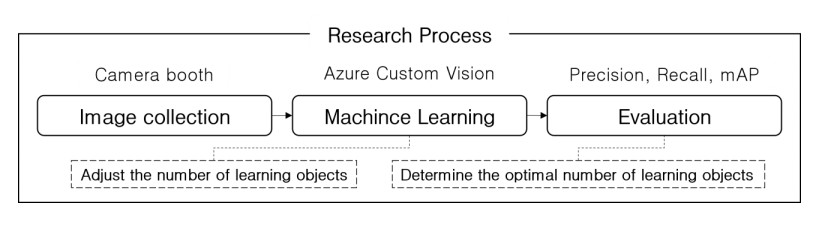
Oyster and scallop cultures have high growth rates in the Korean aquaculture industry. However, their production is declining because of the manual selection of polychaete-adherent oysters and scallops. In this study, an artificial intelligence model for automatic selection of polychaetes was developed using Microsoft Azure Custom Vision to improve the productivity of oysters and scallops. A camera booth was built to capture images of oysters and scallops from various angles. Polychaetes in the images were tagged. Transfer learning available with Custom Vision was performed on the acquired images. By repeating the training and evaluation, the number of training images was increased by analyzing the precision, recall, and mean average precision using the Compact [S1] and General [A1] domains of Custom Vision. This paper presents the artificial intelligence model developed for the automatic selection of polychaete-adherent oysters and scallops as well as the optimal model development method using Microsoft Azure Custom Vision.
Citation: Dong-hyeon Kim, Se-woon Choe, Sung-Uk Zhang. Recognition of adherent polychaetes on oysters and scallops using Microsoft Azure Custom Vision[J]. Electronic Research Archive, 2023, 31(3): 1691-1709. doi: 10.3934/era.2023088
Oyster and scallop cultures have high growth rates in the Korean aquaculture industry. However, their production is declining because of the manual selection of polychaete-adherent oysters and scallops. In this study, an artificial intelligence model for automatic selection of polychaetes was developed using Microsoft Azure Custom Vision to improve the productivity of oysters and scallops. A camera booth was built to capture images of oysters and scallops from various angles. Polychaetes in the images were tagged. Transfer learning available with Custom Vision was performed on the acquired images. By repeating the training and evaluation, the number of training images was increased by analyzing the precision, recall, and mean average precision using the Compact [S1] and General [A1] domains of Custom Vision. This paper presents the artificial intelligence model developed for the automatic selection of polychaete-adherent oysters and scallops as well as the optimal model development method using Microsoft Azure Custom Vision.

| [1] |
Y. H. Park, M. S. Do, S. W. Rho, Development direction of individual oyster aquaculture industry in Korea, J. Fish. Mar. Sci. Educ., 30 (2018), 913–922. https://doi.org/10.13000/JFMSE.2018.06.30.3.913 doi: 10.13000/JFMSE.2018.06.30.3.913

|
| [2] |
Y. D. Kim, C. Lee, G. S. Kim, M. Park, Y. C. Park, Y. S. Kim, et al., A study on argopecten irradians aquaculture in the north east sea regions, Korean J. Malacol., 32 (2016), 279–287. https://doi.org/10.9710/kjm.2016.32.4.279 doi: 10.9710/kjm.2016.32.4.279
|
| [3] |
H. Hong, X. Yang, Z. You, F. Cheng, Visual quality detection of aquatic products using machine vision, Aquac. Eng., 63 (2014), 62–71. https://doi.org/10.1016/j.aquaeng.2014.10.003 doi: 10.1016/j.aquaeng.2014.10.003
|
| [4] |
W. Sato-Okoshi, H. Abe, Morphological and molecular sequence analysis of the harmful shell boring species of polydora (Polychaeta: Spionidae) from Japan and Australia, Aquaculture, 368–369 (2012), 40–47. https://doi.org/10.1016/j.aquaculture.2012.08.046 doi: 10.1016/j.aquaculture.2012.08.046
|
| [5] |
W. Sato-Okoshi, K. Okoshi, B. S. Koh, Y. H. Kim, J. S. Hong, Polydorid species (Polychaeta: Spionidae) associated with commercially important mollusk shells in Korean waters, Aquaculture, 350–353 (2012), 82–90. https://doi.org/10.1016/j.aquaculture.2012.04.013 doi: 10.1016/j.aquaculture.2012.04.013
|
| [6] |
W. Sato-Okoshi, K. Okoshi, H. Abe, J. Y. Li, Polydorid species (Polychaeta, Spionidae) associated with commercially important mollusk shells from eastern China, Aquaculture, 406–407 (2013), 153–159 https://doi.org/10.1016/j.aquaculture.2013.05.017 doi: 10.1016/j.aquaculture.2013.05.017
|
| [7] |
A. L. T. Novaes, G. J. P. O. de Andrade, A. dos S. Alonço, A. R. M. Magalhães, Operational performance in aquaculture: A case study of the manual harvesting of cultivated mussels, Aquac. Eng., 84 (2019), 67–79. https://doi.org/10.1016/j.aquaeng.2018.12.006 doi: 10.1016/j.aquaeng.2018.12.006
|
| [8] |
Y. Pyeon, Y. Kim, D. Kim, W. Oh, I. Han, K. Lee, Development of an automatic assembly machine for oyster farm lines, J. Inst. Control. Robot. Syst., 24 (2018), 111–115. https://doi.org/10.5302/J.ICROS.2018.17.0219 doi: 10.5302/J.ICROS.2018.17.0219
|
| [9] |
C. A. Graham, H. Shamkhalichenar, V. E. Browning, V. J. Byrd, Y. Liu, M. T. Gutierrez-Wing, et al., A practical evaluation of machine learning for classification of ultrasound images of ovarian development in channel catfish (Ictalurus punctatus), Aquaculture, 552 (2022), 738039. https://doi.org/10.1016/j.aquaculture.2022.738039 doi: 10.1016/j.aquaculture.2022.738039
|
| [10] |
C. Costa, F. Antonucci, C. Boglione, P. Menesatti, M. Vandeputte, B. Chatain, Automated sorting for size, sex and skeletal anomalies of cultured seabass using external shape analysis, Aquac. Eng., 52 (2013), 58–64. https://doi.org/10.1016/J.AQUAENG.2012.09.001 doi: 10.1016/J.AQUAENG.2012.09.001
|
| [11] | A. Lapico, M. Sankupellay, L. Cianciullo, T. Myers, D. A. Konovalov, D. R. Jerry, et al., Using image processing to automatically measure pearl oyster size for selective breeding, in 2019 Digital Image Computing: Techniques and Applications (DICTA), 2019. https://doi.org/10.1109/DICTA47822.2019.8945902 |
| [12] |
S. Kakehi, T. Sekiuchi, H. Ito, S. Ueno, Y. Takeuchi, K. Suzuki, et al., Identification and counting of Pacific oyster Crassostrea gigas larvae by object detection using deep learning, Aquac. Eng., 95 (2021), 102197. https://doi.org/10.1016/J.AQUAENG.2021.102197 doi: 10.1016/J.AQUAENG.2021.102197
|
| [13] |
B. Zion, V. Alchanatis, V. Ostrovsky, A. Barki, I. Karplus, Classification of guppies' (Poecilia reticulata) gender by computer vision, Aquac. Eng., 38 (2008), 97–104. https://doi.org/10.1016/J.AQUAENG.2008.01.002 doi: 10.1016/J.AQUAENG.2008.01.002
|
| [14] |
M. Dowlati, M. de la Guardia, M. Dowlati, S. S. Mohtasebi, Application of machine-vision techniques to fish-quality assessment, TrAC Trends Analyt. Chem., 40 (2012), 168–179. https://doi.org/10.1016/J.TRAC.2012.07.011 doi: 10.1016/J.TRAC.2012.07.011
|
| [15] |
N. E. Little, O. H. Smith, F. W. Wheaton, M. A. Little, Automated oyster shucking: Part Ⅱ. Computer vision and control system for an automated oyster orienting device, Aquac. Eng., 37 (2007), 35–43. https://doi.org/10.1016/J.AQUAENG.2006.12.007 doi: 10.1016/J.AQUAENG.2006.12.007
|
| [16] |
D. Li, G. Wang, L. Du, Y. Zheng, Z. Wang, Recent advances in intelligent recognition methods for fish stress behavior, Aquac. Eng., 96 (2022), 102222. https://doi.org/10.1016/J.AQUAENG.2021.102222 doi: 10.1016/J.AQUAENG.2021.102222
|
| [17] |
Z. Liu, X. Li, L. Fan, H. Lu, L. Liu, Y. Liu, Measuring feeding activity of fish in RAS using computer vision, Aquac. Eng., 60 (2014) 20–27. https://doi.org/10.1016/J.AQUAENG.2014.03.005 doi: 10.1016/J.AQUAENG.2014.03.005
|
| [18] |
H. M. Lalabadi, M. Sadeghi, S. A. Mireei, Fish freshness categorization from eyes and gills color features using multi-class artificial neural network and support vector machines, Aquac. Eng., 90 (2020), 102076. https://doi.org/10.1016/J.AQUAENG.2020.102076 doi: 10.1016/J.AQUAENG.2020.102076
|
| [19] |
G. Xiong, D. J. Lee, K. R. Moon, R. M. Lane, Shape similarity measure using turn angle cross-correlation for oyster quality evaluation, J. Food Eng., 100 (2010), 178–186. https://doi.org/10.1016/J.JFOODENG.2010.03.043 doi: 10.1016/J.JFOODENG.2010.03.043
|
| [20] |
A. Banan, A. Nasiri, A. Taheri-Garavand, Deep learning-based appearance features extraction for automated carp species identification, Aquac. Eng., 89 (2020), 102053. https://doi.org/10.1016/J.AQUAENG.2020.102053 doi: 10.1016/J.AQUAENG.2020.102053
|
| [21] |
S. S. Chen, F. W. Wheaton, Oyster hinge line detection using image processing, Aquac. Eng., 8 (1989), 307–327. https://doi.org/10.1016/0144-8609(89)90038-1 doi: 10.1016/0144-8609(89)90038-1
|
| [22] |
C. S. Costa, V. A. G. Zanoni, L. R. V. Curvo, M. de Araújo Carvalho, W. R. Boscolo, A. Signor, et al., Deep learning applied in fish reproduction for counting larvae in images captured by smartphone, Aquac. Eng., 97 (2022), 102225. https://doi.org/10.1016/J.AQUAENG.2022.102225 doi: 10.1016/J.AQUAENG.2022.102225
|
| [23] | C. Yang, C. Liu, C. Tan, F. Sun, T. Kong, W. Zhang, A survey on deep transfer learning, in International Conference on Artificial Neural Networks, 2018. https://doi.org/10.1007/978-3-030-01424-7_27 |
| [24] | M. Pejčinović, A review of custom vision service for facilitating an image classification, in Proceedings of the Central European Conference on Information and Intelligent Systems, (2019), 1-13. Available from: https://www.proquest.com/openview/c1b73d7326a4d300905497cf6972c227/1?pq-origsite=gscholar&cbl=1986354. |















Figures(16) / Tables(4)
Dong-hyeon Kim, Se-woon Choe, Sung-Uk Zhang. Recognition of adherent polychaetes on oysters and scallops using Microsoft Azure Custom Vision[J]. Electronic Research Archive, 2023, 31(3): 1691-1709. doi: 10.3934/era.2023088







 DownLoad:
DownLoad: