang, Y. Todo, Using a single dendritic neuron to forecast tourist arrivals to Japan, IEICE Trans. Inf. Syst., E100.D (2017), 190–202. https://doi.org/10.1587/transinf.2016EDP7152 doi: 10.1587/transinf.2016EDP7152
|
| [40] |
D. B. Jia, C. H. Li, Q. Liu, Q. Yu, X. Meng, Z. Zhong, et al., Application and evolution for neural network and signal processing in large-scale systems, Complexity, 2021 (2021). https://doi.org/10.1155/2021/6618833 doi: 10.1155/2021/6618833
|
| [41] |
S. Gao, M. Zhou, Y. Wang, J. Cheng, H. Yachi, J. Wang, Dendritic neuron model with effective learning algorithms for classification, approximation, and prediction, IEEE Trans. Neural Networks Learn. Syst., 30 (2019), 601–614. https://doi.org/10.1109/TNNLS.2018.2846646 doi: 10.1109/TNNLS.2018.2846646
|
| [42] |
M. Chaloupka, Historical trends, seasonality and spatial synchrony in green sea turtle egg production, Biol. Conserv., 101 (2001), 263–279. https://doi.org/10.1016/S0006-3207(00)00199-3 doi: 10.1016/S0006-3207(00)00199-3
|
| [43] |
T. Zhou, S. Gao, J. Wang, C. Chu, Y. Todo, Z. Tang, Financial time series prediction using a dendritic neuron model, Knowledge-Based Syst., 105 (2016), 214–224. https://doi.org/10.1016/j.knosys.2016.05.031 doi: 10.1016/j.knosys.2016.05.031
|
| [44] |
H. T. He, S. C. Gao, T. Jin, S. Sato, X. Y. Zhang, A seasonal-trend decomposition-based dendritic neuron model for financial time series prediction, Appl. Soft Comput., 108 (2021), 107488. https://doi.org/10.1016/j.asoc.2021.107488 doi: 10.1016/j.asoc.2021.107488
|
| [45] |
Z. J. Sha, L. Hu, Y. Todo, J. Ji, S. Gao, Z. Tang, A breast cancer classifier using a neuron model with dendritic nonlinearity, IEICE Trans. Inf. Syst., E98.D (2015), 1365–1376. https://doi.org/10.1587/transinf.2014EDP7418 doi: 10.1587/transinf.2014EDP7418
|
| [46] |
H. Li, X. T. Liu, D. B. Jia, Y. Y. Chen, P. F. Hou, H. N. Li, Research on chest radiography recognition model based on deep learning, Math. Biosci. Eng., 19 (2022), 11768–11781. https://doi.org/10.3934/mbe.2022548 doi: 10.3934/mbe.2022548
|
| [47] | J. Demšar, Statistical comparisons of classifiers over multiple data sets, J. Mach. Learn. Res., 7 (2006), 1–30. |
| [48] |
Y. Cheng, W. N. Jia, R. H. Chi, A. Li, A clustering analysis method with high reliability based on Wilcoxon-Mann-Whitney testing, IEEE Access, 9 (2021), 19776–19787. https://doi.org/10.1109/ACCESS.2021.3053244 doi: 10.1109/ACCESS.2021.3053244
|









Figures(10) / Tables(11)
Dongbao Jia, Zhongxun Xu, Yichen Wang, Rui Ma, Wenzheng Jiang, Yalong Qian, Qianjin Wang, Weixiang Xu. Application of intelligent time series prediction method to dew point forecast[J]. Electronic Research Archive, 2023, 31(5): 2878-2899. doi: 10.3934/era.2023145







 DownLoad:
DownLoad: