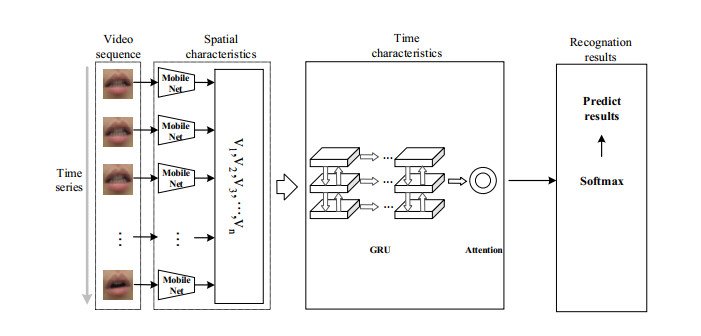
With the development of deep learning and artificial intelligence, the application of lip recognition is in high demand in computer vision and human-machine interaction. Especially, utilizing automatic lip recognition technology to improve performance during social interactions for those hard of hearing, and pronunciation is one of the most promising applications of artificial intelligence in medical healthcare and rehabilitation. Lip recognition means to recognize the content expressed by the speaker by analyzing dynamic motions. Presently, lip recognition research mainly focuses on the algorithms and computational performance, but there are relatively few research articles on its practical application. In order to amend that, this paper focuses on the research of a deep learning-based lip recognition application system, i.e., the design and development of a speech correction system for the hearing impaired, which aims to lay the foundation for the comprehensive implementation of automatic lip recognition technology in the future. First, we used a MobileNet lightweight network to extract spatial features from the original lip image; the extracted features are robust and fault-tolerant. Then, the gated recurrent unit (GRU) network was used to further extract the 2D image features and temporal features of the lip. To further improve the recognition rate, based on the GRU network, we incorporated an attention mechanism; the performance of this model is illustrated through a large number of experiments. Meanwhile, we constructed a lip similarity matching system to assist hearing-impaired people in learning and correcting their mouth shape with correct pronunciation. The experiments finally show that this system is highly feasible and effective.
Citation: Yuanyao Lu, Kexin Li. Research on lip recognition algorithm based on MobileNet + attention-GRU[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 13526-13540. doi: 10.3934/mbe.2022631
With the development of deep learning and artificial intelligence, the application of lip recognition is in high demand in computer vision and human-machine interaction. Especially, utilizing automatic lip recognition technology to improve performance during social interactions for those hard of hearing, and pronunciation is one of the most promising applications of artificial intelligence in medical healthcare and rehabilitation. Lip recognition means to recognize the content expressed by the speaker by analyzing dynamic motions. Presently, lip recognition research mainly focuses on the algorithms and computational performance, but there are relatively few research articles on its practical application. In order to amend that, this paper focuses on the research of a deep learning-based lip recognition application system, i.e., the design and development of a speech correction system for the hearing impaired, which aims to lay the foundation for the comprehensive implementation of automatic lip recognition technology in the future. First, we used a MobileNet lightweight network to extract spatial features from the original lip image; the extracted features are robust and fault-tolerant. Then, the gated recurrent unit (GRU) network was used to further extract the 2D image features and temporal features of the lip. To further improve the recognition rate, based on the GRU network, we incorporated an attention mechanism; the performance of this model is illustrated through a large number of experiments. Meanwhile, we constructed a lip similarity matching system to assist hearing-impaired people in learning and correcting their mouth shape with correct pronunciation. The experiments finally show that this system is highly feasible and effective.

| [1] | M. H. Rahmani, F. Almasganj, Lip-reading via a DNN-HMM hybrid system using combination of the image-based and model-based features, in 2017 3rd International Conference on Pattern Recognition and Image Analysis (IPRIA), (2017), 195–199. https://doi.org/10.1109/PRIA.2017.7983045 |
| [2] |
H. E. Cetingul, Y. Yemez, E. Erzin, A. M. Tekalp, Discriminative analysis of lip motion features for speaker identification and speech-reading, IEEE Trans. Image Process., 15 (2006), 2879–2891. https://doi.org/10.1109/TIP.2006.877528 doi: 10.1109/TIP.2006.877528

|
| [3] | A. B. Hassanat, Visual passwords using automatic lip reading, preprint, arXiv: 1409.0924. |
| [4] | Y. Zhang, Similarity image retrieval model based on local feature fusion and deep metric learning, in 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), (2020), 563–566. https://doi.org/10.1109/ITOEC49072.2020.9141871 |
| [5] | I. Matthews, G. Potamianos, C. Neti, J. Luettin, A comparison of model and transform-based visual features for audio-visual LVCSR, in Proceedings of the IEEE International Conference on Multimedia and Expo, ICME 2001, IEEE Computer Society, (2001), 825–828. https://doi.org/10.1109/ICME.2001.1237849 |
| [6] |
H. Ali, M. Hariharan, S. Yaacob, A. H. Adom, Hybrid feature extraction for facial emotion recognition, Int. J. Intell. Syst. Technol. Appl., 13 (2013), 202–221. https://doi.org/10.1504/IJISTA.2014.065175 doi: 10.1504/IJISTA.2014.065175
|
| [7] |
A. Rekik, A. Ben-Hamadou, W. Mahdi, An adaptive approach for lip-reading using image and depth data, Multimedia Tools Appl., 75 (2016), 8609–8636. https://doi.org/10.1007/s11042-015-2774-3 doi: 10.1007/s11042-015-2774-3
|
| [8] | K. Noda, Y. Yamaguchi, K. Nakadai, H. G. Okuno, T. Ogata, Lipreading using convolutional neural network, in fifteenth annual conference of the international speech communication association, 2014. https://doi.org/10.1016/j.jvlc.2014.09.005 |
| [9] | A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, et al., Mobilenets: efficient convolutional neural networks for mobile vision applications, preprint, arXiv: 1704.04861. https://doi.org/10.48550/arXiv.1704.04861 |
| [10] | J. Yang, P. Ren, D. Zhang, D. Chen, F. Wen, H. Li, et al., Neural aggregation network for video face recognition, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 5216–5225. https://doi.org/10.1109/CVPR.2017.554 |
| [11] | D. Lee, J. Lee, K. E. Kim, Multi-view automatic lip-reading using neural network, in Asian Conference on Computer Vision, Springer, Cham, (2016), 290–302. https://doi.org/10.1007/978-3-319-54427-4_22 |
| [12] |
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Comput., 9 (1997), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735 doi: 10.1162/neco.1997.9.8.1735
|
| [13] | A. Garg, J. Noyola, S. Bagadia, Lip reading using CNN and LSTM, in Technical report, Stanford University, CS231 n project report, 2016. |
| [14] | H. E. Romero, N. Ma, G. J. Brown, Snorer diarisation based on deep neural network embeddings, in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (2020), 876–880. https://doi.org/10.1109/ICASSP40776.2020.9053683 |
| [15] |
G. B. Zhou, J. Wu, C. L. Zhang, Z. H. Zhou, Minimal gated unit for recurrent neural networks, Int. J. Autom. Comput., 13 (2016), 226–234. https://doi.org/10.1007/s11633-016-1006-2 doi: 10.1007/s11633-016-1006-2
|
| [16] |
L. Li, W. Jia, J. Zheng, W Jian, Biomedical event extraction based on GRU integrating attention mechanism, BMC Bioinf., 19 (2018), 102–111. https://doi.org/10.1186/s12859-018-2275-2 doi: 10.1186/s12859-018-2275-2
|
| [17] | H. Liu, L. F. Li, W. L. Zhao, L. Chen, Rolling bearing fault diagnosis using improved LCD-TEO and softmax classifier, Vibroengineering Procedia, 5 (2015), 229–234. |
| [18] | C. Krishna, Face recognition based attendance management system using DLIB, Int. J. Eng. Adv. Technol., 8 (2019), 57–61. |
| [19] | S. Y. Nikouei, C. Yu, S. Song, R. Xu, T. R. Faughnan, Real-time human detection as an edge service enabled by a lightweight CNN, in 2018 IEEE International Conference on Edge Computing (EDGE), IEEE, (2018), 125–129. https://doi.org/10.1109/EDGE.2018.00025 |
| [20] | G. Hinton, O. Vinyals, J. Dean, Distilling the knowledge in a neural network, preprint, arXiv: 1503.02531. |
| [21] |
Y. Wei, Z. Yao, C. Lu, S. Wei, L. Liu, Z. Zhu, et al., Cross-modal retrieval with CNN visual features: a new baseline, IEEE Trans. Cybern., 47 (2017), 449–460. https://doi.org/10.1109/TCYB.2016.2519449 doi: 10.1109/TCYB.2016.2519449
|
| [22] |
M. Song, H. Park, K. Shin, Attention-based long short-term memory network using sentiment lexicon embedding for aspect-level sentiment analysis in Korean, Inf. Process. Manage., 56 (2018), 637–653. https://doi.org/10.1016/j.ipm.2018.12.005 doi: 10.1016/j.ipm.2018.12.005
|









Figures(10) / Tables(3)

Yuanyao Lu, Kexin Li. Research on lip recognition algorithm based on MobileNet + attention-GRU[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 13526-13540. doi: 10.3934/mbe.2022631







 DownLoad:
DownLoad: