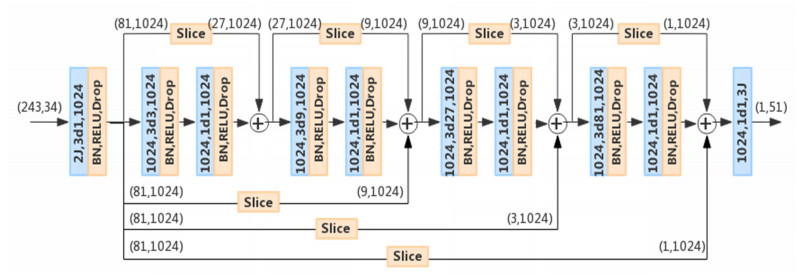
3D human pose estimation is a hot topic in the field of computer vision. It provides data support for tasks such as pose recognition, human tracking and action recognition. Therefore, it is widely applied in the fields of advanced human-computer interaction, intelligent monitoring and so on. Estimating 3D human pose from a single 2D image is an ill-posed problem and is likely to cause low prediction accuracy, due to the problems of self-occlusion and depth ambiguity. This paper developed two types of human kinematics to improve the estimation accuracy. First, taking the 2D human body skeleton sequence obtained by the 2D human body pose detector as input, a temporal convolutional network is proposed to develop the movement periodicity in temporal domain. Second, geometrical prior knowledge is introduced into the model to constrain the estimated pose to fit the general kinematics knowledge. The experiments are tested on Human3.6M and MPII (Max Planck Institut Informatik) Human Pose (MPI-INF-3DHP) datasets, and the proposed model shows better generalization ability compared with the baseline and the state-of-the-art models.
Citation: Longkui Jiang, Yuru Wang, Weijia Li. Regress 3D human pose from 2D skeleton with kinematics knowledge[J]. Electronic Research Archive, 2023, 31(3): 1485-1497. doi: 10.3934/era.2023075
3D human pose estimation is a hot topic in the field of computer vision. It provides data support for tasks such as pose recognition, human tracking and action recognition. Therefore, it is widely applied in the fields of advanced human-computer interaction, intelligent monitoring and so on. Estimating 3D human pose from a single 2D image is an ill-posed problem and is likely to cause low prediction accuracy, due to the problems of self-occlusion and depth ambiguity. This paper developed two types of human kinematics to improve the estimation accuracy. First, taking the 2D human body skeleton sequence obtained by the 2D human body pose detector as input, a temporal convolutional network is proposed to develop the movement periodicity in temporal domain. Second, geometrical prior knowledge is introduced into the model to constrain the estimated pose to fit the general kinematics knowledge. The experiments are tested on Human3.6M and MPII (Max Planck Institut Informatik) Human Pose (MPI-INF-3DHP) datasets, and the proposed model shows better generalization ability compared with the baseline and the state-of-the-art models.

| [1] |
A. Agarwal, B. Triggs, Recovering 3D human pose from monocular images, IEEE Trans. Pattern Anal. Mach. Intell., 28 (2006), 44–58. https://doi.org/10.1109/tpami.2006.21 doi: 10.1109/tpami.2006.21

|
| [2] |
J. Cho, M. Lee, S. Oh, Single image 3D human pose estimation using a procrustean normal distribution mixture model and model transformation, Comput. Vis. Image Und., 155 (2017), 150–161. https://doi.org/10.1016/j.cviu.2016.11.002 doi: 10.1016/j.cviu.2016.11.002
|
| [3] | T. Alldieck, M. Kassubeck, B. Wandt, B. Rosenhahn, M. Magnor, Optical flow-based 3D human motion estimation from monocular video, in German Conference on Pattern Recognition, 10496 (2017), 347–360. https://doi.org/10.1007/978-3-319-66709-6_28 |
| [4] | X. Zhou, M. Zhu, S. Leonardos, K. Derpanis, K. Daniilidis, Sparseness meets deepness: 3D human pose estimation from monocular video. in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 4966–4975. https://doi.org/10.1109/CVPR.2016.537 |
| [5] | A. Shafaei, J. J. Little, Real-time human motion capture with multiple depth cameras, in 2016 13th Conference on Computer and Robot Vision (CRV), (2016), 24–31. https://doi.org/10.1109/CRV.2016.25 |
| [6] |
D. Michel, C. Panagiotakis, A. A. Argyros, Tracking the articulated motion of the human body with two RGBD cameras, Mach. Vision Appl., 26 (2015), 41–54. https://doi.org/10.1007/s00138-014-0651-0 doi: 10.1007/s00138-014-0651-0
|
| [7] | Y. Zhu, K. Fujimura, Bayesian 3D human body pose tracking from depth image sequences, in Asian Conference on Computer Vision, 5995 (2009), 267–278. https://doi.org/10.1007/978-3-642-12304-7_26 |
| [8] | X. Zheng, M. Fu, Y. Yang, N. Lv, 3D Human poses recognition using Kinect, in 2012 4th International Conference on Intelligent Human-Machine Systems and Cybernetics, (2012), 344–347. https://doi.org/10.1109/IHMSC.2012.92 |
| [9] | Y. Guo, Z. Li, Z. Li, X. Du, S. Quan, Yi Xu, PoP-Net: Pose over parts network for multi-person 3D pose estimation from a depth image, in 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), (2022), 3917–3926. https://doi.org/10.1109/WACV51458.2022.00397 |
| [10] | X. Zhou, Q. Huang, X. Sun, X. Xue, Y. Wei, Towards 3D human pose estimation in the wild: A weakly-supervised approach, in 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 398–407. https://doi.org/10.1109/ICCV.2017.51 |
| [11] | W. Yang, W. Ouyang, Xi. Wang, J. Ren, H. Li, X. Wang, 3D human pose estimation in the wild by adversarial learning, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 5255–5264. https://doi.org/10.1109/CVPR.2018.00551 |
| [12] | J. N. Kundu, S. Seth, P. Ym, V. Jampani, A. Chakraborty, R. V. Babu, Uncertainty-aware adaptation for self-supervised 3D human pose estimation, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2022), 20416–20427. https://doi.org/10.1109/CVPR52688.2022.01980 |
| [13] | C. Zheng, S. Zhu, M. Mendieta, T. Yang, C. Chen, Z. Ding, 3D human pose estimation with spatial and temporal transformers. in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 11636–11645. https://doi.org/10.1109/ICCV48922.2021.01145 |
| [14] | K. Liu, R. Ding, Z. Zou, L. Wang, W. Tang, A comprehensive study of weight sharing in graph networks for 3D human pose estimation, in European Conference on Computer Vision, (2020), 318–334. https://doi.org/10.1007/978-3-030-58607-2_19 |
| [15] | T. Xu, W. Takano, Graph stacked hourglass networks for 3D human pose estimation, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 16100–16109. https://doi.org/10.1109/CVPR46437.2021.01584 |
| [16] | J. Zhang, Z. Tu, J. Yang, Y. Chen, J. Yuan, MixSTE: Seq2seq mixed spatio-temporal encoder for 3D human pose estimation in video, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2022), 13222–13232. https://doi.org/10.1109/CVPR52688.2022.01288 |
| [17] | L. Pishchulin, M. Andriluka, P. Gehler, B. Schiele, Strong appearance and expressive spatial models for human pose estimation, in 2013 IEEE International Conference on Computer Vision, (2013), 3487–349. https://doi.org/10.1109/ICCV.2013.433 |
| [18] | B. Sapp, B. Taskar, Modec: Multimodal decomposable models for human pose estimation, in 2013 IEEE Conference on Computer Vision and Pattern Recognition, (2013), 3674–3681. https://doi.org/10.1109/CVPR.2013.471 |
| [19] | M. Andriluka, L. Pishchulin, P. Gehler, B. Schiele, 2D human pose estimation: new benchmark and state of the art analysis, in 2014 IEEE Conference on Computer Vision and Pattern Recognition, (2014), 3686–3693. https://doi.org/10.1109/CVPR.2014.471 |
| [20] | T. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, et al., Microsoft COCO: Common objects in context, in European Conference on Computer Vision, (2014), 740–755. https://doi.org/10.1007/978-3-319-10602-1_48 |
| [21] |
L. Sigal, A. O. Balan, M. J. Black, HumanEva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion, Int. J. Comput. Vision, 87 (2010). https://doi.org/10.1007/s11263-009-0273-6 doi: 10.1007/s11263-009-0273-6
|
| [22] |
Ionescu C., D. Papava, V. Olaru, C. Sminchisescu, Human3.6M: Large scale datasets and predictive methods for 3D human sensing in natural environments, IEEE Trans. Pattern Anal. Mach. Intell., 36 (2014), 1325–1339. https://doi.org/10.1109/TPAMI.2013.248 doi: 10.1109/TPAMI.2013.248
|
| [23] | M. Gholami, B. Wandt, H. Rhodin, R. Ward, Z. J. Wang, AdaptPose: Cross-dataset adaptation for 3D human pose estimation by learnable motion generation, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2022), 13065–13075. https://doi.org/10.1109/CVPR52688.2022.01273 |
| [24] | J. Martinez, R. Hossain, J. Romero, J. J. Little, A simple yet effective baseline for 3D human pose estimation, in 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 2659–2668. https://doi.org/10.1109/ICCV.2017.288 |
| [25] | H. Fang, Y. Xu, W. Wang, X. Liu, S. Zhu, Learning pose grammar to encode human body configuration for 3D human pose estimation, in Proceedings of the AAAI Conference on Artificial Intelligence, 32 (2018), 6821–6828. https://doi.org/10.1609/aaai.v32i1.12270 |
| [26] | M. R. I. Hossain, J. J. Little, Exploiting temporal information for 3D pose estimation, in European Conference on Computer Vision, 11214 (2018), 69–86. https://doi.org/10.1007/978-3-030-01249-6_5 |
| [27] | A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, et al., WaveNet: A generative model for raw audio, preprint, arXiv: 1609.03499. |
| [28] | D. Pavllo, C. Feichtenhofer, D. Grangier, M. Auli, 3D human pose estimation in video with temporal convolutions and semi-supervised training, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 7745–7754. https://doi.org/10.1109/CVPR.2019.00794 |
| [29] | R. Dabral, A. Mundhada, U. Kusupati, S. Afaque, A. Sharma, A. Jain, Learning 3D human pose from structure and motion, in European Conference on Computer Vision, (2018), 679–696. https://doi.org/10.1007/978-3-030-01240-3_41 |
| [30] | Y. Cai, L. Ge, J. Liu, J. Cai, T. Cham, J. Yuan, et al., Exploiting spatial-temporal relationships for 3D pose estimation via graph convolutional networks, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 2272–2281. https://doi.org/10.1109/ICCV.2019.00236 |
| [31] | Z. Li, X. Wang, F. Wang, P. Jiang, On boosting single-frame 3D human pose estimation via monocular videos, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 2192–2201. https://doi.org/10.1109/ICCV.2019.00228 |
| [32] | Z. Cui, T. Song, Y. Wang, Q. Ji, Knowledge augmented deep neural networks for joint facial expression and action unit recognition, in Proceedings of the 34th International Conference on Neural Information Processing Systems, (2020), 14338–14349. |
| [33] |
Q. Chen, B. Zhong, Q. Liang, Q. Deng, X. Li, Teacher-student knowledge distillation for real-time correlation tracking, Neurocomputing, 500 (2022), 537–546. https://doi.org/10.1016/j.neucom.2022.05.064 doi: 10.1016/j.neucom.2022.05.064
|
| [34] | X. Sun, X. Zhang, L. Cao, Y. Wu, F. Huang, R. Ji, Exploring language prior for mode-sensitive visual attention modeling, in Proceedings of the 28th ACM International Conference on Multimedia, (2020), 4199–4207, https://doi.org/10.1145/3394171.3414008 |
| [35] |
V. Belagiannis, S. Amin, M. Andriluka, B. Schiele, N. Navab, S. Ilic, 3D pictorial structures revisited: Multiple human pose estimation, IEEE Trans. Pattern Anal. Mach. Intell., 38 (2016). https://doi.org/10.1109/TPAMI.2015.2509986 doi: 10.1109/TPAMI.2015.2509986
|
| [36] | M. R. Ronchi, O. M. Aodha, R. Eng, P. Perona, It's all relative: Monocular 3D human pose estimation from weakly supervised data, preprint, arXiv: 1805.06880. |
| [37] | D. Mehta, H. Rhodin, D. Casas, P. Fua, O. Sotnychenko, W. Xu, et al., Monocular 3D human pose estimation in the wild using improved CNN supervision, in 2017 International Conference on 3D Vision (3DV), (2017), 506–516. https://doi.org/10.1109/3DV.2017.00064 |
| [38] | Y. Chen, Z. Wang, Y. Peng, Z. Zhang, G. Yu, J. Sun, Cascaded pyramid network for multi-person pose estimation. in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 7103–7112. https://doi.org/10.1109/CVPR.2018.00742 |
| [39] | X. Sun, J. Shang, S. Liang, Y. Wei, Compositional human pose regression, in 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 2621–2630. https://doi.org/10.1109/ICCV.2017.284 |
| [40] | G. Pavlakos, X. Zhou, K. Daniilidis, Ordinal depth supervision for 3D human pose estimation, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 7307–7316. https://doi.org/10.1109/CVPR.2018.00763 |
| [41] | W. Yang, W. Ouyang, X. Wang, J. Ren, H. Li, X. Wang, 3D human pose estimation in the wild by adversarial learning, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 5255–5264. https://doi.org/10.1109/CVPR.2018.00551 |
| [42] | D. C. Luvizon, D. Picard, H. Tabia, 2D/3D pose estimation and action recognition using multitask deep learning, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 5137–5146. https://doi.org/10.1109/CVPR.2018.00539 |
| [43] | K. Lee, I. Lee, S. Lee, Propagating lstm: 3D pose estimation based on joint interdependency, in European Conference on Computer Vision, 11211 (2018), 119–135. https://doi.org/10.1007/978-3-030-01234-2_8 |
| [44] | K. Zhou, X. Han, N. Jiang, K. Jia, J. Lu, Hemlets pose: Learning part-centric heatmap triplets for accurate 3d human pose estimation. in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, 2344–2353. |

Figures(2) / Tables(6)
Longkui Jiang, Yuru Wang, Weijia Li. Regress 3D human pose from 2D skeleton with kinematics knowledge[J]. Electronic Research Archive, 2023, 31(3): 1485-1497. doi: 10.3934/era.2023075







 DownLoad:
DownLoad: