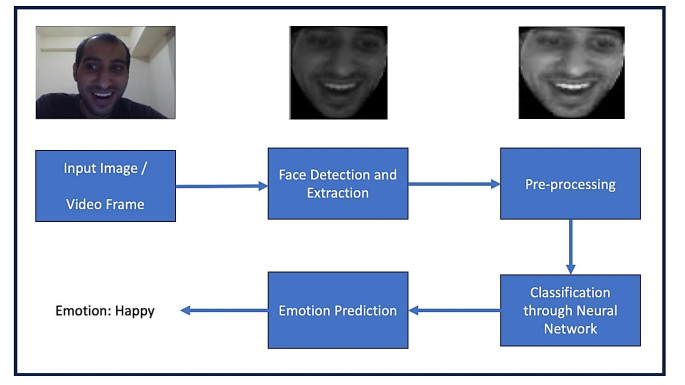
Computer vision is witnessing a surge of interest in machines accurately recognizing and interpreting human emotions through facial expression analysis. However, variations in image properties such as brightness, contrast, and resolution make it harder for models to predict the underlying emotion accurately. Utilizing a robust architecture of a convolutional neural network (CNN), we designed an efficacious framework for facial emotion recognition that predicts emotions and assigns corresponding probabilities to each fundamental human emotion. Each image is processed with various pre-processing steps before inputting it to the CNN to enhance the visibility and clarity of facial features, enabling the CNN to learn more effectively from the data. As CNNs entail a large amount of data for training, we used a data augmentation technique that helps to enhance the model's generalization capabilities, enabling it to effectively handle previously unseen data. To train the model, we joined the datasets, namely JAFFE and KDEF. We allocated 90% of the data for training, reserving the remaining 10% for testing purposes. The results of the CCN framework demonstrated a peak accuracy of 78.1%, which was achieved with the joint dataset. This accuracy indicated the model's capability to recognize facial emotions with a promising level of performance. Additionally, we developed an application with a graphical user interface for real-time facial emotion classification. This application allows users to classify emotions from still images and live video feeds, making it practical and user-friendly. The real-time application further demonstrates the system's practicality and potential for various real-world applications involving facial emotion analysis.
Citation: Imad Ali, Faisal Ghaffar. Robust CNN for facial emotion recognition and real-time GUI[J]. AIMS Electronics and Electrical Engineering, 2024, 8(2): 227-246. doi: 10.3934/electreng.2024010
Computer vision is witnessing a surge of interest in machines accurately recognizing and interpreting human emotions through facial expression analysis. However, variations in image properties such as brightness, contrast, and resolution make it harder for models to predict the underlying emotion accurately. Utilizing a robust architecture of a convolutional neural network (CNN), we designed an efficacious framework for facial emotion recognition that predicts emotions and assigns corresponding probabilities to each fundamental human emotion. Each image is processed with various pre-processing steps before inputting it to the CNN to enhance the visibility and clarity of facial features, enabling the CNN to learn more effectively from the data. As CNNs entail a large amount of data for training, we used a data augmentation technique that helps to enhance the model's generalization capabilities, enabling it to effectively handle previously unseen data. To train the model, we joined the datasets, namely JAFFE and KDEF. We allocated 90% of the data for training, reserving the remaining 10% for testing purposes. The results of the CCN framework demonstrated a peak accuracy of 78.1%, which was achieved with the joint dataset. This accuracy indicated the model's capability to recognize facial emotions with a promising level of performance. Additionally, we developed an application with a graphical user interface for real-time facial emotion classification. This application allows users to classify emotions from still images and live video feeds, making it practical and user-friendly. The real-time application further demonstrates the system's practicality and potential for various real-world applications involving facial emotion analysis.

| [1] |
Albornoz EM, Milone DH, Rufiner HL (2011) Spoken emotion recognition using hierarchical classifiers. Comput Speech Lang 25: 556‒570. https://doi.org/10.1016/j.csl.2010.10.001 doi: 10.1016/j.csl.2010.10.001

|
| [2] |
Erol BA, Majumdar A, Benavidez P, Rad P, Choo KKR, Jamshidi M (2019) Toward artificial emotional intelligence for cooperative social human-machine interaction. IEEE Transactions on Computational Social Systems 7: 234‒246. https://doi.org/10.1109/tcss.2019.2922593 doi: 10.1109/tcss.2019.2922593
|
| [3] |
Cohn JF, Ambadar Z, Ekman P (2007) Observer-based measurement of facial expression with the Facial Action Coding System. The Handbook of Emotion Elicitation and Assessment 1: 203‒221. https://doi.org/10.1093/oso/9780195169157.003.0014 doi: 10.1093/oso/9780195169157.003.0014
|
| [4] |
Vaillant R, Monrocq C, Le Cun Y (1994) Original approach for the localization of objects in images. IEE Proceedings-Vision, Image and Signal Processing 141: 245‒250. https://doi.org/10.1049/ip-vis:19941301 doi: 10.1049/ip-vis:19941301
|
| [5] |
Rowley HA, Baluja S, Kanade T (1998) Neural network-based face detection. IEEE T Pattern Anal 20: 23‒38. https://doi.org/10.1109/34.655647 doi: 10.1109/34.655647
|
| [6] | Jain V, Learned-Miller E (2010) FDDB: A benchmark for face detection in unconstrained settings. Technical Report UMCS-2010-009, University of Massachusetts, Amherst. Available from: https://people.cs.umass.edu/~elm/papers/fddb.pdf |
| [7] |
Zhu X, Ramanan D (2012) Face detection, pose estimation, and landmark localization in the wild. IEEE Conference on Computer Vision and Pattern Recognition, 2879‒2886. https://doi.org/10.1109/cvpr.2012.6248014 doi: 10.1109/cvpr.2012.6248014
|
| [8] |
Yan J, Zhang X, Lei Z, Li SZ (2014) Face detection by structural models. Image Vision Comput 32: 790‒799. https://doi.org/10.1109/fg.2013.6553703 doi: 10.1109/fg.2013.6553703
|
| [9] |
Viola P, Jones M (2001) Rapid object detection using a boosted cascade of simple features. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 1‒9. https://doi.org/10.1109/cvpr.2001.990517 doi: 10.1109/cvpr.2001.990517
|
| [10] |
Lienhart R, Maydt J (2002) An extended set of Haar-like features for rapid object detection. Proceedings of the IEEE International Conference on Image Processing, 1‒4. https://doi.org/10.1109/icip.2002.1038171 doi: 10.1109/icip.2002.1038171
|
| [11] |
Belhumeur PN, Hespanha JP, Kriegman DJ (1997) Eigenfaces vs. Fisherfaces: Recognition using class-specific linear projection. IEEE T Pattern Anal 19: 711‒720. https://doi.org/10.1109/34.598228 doi: 10.1109/34.598228
|
| [12] |
Yang MH, Kriegman DJ, Ahuja N (2002) Detecting faces in images: A survey. IEEE T Pattern Anal 24: 34‒58. https://doi.org/10.1109/34.982883 doi: 10.1109/34.982883
|
| [13] |
Wu J, Zhang C, Xue T, Freeman B, Tenenbaum J (2016) Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. Advances in Neural Information Processing Systems, 82‒90. https://doi.org/10.1609/aaai.v32i1.12223 doi: 10.1609/aaai.v32i1.12223
|
| [14] |
Sroubek F, Milanfar P (2011) Robust multichannel blind deconvolution via fast alternating minimization. IEEE T Image Process 21: 1687‒1700. https://doi.org/10.1109/tip.2011.2175740 doi: 10.1109/tip.2011.2175740
|
| [15] |
Krizhevsky A, Sutskever I, Hinton GE (2012) ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 1097‒1105. https://doi.org/10.1145/3065386 doi: 10.1145/3065386
|
| [16] | Sermanet P, Eigen D, Zhang X, Mathieu M, Fergus R, LeCun Y (2013) Overfeat: Integrated recognition, localization, and detection using convolutional networks. arXiv preprint arXiv: 1312.6229. https://doi.org/10.48550/arXiv.1312.6229 |
| [17] |
Bartlett MS, Littlewort G, Frank M, Lainscsek C, Fasel I, Movellan J (2006) Fully automatic facial action recognition in spontaneous behavior. 7th International IEEE Conference on Automatic Face and Gesture Recognition, 223‒230. https://doi.org/10.1109/fgr.2006.55 doi: 10.1109/fgr.2006.55
|
| [18] |
Pantic M, Rothkrantz LJ (2004) Facial action recognition for facial expression analysis from static face images. IEEE T Syst Man Cy B 34: 1449‒1461. https://doi.org/10.1109/tsmcb.2004.825931 doi: 10.1109/tsmcb.2004.825931
|
| [19] |
Tian YI, Kanade T, Cohn JF (2001) Recognizing action units for facial expression analysis. IEEE T Pattern Anal 23: 97‒115. https://doi.org/10.1109/cvpr.2000.855832 doi: 10.1109/cvpr.2000.855832
|
| [20] |
Ng HW, Nguyen VD, Vonikakis V, Winkler S (2015) Deep learning for emotion recognition on small datasets using transfer learning. Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, 443‒449. https://doi.org/10.1145/2818346.2830593 doi: 10.1145/2818346.2830593
|
| [21] |
Chaudhari A, Bhatt C, Krishna A, Travieso-González CM (2023) Facial emotion recognition with inter-modality-attention-transformer-based self-supervised learning. Electronics 12: 1‒15. https://doi.org/10.3390/electronics12020288 doi: 10.3390/electronics12020288
|
| [22] |
Yang D, Huang S, Wang S, Liu Y, Zhai P, Su L, et al. (2022) Emotion recognition for multiple context awareness. Proceedings of the European Conference on Computer Vision, 144‒162. https://doi.org/10.1007/978-3-031-19836-6_9 doi: 10.1007/978-3-031-19836-6_9
|
| [23] |
Song C, Ji S (2022) Face Recognition Method Based on Siamese Networks Under Non-Restricted Conditions. IEEE Access 10: 40432‒40444. https://doi.org/10.1109/access.2022.3167143 doi: 10.1109/access.2022.3167143
|
| [24] |
Qu X, Zou Z, Su X, Zhou P, Wei W, Wen S, et al. (2021) Attend to where and when: Cascaded attention network for facial expression recognition. IEEE Transactions on Emerging Topics in Computational Intelligence 6: 580‒592. https://doi.org/10.1109/tetci.2021.3070713 doi: 10.1109/tetci.2021.3070713
|
| [25] |
King DE (2009) Dlib-ml: A machine learning toolkit. The Journal of Machine Learning Research 10: 1755‒1758. https://doi.org/10.1145/1577069.1755843 doi: 10.1145/1577069.1755843
|
| [26] | Lyons MJ, Kamachi M, Gyoba J (1997) Japanese female facial expressions (JAFFE). Database of Digital Images. https://doi.org/10.5281/zenodo.3451524 |
| [27] |
Goeleven E, De Raedt R, Leyman L, Verschuere B (2008) The Karolinska directed emotional faces: a validation study. Cognition and Emotion 22: 1094‒1118. https://doi.org/10.1080/02699930701626582 doi: 10.1080/02699930701626582
|











Figures(12) / Tables(1)

Imad Ali, Faisal Ghaffar. Robust CNN for facial emotion recognition and real-time GUI[J]. AIMS Electronics and Electrical Engineering, 2024, 8(2): 227-246. doi: 10.3934/electreng.2024010







 DownLoad:
DownLoad: