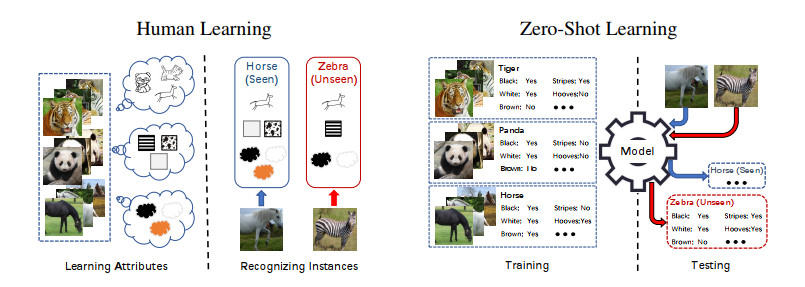
Deep learning methods may decline in their performance when the number of labelled training samples is limited, in a scenario known as few-shot learning. The methods may even degrade the accuracy in classifying instances of classes that have not been seen previously, called zero-shot learning. While the classification results achieved by the zero-shot learning methods are steadily improved, different problem settings, and diverse experimental setups have emerged. It becomes difficult to measure fairly the effectiveness of each proposed method, thus hindering further research in the field. In this article, a comprehensive survey is given on the methodology, implementation, and fair evaluations for practical and applied computing facets on the recent progress of zero-shot learning.
Citation: Guanyu Yang, Zihan Ye, Rui Zhang, Kaizhu Huang. A comprehensive survey of zero-shot image classification: methods, implementation, and fair evaluation[J]. Applied Computing and Intelligence, 2022, 2(1): 1-31. doi: 10.3934/aci.2022001
Deep learning methods may decline in their performance when the number of labelled training samples is limited, in a scenario known as few-shot learning. The methods may even degrade the accuracy in classifying instances of classes that have not been seen previously, called zero-shot learning. While the classification results achieved by the zero-shot learning methods are steadily improved, different problem settings, and diverse experimental setups have emerged. It becomes difficult to measure fairly the effectiveness of each proposed method, thus hindering further research in the field. In this article, a comprehensive survey is given on the methodology, implementation, and fair evaluations for practical and applied computing facets on the recent progress of zero-shot learning.

| [1] | Z. Akata, F. Perronnin, Z. Harchaoui, C. Schmid, Label-embedding for attribute-based classification, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2013), 819–826. https://doi.org/10.1109/CVPR.2013.111 |
| [2] |
Z. Akata, F. Perronnin, Z. Harchaoui, C. Schmid, Label-embedding for image classification, IEEE T. Pattern Anal., 38 (2015), 1425–1438. https://doi.org/10.1109/TPAMI.2015.2487986 doi: 10.1109/TPAMI.2015.2487986

|
| [3] | Z. Akata, S. Reed, D. Walter, H. Lee, B. Schiele, Evaluation of output embeddings for fine-grained image classification, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 2927–2936. https://doi.org/10.1109/CVPR.2015.7298911 |
| [4] | Y. Annadani, S. Biswas, Preserving semantic relations for zero-shot learning, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 7603–7612. |
| [5] | N. Bendre, K. Desai, P. Najafirad, Generalized zero-shot learning using multimodal variational auto-encoder with semantic concepts, IEEE International Conference on Image Processing (ICIP), (2021), 1284–1288. https://doi.org/10.1109/ICIP42928.2021.9506108 |
| [6] |
I. Biederman, Recognition-by-components: a theory of human image understanding, Psychol. Rev., 94 (1987), 115. 10.1037/0033-295X.94.2.115 doi: 10.1037/0033-295X.94.2.115
|
| [7] | L. Bo, Q. Dong, Z. Hu, Hardness sampling for self-training based transductive zero-shot learning, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 16499–16508. https://doi.org/10.1109/CVPR46437.2021.01623 |
| [8] | S. Changpinyo, W.-L. Chao, B. Gong, F. Sha, Synthesized classifiers for zero-shot learning, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 5327–5336. https://doi.org/10.1109/CVPR.2016.575 |
| [9] | W.-L. Chao, S. Changpinyo, B. Gong, F. Sha, An empirical study and analysis of generalized zero-shot learning for object recognition in the wild, European Conference on Computer Vision (ECCV), (2016), 52–68. https://doi.org/10.1007/978-3-319-46475-6_4 |
| [10] | Q. Chen, W. Wang, K. Huang, F. Coenen, Zero-shot text classification via knowledge graph embedding for social media data, IEEE Internet Things, (2021). https://doi.org/10.1109/JIOT.2021.3093065 |
| [11] | Y.-J. Chen, Y.-J. Chang, S.-C. Wen, Y. Shi, X. Xu, T.-Y. Ho, Q. Jia, M. Huang, et al., Zero-shot medical image artifact reduction, IEEE 17th International Symposium on Biomedical Imaging (ISBI), (2020), 862–866. https://doi.org/10.1109/ISBI45749.2020.9098566 |
| [12] | J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, L. Fei-Fei, Imagenet: A large-scale hierarchical image database, 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2009), 248–255. https://doi.org/10.1109/CVPR.2009.5206848 |
| [13] | M. Elhoseiny, B. Saleh, A. Elgammal, Write a classifier: Zero-shot learning using purely textual descriptions, Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2013), 2584–2591. https://doi.org/10.1109/ICCV.2013.321 |
| [14] | M. Elhoseiny, Y. Zhu, H. Zhang, A. Elgammal, Link the head to the" beak": Zero shot learning from noisy text description at part precision, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 5640–5649. https://doi.org/10.1109/CVPR.2017.666 |
| [15] | A. Farhadi, I. Endres, D. Hoiem, D. Forsyth, Describing objects by their attributes, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2009), 1778–1785. https://doi.org/10.1109/CVPR.2009.5206772 |
| [16] | C. Finn, P. Abbeel, S. Levine, Model-agnostic meta-learning for fast adaptation of deep networks, Proceedings of the 34th International Conference on Machine Learning (ICML), 70 (2017), |
| [17] | A. Frome, G. S. Corrado, J. Shlens, S. Bengio, J. Dean, M. Ranzato, T. Mikolov, Devise: A deep visual-semantic embedding model, Advances in neural information processing systems, 26 (2013), 2121–2129. |
| [18] |
Y. Fu, T. M. Hospedales, T. Xiang, S. Gong, Transductive multi-view zero-shot learning, IEEE T. Pattern Anal., 37 (2015), 2332–2345. https://doi.org/10.1109/TPAMI.2015.2408354 doi: 10.1109/TPAMI.2015.2408354
|
| [19] | Z. Fu, T. Xiang, E. Kodirov, S. Gong, Zero-shot object recognition by semantic manifold distance, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 2635–2644. https://doi.org/10.1109/CVPR.2015.7298879 |
| [20] | I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio, Generative adversarial nets, Advances in neural information processing systems, (2014), 2672–2680. |
| [21] | I. J. Goodfellow, J. Shlens, C. Szegedy, Explaining and harnessing adversarial examples, 3rd International Conference on Learning Representations (ICLR), (2015). |
| [22] |
M. Gull, O. Arif, Generalized zero-shot learning using identifiable variational autoencoders, Expert Syst. Appl., 191 (2022), 116268. https://doi.org/10.1016/j.eswa.2021.116268 doi: 10.1016/j.eswa.2021.116268
|
| [23] | I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, A. C. Courville, Improved training of wasserstein gans, Advances in neural information processing systems, 30 (2017), 5767–5777. |
| [24] | Y. Guo, G. Ding, J. Han, Y. Gao, Sitnet: Discrete similarity transfer network for zero-shot hashing., the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI), (2017), 1767–1773. https://doi.org/10.24963/ijcai.2017/245 |
| [25] | Z. Han, Z. Fu, S. Chen, J. Yang, Contrastive embedding for generalized zero-shot learning, {IEEE/CVF} Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 2371–2381. https://doi.org/10.1109/CVPR46437.2021.00240 |
| [26] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [27] | R. L. Hu, C. Xiong, R. Socher, Correction networks: Meta-learning for zero-shot learning, 2018. |
| [28] | H. Huang, C. Wang, P. S. Yu, C.-D. Wang, Generative dual adversarial network for generalized zero-shot learning, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 801–810. https://doi.org/10.1109/CVPR.2019.00089 |
| [29] | K. Huang, A. Hussain, Q.-F. Wang, R. Zhang, Deep Learning: Fundamentals, Theory and Applications, Springer, 2019. |
| [30] | Y.-H. Hubert Tsai, L.-K. Huang, R. Salakhutdinov, Learning robust visual-semantic embeddings, Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2017), 3571–3580. https://doi.org/10.1109/ICCV.2017.386 |
| [31] | D. Huynh, E. Elhamifar, Fine-grained generalized zero-shot learning via dense attribute-based attention, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 4483–4493. https://doi.org/10.1109/CVPR42600.2020.00454 |
| [32] | D. Jayaraman, F. Sha, K. Grauman, Decorrelating semantic visual attributes by resisting the urge to share, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2014), 1629–1636. https://doi.org/10.1109/CVPR.2014.211 |
| [33] | Z. Ji, Y. Fu, J. Guo, Y. Pang, Z. M. Zhang, Stacked semantics-guided attention model for fine-grained zero-shot learning, Advances in Neural Information Processing Systems, 31 (2018), 5998–6007. |
| [34] |
Z. Ji, H. Wang, Y. Pang, L. Shao, Dual triplet network for image zero-shot learning, Neurocomputing, 373 (2020), 90–97. https://doi.org/10.1016/j.neucom.2019.09.062 doi: 10.1016/j.neucom.2019.09.062
|
| [35] | H. Jiang, G. Yang, K. Huang, R. Zhang, W-net: one-shot arbitrary-style chinese character generation with deep neural networks, International Conference on Neural Information Processing, (2018), 483–493. https://doi.org/10.1007/978-3-030-04221-9_43 |
| [36] | H. Jiang, R. Wang, S. Shan, X. Chen, Transferable contrastive network for generalized zero-shot learning, Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2019), 9765–9774. https://doi.org/10.1109/ICCV.2019.00986 |
| [37] | T. Joachims, Optimizing search engines using clickthrough data, Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, (2002), 133–142. https://doi.org/10.1145/775047.775067 |
| [38] | M. Kampffmeyer, Y. Chen, X. Liang, H. Wang, Y. Zhang, E. P. Xing, Rethinking knowledge graph propagation for zero-shot learning, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 11487–11496. https://doi.org/10.1109/CVPR.2019.01175 |
| [39] | D. P. Kingma, M. Welling, Auto-encoding variational bayes, 2nd International Conference on Learning Representations (ICLR), (2014). |
| [40] | T. N. Kipf, M. Welling, Semi-supervised classification with graph convolutional networks, 5th International Conference on Learning Representations (ICLR), OpenReview.net, (2017). |
| [41] | E. Kodirov, T. Xiang, S. Gong, Semantic autoencoder for zero-shot learning, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 3174–3183. https://doi.org/10.1109/CVPR.2017.473 |
| [42] | A. Kumar, P. Sattigeri, A. Balakrishnan, Variational inference of disentangled latent concepts from unlabelled observations, 6th International Conference on Learning Representations (ICLR), (2018). |
| [43] | C. H. Lampert, H. Nickisch, S. Harmeling, Learning to detect unseen object classes by between-class attribute transfer, 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2009), 951–958. https://doi.org/10.1109/CVPR.2009.5206594 |
| [44] |
C. H. Lampert, H. Nickisch, S. Harmeling, Attribute-based classification for zero-shot visual object categorization, IEEE T. Pattern Anal., 36 (2014), 453–465. https://doi.org/10.1109/TPAMI.2013.140 doi: 10.1109/TPAMI.2013.140
|
| [45] | H. Larochelle, D. Erhan, Y. Bengio, Zero-data learning of new tasks, Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, (2008), 646–651. |
| [46] | J. Lei Ba, K. Swersky, S. Fidler, Predicting deep zero-shot convolutional neural networks using textual descriptions, Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2015), 4247–4255. https://doi.org/10.1109/ICCV.2015.483 |
| [47] |
A. Li, Z. Lu, J. Guan, T. Xiang, L. Wang, J. Wen, Transferrable feature and projection learning with class hierarchy for zero-shot learning, Int. J. Comput. Vis., 128 (2020), 2810–2827. https://doi.org/10.1007/s11263-020-01342-x doi: 10.1007/s11263-020-01342-x
|
| [48] | J. Li, X. Lan, Y. Liu, L. Wang, N. Zheng, Compressing unknown images with product quantizer for efficient zero-shot classification, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 5463–5472. https://doi.org/10.1109/CVPR.2019.00561 |
| [49] | J. Li, M. Jing, K. Lu, Z. Ding, L. Zhu, Z. Huang, Leveraging the invariant side of generative zero-shot learning, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 7402–7411. https://doi.org/10.1109/CVPR.2019.00758 |
| [50] | X. Li, Z. Xu, K. Wei, C. Deng, Generalized zero-shot learning via disentangled representation, Proceedings of the AAAI Conference on Artificial Intelligence, 35 (2021), 1966–1974. |
| [51] | Y. Li, J. Zhang, J. Zhang, K. Huang, Discriminative learning of latent features for zero-shot recognition, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 7463–7471. https://doi.org/10.1109/CVPR.2018.00779 |
| [52] | T.-Y. Lin, A. RoyChowdhury, S. Maji, Bilinear cnn models for fine-grained visual recognition, Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2015), 1449–1457. https://doi.org/10.1109/ICCV.2015.170 |
| [53] | G. Liu, J. Guan, M. Zhang, J. Zhang, Z. Wang, Z. Lu, Joint projection and subspace learning for zero-shot recognition, 2019 IEEE International Conference on Multimedia and Expo (ICME), (2019), 1228–1233. https://doi.org/10.1109/ICME.2019.00214 |
| [54] | L. Liu, T. Zhou, G. Long, J. Jiang, X. Dong, C. Zhang, Isometric propagation network for generalized zero-shot learning, 9th International Conference on Learning Representations (ICLR), OpenReview.net, (2021). |
| [55] | Y. Liu, Q. Gao, J. Li, J. Han, L. Shao, Zero shot learning via low-rank embedded semantic autoencoder, the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI), (2018), 2490–2496. https://doi.org/10.24963/ijcai.2018/345 |
| [56] |
Y. Liu, X. Gao, Q. Gao, J. Han, L. Shao, Label-activating framework for zero-shot learning, Neural Networks, 121 (2020), 1–9. https://doi.org/10.1016/j.neunet.2019.08.023 doi: 10.1016/j.neunet.2019.08.023
|
| [57] | Y. Liu, J. Guo, D. Cai, X. He, Attribute attention for semantic disambiguation in zero-shot learning, Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 6698–6707. https://doi.org/10.1109/ICCV.2019.00680 |
| [58] | Y. Liu, L. Zhou, X. Bai, Y. Huang, L. Gu, J. Zhou, T. Harada, Goal-oriented gaze estimation for zero-shot learning, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 3794–3803. https://doi.org/10.1109/CVPR46437.2021.00379 |
| [59] | Z. Liu, Y. Li, L. Yao, X. Wang, G. Long, Task aligned generative meta-learning for zero-shot learning, Proceedings of The Thirty-Fifth AAAI Conference on Artificial Intelligence, (2021). |
| [60] | Y. Long, L. Liu, L. Shao, Attribute embedding with visual-semantic ambiguity removal for zero-shot learning, Proceedings of the British Machine Vision Conference 2016, BMVA Press, (2016). https://doi.org/10.5244/C.30.40 |
| [61] | Y. Long, L. Liu, L. Shao, F. Shen, G. Ding, J. Han, From zero-shot learning to conventional supervised classification: Unseen visual data synthesis, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 1627–1636. https://doi.org/10.1109/CVPR.2017.653 |
| [62] |
Y. Luo, X. Wang, F. Pourpanah, Dual VAEGAN: A generative model for generalized zero-shot learning, Appl. Soft Comput., 107 (2021), 107352. https://doi.org/10.1016/j.asoc.2021.107352 doi: 10.1016/j.asoc.2021.107352
|
| [63] | C. Lyu, K. Huang, H.-N. Liang, A unified gradient regularization family for adversarial examples, 2015 IEEE international conference on data mining, (2015), 301–309. https://doi.org/10.1109/ICDM.2015.84 |
| [64] |
P. Ma, X. Hu, A variational autoencoder with deep embedding model for generalized zero-shot learning, Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 11733–11740. https://doi.org/10.1609/aaai.v34i07.6844 doi: 10.1609/aaai.v34i07.6844
|
| [65] | S. Min, H. Yao, H. Xie, C. Wang, Z.-J. Zha, Y. Zhang, Domain-aware visual bias eliminating for generalized zero-shot learning, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 12664–12673. https://doi.org/10.1109/CVPR42600.2020.01268 |
| [66] | A. Mishra, S. Krishna Reddy, A. Mittal, H. A. Murthy, A generative model for zero shot learning using conditional variational autoencoders, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) workshops, (2018), 2188–2196. https://doi.org/10.1109/CVPRW.2018.00294 |
| [67] |
T. M. Mitchell, S. V. Shinkareva, A. Carlson, K.-M. Chang, V. L. Malave, R. A. Mason, M. A. Just, Predicting human brain activity associated with the meanings of nouns, science, 320 (2008), 1191–1195. https://doi.org/10.1126/science.1152876 doi: 10.1126/science.1152876
|
| [68] | M. Nilsback, A. Zisserman, Automated flower classification over a large number of classes, Sixth Indian Conference on Computer Vision, Graphics & Image Processing, (2008), 722–729. https://doi.org/10.1109/ICVGIP.2008.47 |
| [69] | M. Norouzi, T. Mikolov, S. Bengio, Y. Singer, J. Shlens, A. Frome, G. Corrado, J. Dean, Zero-shot learning by convex combination of semantic embeddings, 2nd International Conference on Learning Representations (ICLR) (eds. Y. Bengio and Y. LeCun), (2014). |
| [70] | M. Palatucci, D. Pomerleau, G. E. Hinton, T. M. Mitchell, Zero-shot learning with semantic output codes, Advances in neural information processing systems, (2009), 1410–1418. |
| [71] | D. Parikh, K. Grauman, Relative attributes, 2011 International Conference on Computer Vision (ICCV), (2011), 503–510. https://doi.org/10.1109/ICCV.2011.6126281 |
| [72] | G. Patterson, J. Hays, SUN attribute database: Discovering, annotating, and recognizing scene attributes, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2012), 2751–2758. |
| [73] | F. Pourpanah, M. Abdar, Y. Luo, X. Zhou, R. Wang, C. P. Lim, X.-Z. Wang, A review of generalized zero-shot learning methods, arXiv preprint arXiv: 2011.08641. |
| [74] | R. Qiao, L. Liu, C. Shen, A. Van Den Hengel, Less is more: zero-shot learning from online textual documents with noise suppression, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 2249–2257. https://doi.org/10.1109/CVPR.2016.247 |
| [75] | S. Ravi, H. Larochelle, Optimization as a model for few-shot learning, 5th International Conference on Learning Representations (ICLR), OpenReview.net, (2017). |
| [76] | S. Reed, Z. Akata, H. Lee, B. Schiele, Learning deep representations of fine-grained visual descriptions, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 49–58. https://doi.org/10.1109/CVPR.2016.13 |
| [77] | B. Romera-Paredes, P. Torr, An embarrassingly simple approach to zero-shot learning, International Conference on Machine Learning (ICML), (2015), 2152–2161. |
| [78] |
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, et al., Imagenet large scale visual recognition challenge, Int. J. Comput. Vision, 115 (2015), 211–252. https://doi.org/10.1007/s11263-015-0816-y doi: 10.1007/s11263-015-0816-y
|
| [79] | C. Samplawski, E. Learned-Miller, H. Kwon, B. M. Marlin, Zero-shot learning in the presence of hierarchically coarsened labels, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, (2020), 926–927. https://doi.org/10.1109/CVPRW50498.2020.00471 |
| [80] | M. B. Sariyildiz, R. G. Cinbis, Gradient matching generative networks for zero-shot learning, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 2168–2178. https://doi.org/10.1109/CVPR.2019.00227 |
| [81] | E. Schonfeld, S. Ebrahimi, S. Sinha, T. Darrell, Z. Akata, Generalized zero-and few-shot learning via aligned variational autoencoders, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 8247–8255. https://doi.org/10.1109/CVPR.2019.00844 |
| [82] |
T. Shermin, S. W. Teng, F. Sohel, M. Murshed, G. Lu, Integrated generalized zero-shot learning for fine-grained classification, Pattern Recogn., 122 (2022), 108246. https://doi.org/10.1016/j.patcog.2021.108246 doi: 10.1016/j.patcog.2021.108246
|
| [83] | I. Skorokhodov, M. Elhoseiny, Class normalization for (continual)? generalized zero-shot learning, 9th International Conference on Learning Representations (ICLR), OpenReview.net, 2021. |
| [84] | J. Snell, K. Swersky, R. Zemel, Prototypical networks for few-shot learning, Advances in Neural Information Processing Systems, (2017), 4077–4087. |
| [85] | R. Socher, M. Ganjoo, C. D. Manning, A. Y. Ng, Zero-shot learning through cross-modal transfer, Advances in Neural Information Processing Systems, (2013), 935–943. |
| [86] | K. Sohn, H. Lee and X. Yan, Learning structured output representation using deep conditional generative models, Advances in neural information processing systems, 28 (2015), 3483–3491. |
| [87] | J. Song, C. Shen, Y. Yang, Y. Liu, M. Song, Transductive unbiased embedding for zero-shot learning, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 1024–1033. https://doi.org/10.1109/CVPR.2018.00113 |
| [88] | F. Sung, Y. Yang, L. Zhang, T. Xiang, P. H. Torr, T. M. Hospedales, Learning to compare: Relation network for few-shot learning, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 1199–1208. https://doi.org/10.1109/CVPR.2018.00131 |
| [89] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, et al., Pattern Recognition (CVPR)}, (2015), 1–9. https://doi.org/10.1109/CVPR.2015.7298594 |
| [90] | V. K. Verma, G. Arora, A. Mishra, P. Rai, Generalized zero-shot learning via synthesized examples, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 4281–4289. https://doi.org/10.1109/CVPR.2018.00450 |
| [91] | V. K. Verma, D. Brahma, P. Rai, Meta-learning for generalized zero-shot learning, The Thirty-Fourth AAAI Conference on Artificial Intelligence, (2020), 6062–6069. https://doi.org/10.1609/aaai.v34i04.6069 |
| [92] | V. K. Verma, A. Mishra, A. Pandey, H. A. Murthy, P. Rai, Towards zero-shot learning with fewer seen class examples, IEEE Winter Conference on Applications of Computer Vision, (2021), 2240–2250. https://doi.org/10.1109/WACV48630.2021.00229 |
| [93] | V. K. Verma, P. Rai, A simple exponential family framework for zero-shot learning, Joint European conference on machine learning and knowledge discovery in databases, (2017), 792–808. https://doi.org/10.1007/978-3-319-71246-8_48 |
| [94] | O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra, Matching networks for one shot learning, Advances in neural information processing systems, 29 (2016), 3630–3638. |
| [95] | C. Wah, S. Branson, P. Welinder, P. Perona, S. Belongie, The caltech-ucsd birds-200-2011 dataset, California Institute of Technology, 2011. |
| [96] | D. Wang, Y. Li, Y. Lin, Y. Zhuang, Relational knowledge transfer for zero-shot learning, Thirtieth AAAI Conference on Artificial Intelligence, (2016). |
| [97] | F. Wang, M. Jiang, C. Qian, S. Yang, C. Li, H. Zhang, X. Wang, X. Tang, Residual attention network for image classification, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 3156–3164. https://doi.org/10.1109/CVPR.2017.683 |
| [98] | J. Wang, B. Jiang, Zero-shot learning via contrastive learning on dual knowledge graphs, Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 885–892. https://doi.org/10.1109/ICCVW54120.2021.00104 |
| [99] | W. Wang, V. W. Zheng, H. Yu, C. Miao, A survey of zero-shot learning: Settings, methods, and applications, ACM T. Intel. Syst. Tec. (TIST), 10 (2019), 1–37. |
| [100] | X. Wang, Y. Ye, A. Gupta, Zero-shot recognition via semantic embeddings and knowledge graphs, {IEEE/CVF} Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 6857–6866. https://doi.org/10.1109/CVPR.2018.00717 |
| [101] |
Y. Wang, H. Zhang, Z. Zhang, Y. Long, Asymmetric graph based zero shot learning, Multim. Tools Appl., 79 (2020), 33689–33710. https://doi.org/10.1007/s11042-019-7689-y doi: 10.1007/s11042-019-7689-y
|
| [102] | J. Weston, S. Bengio, N. Usunier, Wsabie: Scaling up to large vocabulary image annotation, the Twenty-Second International Joint Conference on Artificial Intelligence (IJCAI), (2011). |
| [103] | Y. Xian, Z. Akata, G. Sharma, Q. Nguyen, M. Hein, B. Schiele, Latent embeddings for zero-shot classification, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 69–77. https://doi.org/10.1109/CVPR.2016.15 |
| [104] | Y. Xian, C. H. Lampert, B. Schiele, Z. Akata, Zero-shot learning-a comprehensive evaluation of the good, the bad and the ugly, IEEE T. Pattern Anal., 41 (2018), 2251–2265. |
| [105] | Y. Xian, T. Lorenz, B. Schiele, Z. Akata, Feature generating networks for zero-shot learning, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 5542–5551. https://doi.org/10.1109/CVPR.2018.00581 |
| [106] | Y. Xian, S. Sharma, B. Schiele, Z. Akata, f-vaegan-d2: A feature generating framework for any-shot learning, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 10275–10284. https://doi.org/10.1109/CVPR.2019.01052 |
| [107] |
C. Xie, H. Xiang, T. Zeng, Y. Yang, B. Yu, Q. Liu, Cross knowledge-based generative zero-shot learning approach with taxonomy regularization, Neural Networks, 139 (2021), 168–178. https://doi.org/10.1016/j.neunet.2021.02.009 doi: 10.1016/j.neunet.2021.02.009
|
| [108] | G.-S. Xie, L. Liu, X. Jin, F. Zhu, Z. Zhang, J. Qin, Y. Yao, L. Shao, Attentive region embedding network for zero-shot learning, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 9384–9393. https://doi.org/10.1109/CVPR.2019.00961 |
| [109] | G.-S. Xie, L. Liu, F. Zhu, F. Zhao, Z. Zhang, Y. Yao, J. Qin, L. Shao, Region graph embedding network for zero-shot learning, European Conference on Computer Vision (ECCV), (2020), 562–580. https://doi.org/10.1007/978-3-030-58548-8_33 |
| [110] | B. Xu, Z. Zeng, C. Lian, Z. Ding, Semi-supervised low-rank semantics grouping for zero-shot learning, IEEE Trans. Image Process., 30 (2021), 2207–2219. https://doi.org/10.1109/TIP.2021.3050677 |
| [111] |
T. Xu, Y. Zhao, X. Liu, Dual generative network with discriminative information for generalized zero-shot learning, Complexity, 2021 (2021), 6656797:1–6656797:11. https://doi.org/10.1155/2021/6656797 doi: 10.1155/2021/6656797
|
| [112] | W. Xu, Y. Xian, J. Wang, B. Schiele, Z. Akata, Attribute prototype network for zero-shot learning, Advances in Neural Information Processing Systems, 33 (2020), 21969–21980. |
| [113] | G. Yang, K. Huang, R. Zhang, J. Y. Goulermas, A. Hussain, Self-focus deep embedding model for coarse-grained zero-shot classification, International Conference on Brain Inspired Cognitive Systems, (2019), 12–22. |
| [114] | G. Yang, K. Huang, R. Zhang, J. Y. Goulermas, A. Hussain, Inductive generalized zero-shot learning with adversarial relation network, Joint European Conference on Machine Learning and Knowledge Discovery in Databases, (2020), 724–739. |
| [115] | B. Yao, A. Khosla, L. Fei-Fei, Combining randomization and discrimination for fine-grained image categorization, CVPR 2011, (2011), 1577–1584. https://doi.org/10.1109/CVPR.2011.5995368 |
| [116] | Z. Ye, F. Hu, F. Lyu, L. Li, K. Huang, Disentangling semantic-to-visual confusion for zero-shot learning, IEEE T. Multimedia, (2021). doi: 10.1109/TMM.2021.3089017. https://doi.org/10.1109/TMM.2021.3089017 |
| [117] | Z. Ye, F. Lyu, L. Li, Q. Fu, J. Ren, F. Hu, Sr-gan: Semantic rectifying generative adversarial network for zero-shot learning, 2019 IEEE International Conference on Multimedia and Expo (ICME), (2019), 85–90. https://doi.org/10.1109/ICME.2019.00023 |
| [118] |
Y. Yu, Z. Ji, J. Guo, Z. Zhang, Zero-shot learning via latent space encoding, IEEE T. Cybernetics, 49 (2018), 3755–3766. https://doi.org/10.1109/TCYB.2018.2850750 doi: 10.1109/TCYB.2018.2850750
|
| [119] | F. Zhang, G. Shi, Co-representation network for generalized zero-shot learning, International Conference on Machine Learning (ICML), (2019), 7434–7443. |
| [120] |
H. Zhang, Y. Long, Y. Guan, L. Shao, Triple verification network for generalized zero-shot learning, IEEE T. Image Process., 28 (2019), 506–517. https://doi.org/10.1109/TIP.2018.2869696 doi: 10.1109/TIP.2018.2869696
|
| [121] | L. Zhang, T. Xiang, S. Gong, Learning a deep embedding model for zero-shot learning, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 2021–2030. https://doi.org/10.1109/CVPR.2017.321 |
| [122] | Z. Zhang, V. Saligrama, Zero-shot learning via semantic similarity embedding, Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2015), 4166–4174. https://doi.org/10.1109/ICCV.2015.474 |
| [123] | H. Zheng, J. Fu, T. Mei, J. Luo, Learning multi-attention convolutional neural network for fine-grained image recognition, Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2017), 5209–5217. https://doi.org/10.1109/ICCV.2017.557 |
| [124] | Y. Zhu, J. Xie, B. Liu, A. Elgammal, Learning feature-to-feature translator by alternating back-propagation for generative zero-shot learning, Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 9844–9854. https://doi.org/10.1109/ICCV.2019.00994 |
| [125] | Y. Zhu, J. Xie, Z. Tang, X. Peng, A. Elgammal, Semantic-guided multi-attention localization for zero-shot learning, Advances in Neural Information Processing Systems, 32 (2019), 14917–14927. |





Figures(6) / Tables(3)
Guanyu Yang, Zihan Ye, Rui Zhang, Kaizhu Huang. A comprehensive survey of zero-shot image classification: methods, implementation, and fair evaluation[J]. Applied Computing and Intelligence, 2022, 2(1): 1-31. doi: 10.3934/aci.2022001







 DownLoad:
DownLoad: