Given the competitiveness of a market-making environment, the ability to speedily quote option prices consistent with an ever-changing market environment is essential. Thus, the smallest acceleration or improvement over traditional pricing methods is crucial to avoid arbitrage. We propose a method for accelerating the pricing of American options to near-instantaneous using a feed-forward neural network. This neural network is trained over the chosen (e.g., Heston) stochastic volatility specification. Such an approach facilitates parameter interpretability, as generally required by the regulators, and establishes our method in the area of eXplainable Artificial Intelligence (XAI) for finance. We show that the proposed deep explainable pricer induces a speed-accuracy trade-off compared to the typical Monte Carlo or Partial Differential Equation-based pricing methods. Moreover, the proposed approach allows for pricing derivatives with path-dependent and more complex payoffs and is, given the sufficient accuracy of computation and its tractable nature, applicable in a market-making environment.
Citation: David Anderson, Urban Ulrych. Accelerated American option pricing with deep neural networks[J]. Quantitative Finance and Economics, 2023, 7(2): 207-228. doi: 10.3934/QFE.2023011
Given the competitiveness of a market-making environment, the ability to speedily quote option prices consistent with an ever-changing market environment is essential. Thus, the smallest acceleration or improvement over traditional pricing methods is crucial to avoid arbitrage. We propose a method for accelerating the pricing of American options to near-instantaneous using a feed-forward neural network. This neural network is trained over the chosen (e.g., Heston) stochastic volatility specification. Such an approach facilitates parameter interpretability, as generally required by the regulators, and establishes our method in the area of eXplainable Artificial Intelligence (XAI) for finance. We show that the proposed deep explainable pricer induces a speed-accuracy trade-off compared to the typical Monte Carlo or Partial Differential Equation-based pricing methods. Moreover, the proposed approach allows for pricing derivatives with path-dependent and more complex payoffs and is, given the sufficient accuracy of computation and its tractable nature, applicable in a market-making environment.

| [1] |
AitSahlia F, Goswami M, Guha S (2010) American option pricing under stochastic volatility: an efficient numerical approach. Comput Manag Sci 7: 171–187. https://doi.org/10.1007/s10287-008-0082-3 doi: 10.1007/s10287-008-0082-3

|
| [2] |
Anders U, Korn O, Schmitt C (1998) Improving the pricing of options: a neural network approach. J Forecasting 17: 369–388. https://doi.org/10.1002/(SICI)1099-131X(1998090)17:5/6<369::AID-FOR702>3.0.CO;2-S doi: 10.1002/(SICI)1099-131X(1998090)17:5/6<369::AID-FOR702>3.0.CO;2-S
|
| [3] |
Andersen L, Lake M, Offengenden D (2016) High performance American option pricing. J Comput Financ 20: 39–87. https://doi.org/10.21314/JCF.2016.312 doi: 10.21314/JCF.2016.312
|
| [4] |
Andreou PC, Charalambous C, Martzoukos SH (2010) Generalized parameter functions for option pricing. J Bank Financ 34: 633–646. https://doi.org/10.1016/j.jbankfin.2009.08.027 doi: 10.1016/j.jbankfin.2009.08.027
|
| [5] |
Arrieta AB, Díaz-Rodríguez N, Ser JD, et al. (2020) Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf Fusion 58: 82–115. https://doi.org/10.1016/j.inffus.2019.12.012 doi: 10.1016/j.inffus.2019.12.012
|
| [6] |
Ascione G, Mehrdoust F, Orlando G, et al. (2023) Foreign exchange options on Heston-CIR model under Lévy process framework. Appl Math Comput 446: 127851. https://doi.org/10.1016/j.amc.2023.127851 doi: 10.1016/j.amc.2023.127851
|
| [7] |
Barndorff-Nielsen OE, Stelzer R (2013) The multivariate supOU stochastic volatility model. Math Financ 23: 275–296. https://doi.org/10.1111/j.1467-9965.2011.00494.x doi: 10.1111/j.1467-9965.2011.00494.x
|
| [8] |
Bayer C, Friz P, Gatheral J (2016) Pricing under rough volatility. Quant Financ 16: 887–904. https://doi.org/10.1080/14697688.2015.1099717 doi: 10.1080/14697688.2015.1099717
|
| [9] |
Bayer C, Tempone R, Wolfers S (2020) Pricing American options by exercise rate optimization. Quant Financ 20: 1749–1760. https://doi.org/10.1080/14697688.2020.1750678 doi: 10.1080/14697688.2020.1750678
|
| [10] |
Becker S, Cheridito P, Jentzen A (2020) Pricing and hedging American-style options with deep learning. J Risk Financ Manag 13: 158. https://doi.org/10.3390/jrfm13070158 doi: 10.3390/jrfm13070158
|
| [11] |
Black F, Scholes M, Merton R (1973) The pricing of options and corporate liabilities. J Polit Econ 81: 637–654. https://doi.org/10.1086/260062 doi: 10.1086/260062
|
| [12] | Boyle P (1986) Option valuation using a three-jump process. Int Options J 3: 7–12. |
| [13] |
Boyle P, Broadie M, Glasserman P (1997) Monte Carlo methods for security pricing. J Econ Dyn Control 21: 1267–1321. https://doi.org/10.1016/S0165-1889(97)00028-6 doi: 10.1016/S0165-1889(97)00028-6
|
| [14] |
Brennan M, Schwartz E (1977) The valuation of American put options. J Financ 32: 449–462. https://doi.org/10.2307/2326779 doi: 10.2307/2326779
|
| [15] |
Buehler H, Gonon L, Teichmann J, et al. (2019) Deep hedging. Quant Financ 19: 1271–1291. https://doi.org/10.1080/14697688.2019.1571683 doi: 10.1080/14697688.2019.1571683
|
| [16] | Caterini A, Chang DE (2018) Deep Neural Networks in a Mathematical Framework. Springer. https://doi.org/10.1007/978-3-319-75304-1 |
| [17] |
Chen F, Sutcliffe C (2012) Pricing and hedging short sterling options using neural networks. Intell Syst Account Financ Manag 19: 128–149. https://doi.org/10.1002/isaf.336 doi: 10.1002/isaf.336
|
| [18] |
Chen Y, Wan JWL (2021) Deep neural network framework based on backward stochastic differential equations for pricing and hedging American options in high dimensions. Quant Financ 21: 45–67. https://doi.org/10.1080/14697688.2020.1788219 doi: 10.1080/14697688.2020.1788219
|
| [19] |
Cont R (2001) Empirical properties of asset returns: stylized facts and statistical issues. Quant Financ 1: 223–236. https://doi.org/10.1080/713665670 doi: 10.1080/713665670
|
| [20] |
Cox JC, Ross SA, Rubinstein M (1979) Option pricing: A simplified approach. J Financ Econ 7: 229–263. https://doi.org/10.1016/0304-405X(79)90015-1 doi: 10.1016/0304-405X(79)90015-1
|
| [21] |
Crank J, Nicolson P (1947) A practical method for numerical evaluation of solutions of partial differential equations of the heat-conduction type. Math Proc Cambridge 43: 50–67. https://doi.org/10.1017/S0305004100023197 doi: 10.1017/S0305004100023197
|
| [22] | Directive-65/EU (2014) Directive 2014/65/eu of the european parliament and of the council of 15 may 2014 on markets in financial instruments and amending directive 2002/92/ec and directive 2011/61/eu. Official Journal of the European Union. |
| [23] | Dugas C, Bengio Y, Bélisle F, et al. (2009) Incorporating functional knowledge in neural networks. J Mach Learn Res 10: 1239–1262. |
| [24] |
Farkas W, Ferrari F, Ulrych U (2022) Pricing autocallables under local-stochastic volatility. Front Math Financ 1: 575–610. https://doi.org/10.3934/fmf.2022008 doi: 10.3934/fmf.2022008
|
| [25] | Fecamp S, Mikael J, Warin X (2019) Risk management with machine-learning-based algorithms. Working paper. |
| [26] | Ferguson R, Green A (2018) Deeply learning derivatives. Available at SSRN. |
| [27] |
Garcia R, Gençay R (2000) Pricing and hedging derivative securities with neural networks and a homogeneity hint. J Econometrics 94: 93–115. https://doi.org/10.1016/S0304-4076(99)00018-4 doi: 10.1016/S0304-4076(99)00018-4
|
| [28] |
Gaspar RM, Lopes SD, Sequeira B (2020) Neural network pricing of American put options. Risks 8: 73. https://doi.org/10.3390/risks8030073 doi: 10.3390/risks8030073
|
| [29] |
Gatheral J, Jaisson T, Rosenbaum M (2018) Volatility is rough. Quant Financ 18: 933–949. https://doi.org/10.1080/14697688.2017.1393551 doi: 10.1080/14697688.2017.1393551
|
| [30] |
Glasserman P, Kim KK (2011) Gamma expansion of the Heston stochastic volatility model. Financ Stoch 15: 267–296. https://doi.org/10.1007/s00780-009-0115-y doi: 10.1007/s00780-009-0115-y
|
| [31] |
Glau K, Kressner D, Statti F (2020) Low-rank tensor approximation for Chebyshev interpolation in parametric option pricing. SIAM J Financ Math 11: 897–927. https://doi.org/10.1137/19M1244172 doi: 10.1137/19M1244172
|
| [32] |
Gradojevic N, Gençay R, Kukolj D (2009) Option pricing with modular neural networks. IEEE T Neural Networ 20: 626–637. https://doi.org/10.1109/TNN.2008.2011130 doi: 10.1109/TNN.2008.2011130
|
| [33] |
Hamida SB, Cont R (2005) Recovering volatility from option prices by evolutionary optimization. J Comput Financ 8: 43–76. https://doi.org/10.21314/JCF.2005.130 doi: 10.21314/JCF.2005.130
|
| [34] |
He XJ, Lin S (2023a) Analytically pricing exchange options with stochastic liquidity and regime switching. J Futures Markets 43: 662–676. https://doi.org/10.1002/fut.22403 doi: 10.1002/fut.22403
|
| [35] |
He XJ, Lin S (2023b) A closed-form pricing formula for European options under a new three-factor stochastic volatility model with regime switching. Jpn J Ind Appl Math40: 525–536. https://doi.org/10.1007/s13160-022-00538-7 doi: 10.1007/s13160-022-00538-7
|
| [36] |
Hernandez A (2016) Model calibration with neural networks. Available at SSRN. https://doi.org/10.2139/ssrn.2812140 doi: 10.2139/ssrn.2812140
|
| [37] |
Heston SL (1993) A closed-form solution for options with stochastic volatility with applications to bond and currency options. Rev Financ Stud 6: 327–343. https://doi.org/10.1093/rfs/6.2.327 doi: 10.1093/rfs/6.2.327
|
| [38] |
Hornik K, Stinchcombe M, White H (1989) Multilayer feed-forward networks are universal approximators. Neural Networks. https://doi.org/10.1016/0893-6080(89)90020-8 doi: 10.1016/0893-6080(89)90020-8
|
| [39] |
Horvath B, Muguruza A, Tomas M (2021) Deep learning volatility: a deep neural network perspective on pricing and calibration in (rough) volatility models. Quant Financ 21: 11–27. https://doi.org/10.1080/14697688.2020.1817974 doi: 10.1080/14697688.2020.1817974
|
| [40] |
Hutchinson JM, Lo AW, Poggio T (1994) A nonparametric approach to pricing and hedging derivative securities via learning networks. J Financ 49: 851–889. https://doi.org/10.1111/j.1540-6261.1994.tb00081.x doi: 10.1111/j.1540-6261.1994.tb00081.x
|
| [41] |
Ikonen S, Toivanen J (2004) Operator splitting methods for American option pricing. Appl Math Lett 17: 104–126. https://doi.org/10.1016/j.aml.2004.06.010 doi: 10.1016/j.aml.2004.06.010
|
| [42] |
Ikonen S, Toivanen J (2007) Pricing American options using lu decomposition. Numer Meth Part D E 24: 104–126. https://doi.org/10.1016/j.aml.2004.06.010 doi: 10.1016/j.aml.2004.06.010
|
| [43] | Itkin A (2019) Deep learning calibration of option pricing models: some pitfalls and solutions. Working paper. |
| [44] | Kelly DL (1994) Valuing and hedging American put options using neural networks. Available from: http://moya.bus.miami.edu/dkelly/papers/options.pdf |
| [45] | Kingma DP, Ba J (2014) Adam: A method for stochastic optimization. Third International Conference For Learning Representations, San Diego. |
| [46] |
Kohler M, Krżyzak A, Todorovic N (2010) Pricing of high-dimensional American options by neural networks. Math Financ 20: 383–410. https://doi.org/10.1111/j.1467-9965.2010.00404.x doi: 10.1111/j.1467-9965.2010.00404.x
|
| [47] |
Krizhevsky A, Sutskever I, Hinton GE (2017) ImageNet classification with deep convolutional neural networks. Adv Neural Inf Processing Syst 25. https://doi.org/10.1145/3065386 doi: 10.1145/3065386
|
| [48] |
Lajbcygier PR, Connor JT (1997) Improved option pricing using artificial neural networks and bootstrap methods. Int J Neural Syst 8: 457–471. https://doi.org/10.1142/S0129065797000446 doi: 10.1142/S0129065797000446
|
| [49] |
Larguinho M, Dias JC, Braumann CA (2022) Pricing and hedging bond options and sinking-fund bonds under the CIR model. Quant Financ Econ 6: 1–34. https://doi.org/10.3934/QFE.2022001 doi: 10.3934/QFE.2022001
|
| [50] |
Lin S, He XJ (2023) Analytically pricing variance and volatility swaps with stochastic volatility, stochastic equilibrium level and regime switching. Expert Syst Appl 217: 119592. https://doi.org/10.1016/j.eswa.2023.119592 doi: 10.1016/j.eswa.2023.119592
|
| [51] |
Liu S, Borovykh A, Grzelak LA, et al. (2019a) A neural network-based framework for financial model calibration. J Math Ind 9. https://doi.org/10.1186/s13362-019-0066-7 doi: 10.1186/s13362-019-0066-7
|
| [52] |
Liu S, Oosterlee C, Bohte S (2019b) Pricing options and computing implied volatilities using neural networks. Risks 7: 1–22. https://doi.org/10.3390/risks7010016 doi: 10.3390/risks7010016
|
| [53] |
Longstaff FA, Schwartz ES (2001) Valuing American options by simulation: A simple least-squares approach. Rev Financ Stud 14: 113–147. https://doi.org/10.1093/rfs/14.1.113 doi: 10.1093/rfs/14.1.113
|
| [54] | Lu Z, Pu H, Wang F, et al. (2017) The expressive power of neural networks: A view from the width. NIPS 2017. |
| [55] |
Malliaris M, Salchenberger LM (1993) A neural network model for estimating option prices. Appl Intell 3: 193–206. https://doi.org/10.1007/BF00871937 doi: 10.1007/BF00871937
|
| [56] |
Maruyama G (1955) Continuous Markov processes and stochastic equations. Rendiconti del Circolo Matematico di Palermo 4: 276–292. https://doi.org/10.1007/BF02846028 doi: 10.1007/BF02846028
|
| [57] |
Meissner G, Kawano N (2001) Capturing the volatility smile of options on high-tech stocks—a combined GARCH-neural network approach. J Econ Financ 25: 276–292. https://doi.org/10.1007/BF02745889 doi: 10.1007/BF02745889
|
| [58] |
Morelli MJ, Montagna G, Nicrosini O, et al. (2004) Pricing financial derivatives with neural networks. Phys A 338: 160–165. https://doi.org/10.1016/j.physa.2004.02.038 doi: 10.1016/j.physa.2004.02.038
|
| [59] |
Pasricha P, He XJ (2023) Exchange options with stochastic liquidity risk. Expert Syst Appl 223: 119915. https://doi.org/10.1016/j.eswa.2023.119915 doi: 10.1016/j.eswa.2023.119915
|
| [60] | Pires MM, Marwala T (2004) American option pricing using multi-layer perceptron and support vector machine. In 2004 IEEE International Conference on Systems, Man and Cybernetics (IEEE Cat. No.04CH37583), 2: 1279–1285. |
| [61] |
Ruf J, and Wang W (2020) Neural networks for option pricing and hedging: A literature review. J Comput Financ 24: 1–45. https://doi.org/10.21314/JCF.2020.390 doi: 10.21314/JCF.2020.390
|
| [62] | Schoutens W (2003). Lévy processes in finance: pricing financial derivatives. Wiley. https://doi.org/10.1002/0470870230 |
| [63] | Shin HJ, Ryu J (2012) A dynamic hedging strategy for option transaction using artificial neural networks. Int J Software Eng Appl 6: 111–116. |
| [64] |
Spiegeleer JD, Madan DB, Reyners S, et al. (2018) Machine learning for quantitative finance: fast derivative pricing, hedging and fitting. Quant Financ 18: 1635–1643. https://doi.org/10.1080/14697688.2018.1495335 doi: 10.1080/14697688.2018.1495335
|
| [65] | Stinchcombe M, White H (1989) Universal approximation using feedforward networks with non-sigmoid hidden layer activation functions. Proceedings of the International Joint Conference on Neural Networks, 613–618. |
| [66] | Xie B, Li W, Liang N (2021) Pricing S & P 500 index options with Lévy jumps. arXiv preprint. |
| [67] |
Ye T, Zhang L (2019) Derivatives pricing via machine learning. J Math Financ 9: 561–589. https://doi.org/10.2139/ssrn.3352688 doi: 10.2139/ssrn.3352688
|
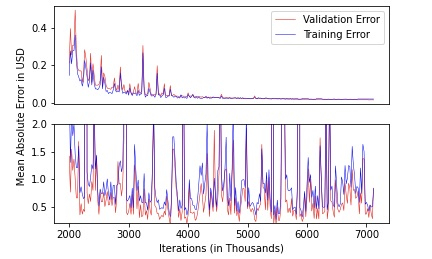
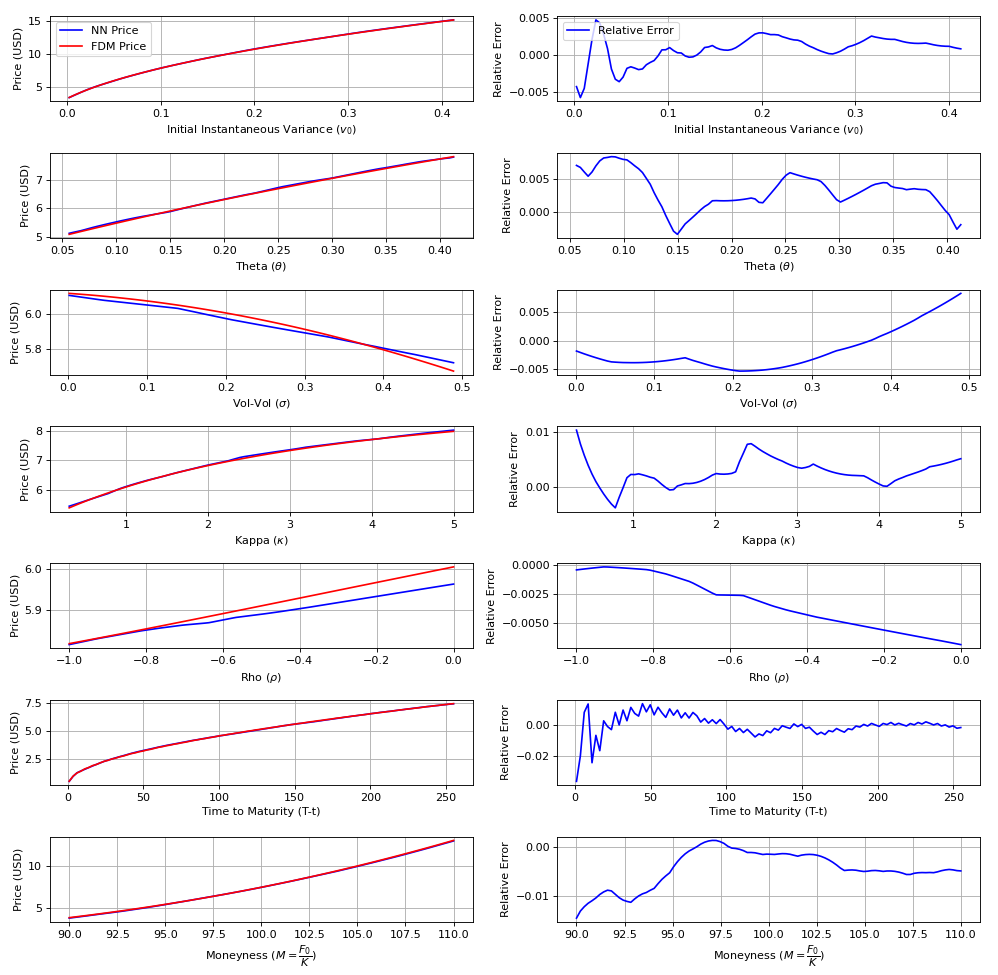
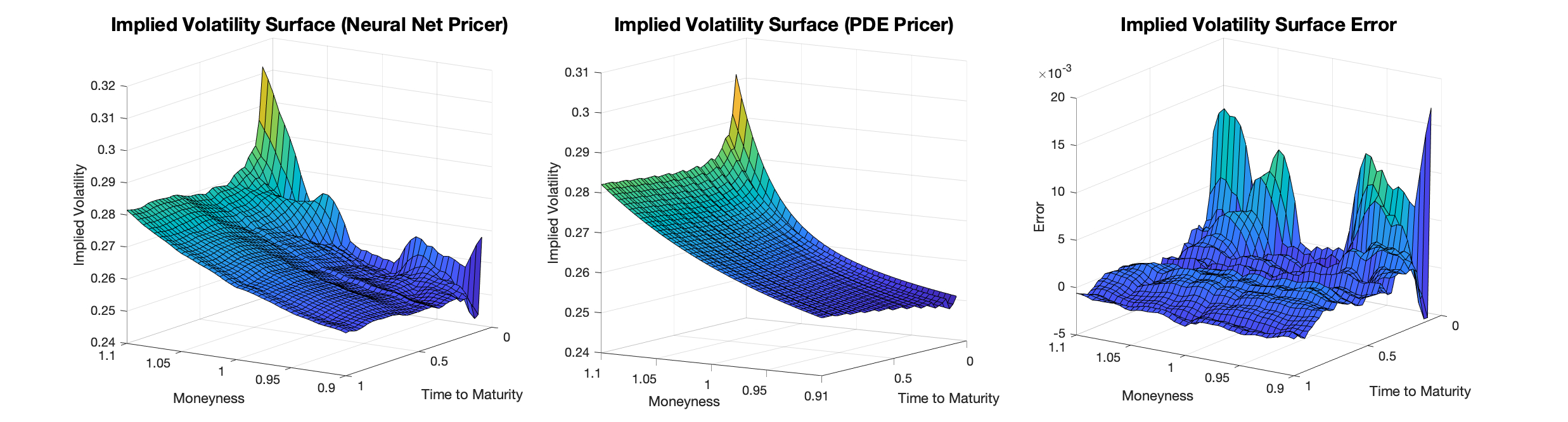
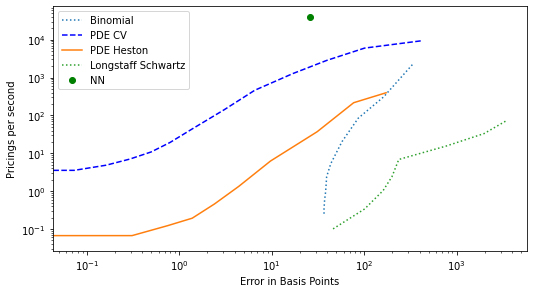
Figures(4) / Tables(4)

David Anderson, Urban Ulrych. Accelerated American option pricing with deep neural networks[J]. Quantitative Finance and Economics, 2023, 7(2): 207-228. doi: 10.3934/QFE.2023011







 DownLoad:
DownLoad: