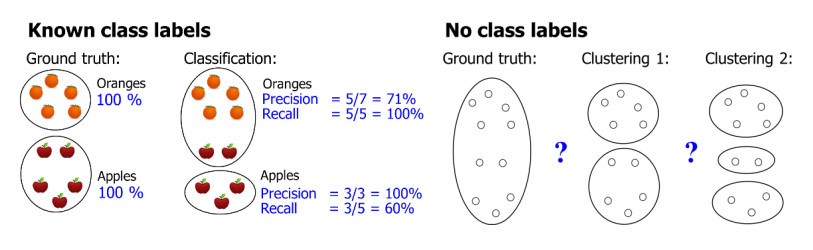
Clustering accuracy (ACC) is one of the most often used measures in literature to evaluate clustering quality. However, the measure is often used without any definition or reference to such a definition. In this paper, we identify the origin of the measure. We give a proper definition for the measure and provide a simple bug fix which allows it to be used also in the case of a mismatch in the number of clusters. We show that the measure belongs to a wider class of set-matching based measures. We compare its properties to centroid index (CI) and normalized mutual information (NMI).
Citation: Pasi Fränti, Sami Sieranoja. Clustering accuracy[J]. Applied Computing and Intelligence, 2024, 4(1): 24-44. doi: 10.3934/aci.2024003
Clustering accuracy (ACC) is one of the most often used measures in literature to evaluate clustering quality. However, the measure is often used without any definition or reference to such a definition. In this paper, we identify the origin of the measure. We give a proper definition for the measure and provide a simple bug fix which allows it to be used also in the case of a mismatch in the number of clusters. We show that the measure belongs to a wider class of set-matching based measures. We compare its properties to centroid index (CI) and normalized mutual information (NMI).

| [1] | S. van Dongen, Performance criteria for graph clustering and Markov cluster experiments, Amsterdam: Centrum voor Wiskunde en Informatica, 2000. |
| [2] |
M. Meila, D. Heckerman, An experimental comparison of model based clustering methods, Mach. Learn., 41 (2001), 9–29. https://doi.org/10.1023/A:1007648401407 doi: 10.1023/A:1007648401407

|
| [3] |
M. Rezaei, P. Fränti, Set matching measures for external cluster validity, IEEE Trans. Knowl. Data Eng., 28 (2016), 2173–2186. https://doi.org/10.1109/TKDE.2016.2551240 doi: 10.1109/TKDE.2016.2551240
|
| [4] |
P. Fränti, Genetic algorithm with deterministic crossover for vector quantization, Pattern Recogn. Lett., 21 (2000), 61–68. https://doi.org/10.1016/S0167-8655(99)00133-6 doi: 10.1016/S0167-8655(99)00133-6
|
| [5] |
P. Fränti, Efficiency of random swap clustering, J. Big Data, 5 (2018), 13. https://doi.org/10.1186/s40537-018-0122-y doi: 10.1186/s40537-018-0122-y
|
| [6] | B. Fritzke, Breathing k-means, arXiv: 2006.15666. |
| [7] |
C. Baldassi, Recombinator-k-means: an evolutionary algorithm that exploits k-means++ for recombination, IEEE Trans. Evolut. Comput., 20 (2022), 991–1003. https://doi.org/10.1109/TEVC.2022.3144134 doi: 10.1109/TEVC.2022.3144134
|
| [8] |
P. Rousseeuw, Silhouettes: a graphical aid to the interpretation and validation of cluster analysis, J. Comput. Appl. Math., 20 (1987), 53–65. https://doi.org/10.1016/0377-0427(87)90125-7 doi: 10.1016/0377-0427(87)90125-7
|
| [9] |
T. Calinski, J. Harabasz, A dendrite method for cluster analysis, Commun. Stat., 3 (1974), 1–27. https://doi.org/10.1080/03610927408827101 doi: 10.1080/03610927408827101
|
| [10] |
Q. Zhao, P. Fränti, WB-index: a sum-of-squares based index for cluster validity, Data Knowl. Eng., 92 (2014), 77–89. https://doi.org/10.1016/j.datak.2014.07.008 doi: 10.1016/j.datak.2014.07.008
|
| [11] |
J. Hämäläinen, S. Jauhiainen, T. Kärkkäinen, Comparison of internal clustering validation indices for prototype-based clustering, Algorithms, 10 (2017), 105. https://doi.org/10.3390/a10030105 doi: 10.3390/a10030105
|
| [12] |
M. Niemelä, S. Äyrämö, T. Kärkkäinen, Toolbox for distance estimation and cluster validation on data with missing values, IEEE Access, 10 (2021), 352–367. https://doi.org/10.1109/ACCESS.2021.3136435 doi: 10.1109/ACCESS.2021.3136435
|
| [13] |
L. Hubert, P. Arabie, Comparing partitions, J. Classif., 2 (1985), 193–218. https://doi.org/10.1007/BF01908075 doi: 10.1007/BF01908075
|
| [14] |
T. Kvålseth, Entropy and correlation: some comments, IEEE Trans. Syst. Man Cybern., 17 (1987), 517–519. https://doi.org/10.1109/TSMC.1987.4309069 doi: 10.1109/TSMC.1987.4309069
|
| [15] |
T. Kinnunen, I. Sidoroff, M. Tuononen, P. Fränti, Comparison of clustering methods: a case study of text-independent speaker modeling, Pattern Recogn. Lett., 32 (2011), 1604–1617. https://doi.org/10.1016/j.patrec.2011.06.023 doi: 10.1016/j.patrec.2011.06.023
|
| [16] |
C. Peng, Z. Kang, Q. Cheng, Integrating feature and graph learning with low-rank representation, Neurocomputing, 249 (2017), 106–116. https://doi.org/10.1016/j.neucom.2017.03.071 doi: 10.1016/j.neucom.2017.03.071
|
| [17] | M. Wu, B. Schölkopf, A local learning approach for clustering, In: Advances in neural information processing systems 19, Cambridge: MIT Press, 2007, 1529–1536. |
| [18] | L. Lovasz, M. D. Plummer, Matching theory, North Holland: Akademiai Kiado, 1986. |
| [19] |
H. W. Kuhn, The Hungarian method for the assignment problem, Naval Research Logistics Quarterly, 2 (1955), 83–97. https://doi.org/10.1002/nav.3800020109 doi: 10.1002/nav.3800020109
|
| [20] |
J. Munkres, Algorithms for the assignment and transportation problems, J. Soc. Ind. Appl. Math., 5 (1957), 32–38. https://doi.org/10.1137/0105003 doi: 10.1137/0105003
|
| [21] |
X. Liu, M. Li, C. Tang, J. Xia, J. Xiong, L. Liu, et al., Efficient and effective regularized incomplete multi-view clustering, IEEE Trans. Pattern Anal., 43 (2021), 2634–2646. https://doi.org/10.1109/TPAMI.2020.2974828 doi: 10.1109/TPAMI.2020.2974828
|
| [22] |
M. Alshammari, J. Stavrakakis, M. Takatsuka, Refining a k-nearest neighbor graph for a computationally efficient spectral clustering, Pattern Recogn., 114 (2021), 107869. https://doi.org/10.1016/j.patcog.2021.107869 doi: 10.1016/j.patcog.2021.107869
|
| [23] |
J. Ma, Y. Zhang, L. Zhang, Discriminative subspace matrix factorization for multiview data clustering, Pattern Recogn., 111 (2021), 107676. https://doi.org/10.1016/j.patcog.2020.107676 doi: 10.1016/j.patcog.2020.107676
|
| [24] |
J. Liu, S. Teng, L. Fei, W. Zhang, X. Fang, Z. Zhang, et al., A novel consensus learning approach to incomplete multi-view clustering, Pattern Recogn., 115 (2021), 107890. https://doi.org/10.1016/j.patcog.2021.107890 doi: 10.1016/j.patcog.2021.107890
|
| [25] |
X. Yang, J. Shi, C. Wang, Y. Zhou, Z. Zhou, T. Chen, et al., Binary clustering for deep network trained by feature growth, IEEE Access, 9 (2021), 8354–8366. https://doi.org/10.1109/ACCESS.2020.3047467 doi: 10.1109/ACCESS.2020.3047467
|
| [26] |
Y. Xu, S. Chen, J. Li, L. Luo, J. Yang, Learnable low-rank latent dictionary for subspace clustering, Pattern Recogn., 120 (2021), 108142. https://doi.org/10.1016/j.patcog.2021.108142 doi: 10.1016/j.patcog.2021.108142
|
| [27] |
Y. Chen, L. Zhou, N. Bouguila, C. Wang, Y. Chen, J. Du, BLOCK-DBSCAN: fast clustering for large scale data, Pattern Recogn., 109 (2021), 107624. https://doi.org/10.1016/j.patcog.2020.107624 doi: 10.1016/j.patcog.2020.107624
|
| [28] |
R. Wang, F. Nie, Z. Wang, H. Hu, X. Li, Parameter-free weighted multi-view projected clustering with structured graph learning, IEEE Trans. Knowl. Data Eng., 32 (2020), 2014–2025. https://doi.org/10.1109/TKDE.2019.2913377 doi: 10.1109/TKDE.2019.2913377
|
| [29] |
C. Peng, Z. Kang, S. Cai, Q. Cheng, Integrate and conquer: double-sided two-dimensional k-means via integrating of projection and manifold construction, ACM Tran. Intel. Syst. Tech., 9 (2018), 57. https://doi.org/10.1145/3200488 doi: 10.1145/3200488
|
| [30] |
C. Peng, Z. Kang, Y. Hu, J. Cheng, Q. Cheng, Robust graph regularized nonnegative matrix factorization for clustering, ACM Trans. Knowl. Discov. Data, 11 (2017), 33. https://doi.org/10.1145/3003730 doi: 10.1145/3003730
|
| [31] |
D. Cai, X. He, X. Wu, J. Han, Non-negative matrix factorization on manifold, Proceedings of IEEE International Conference on Data Mining, 2008, 63–72. https://doi.org/10.1109/ICDM.2008.57 doi: 10.1109/ICDM.2008.57
|
| [32] |
D. Cai, X. He, J. Han, Locally consistent concept factorization for document clustering, IEEE Trans. Knowl. Data Eng., 23 (2011), 902–913. https://doi.org/10.1109/TKDE.2010.165 doi: 10.1109/TKDE.2010.165
|
| [33] |
W. Xu, X. Liu, Y. Gong, Document clustering based on non-negative matrix factorization, Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval, 2003,267–273. https://doi.org/10.1145/860435.860485 doi: 10.1145/860435.860485
|
| [34] |
M. Yin, J. Gao, Z. Lin, Laplacian regularized low-rank representation and its applications, IEEE Trans. Pattern Anal., 38 (2016), 504–517. https://doi.org/10.1109/TPAMI.2015.2462360 doi: 10.1109/TPAMI.2015.2462360
|
| [35] |
R. Liu, H. Wang, X. Yu, Shared-nearest-neighbor-based clustering by fast search and find of density peaks, Inform. Sciences, 450 (2018), 200–226. https://doi.org/10.1016/j.ins.2018.03.031 doi: 10.1016/j.ins.2018.03.031
|
| [36] |
Y. Chen, S. Tang, L. Zhou, C. Wang, J. Du, T. Wang, et al., Decentralized clustering by finding loose and distributed density cores, Inform. Sciences, 433–434 (2018), 510–526. https://doi.org/10.1016/j.ins.2016.08.009 doi: 10.1016/j.ins.2016.08.009
|
| [37] |
Y. Chen, S. Tang, S. Pei, C. Wang, J. Du, N. Xiong, DHeat: a density heat-based algorithm for clustering with effective radius, IEEE Trans. Syst. Man Cybern., 48 (2018), 649–660. https://doi.org/10.1109/TSMC.2017.2745493 doi: 10.1109/TSMC.2017.2745493
|
| [38] |
E. Müller, S. Günnemann, I. Assent, T. Seidl, Evaluating clustering in subspace projections of high dimensional data, Proc. VLDB Endow., 2 (2009), 1270–1281. https://doi.org/10.14778/1687627.1687770 doi: 10.14778/1687627.1687770
|
| [39] |
D. Cai, X. He, J. Han, Document clustering using locality preserving indexing, IEEE Trans. Knowl. Data Eng., 17 (2005), 1624–1637. https://doi.org/10.1109/TKDE.2005.198 doi: 10.1109/TKDE.2005.198
|
| [40] | H. Zha, X. He, C. Ding, M. Gu, H. Simon, Spectral relaxation for k-means clustering, In: Advances in neural information processing systems 14, Cambridge: MIT Press, 2001, 1057–1064. |
| [41] |
N. Slonim, N. Tishby, Document clustering using word clusters via the information bottleneck method, Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval, 2000,208–215. https://doi.org/10.1145/345508.345578 doi: 10.1145/345508.345578
|
| [42] | E. Rendón, I. Abundez, A. Arizmendi, E. M. Quiroz, Internal versus external cluster validation indexes, International Journal of Computer Networks and Communications, 5 (2011), 27–34. |
| [43] |
M. C. P. de Souto, A. L. V. Coelho, K. Faceli, T. C. Sakata, V. Bonadia, I. G. Costa, A comparison of external clustering evaluation indices in the context of imbalanced data sets, Proceedings of Brazilian Symposium on Neural Networks, 2012, 49–54. https://doi.org/10.1109/SBRN.2012.25 doi: 10.1109/SBRN.2012.25
|
| [44] |
P. Fränti, M. Rezaei, Q. Zhao, Centroid index: cluster level similarity measure, Pattern Recogn., 47 (2014), 3034–3045. https://doi.org/10.1016/j.patcog.2014.03.017 doi: 10.1016/j.patcog.2014.03.017
|
| [45] |
Q. Zhao, P. Fränti, Centroid ratio for pairwise random swap clustering algorithm, IEEE Trans. Knowl. Data Eng., 26 (2014), 1090–1101. https://doi.org/10.1109/TKDE.2013.113 doi: 10.1109/TKDE.2013.113
|
| [46] |
P. Fränti, M. Rezaei, Generalized centroid index to different clustering models, Proceedings of Structural, Syntactic, and Statistical Pattern Recognition, 2016,285–296. https://doi.org/10.1007/978-3-319-49055-7_26 doi: 10.1007/978-3-319-49055-7_26
|
| [47] |
M. Rezaei, P. Fränti, Can the number of clusters be determined by external indices? IEEE Access, 8 (2020), 89239–89257. https://doi.org/10.1109/ACCESS.2020.2993295 doi: 10.1109/ACCESS.2020.2993295
|
| [48] |
R. Jonker, A. Volgenant, A shortest augmenting path algorithm for dense and sparse linear assignment problems, Computing, 38 (1987), 325–340. https://doi.org/10.1007/BF02278710 doi: 10.1007/BF02278710
|







Figures(8) / Tables(2)
Pasi Fränti, Sami Sieranoja. Clustering accuracy[J]. Applied Computing and Intelligence, 2024, 4(1): 24-44. doi: 10.3934/aci.2024003







 DownLoad:
DownLoad: