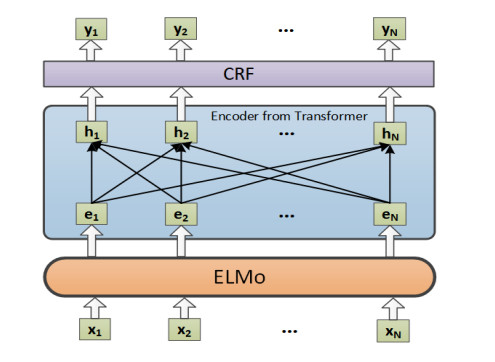
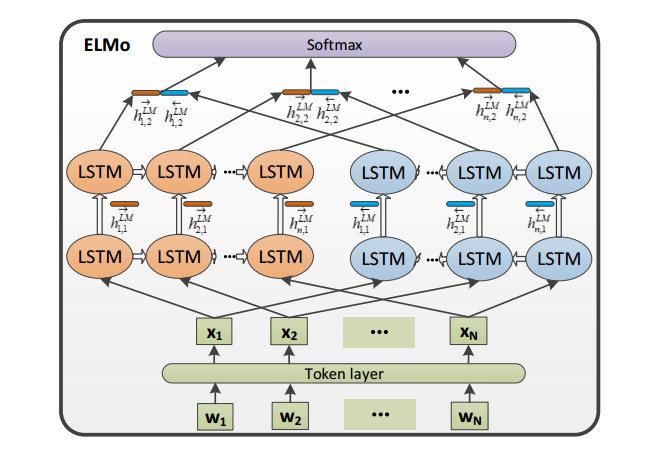
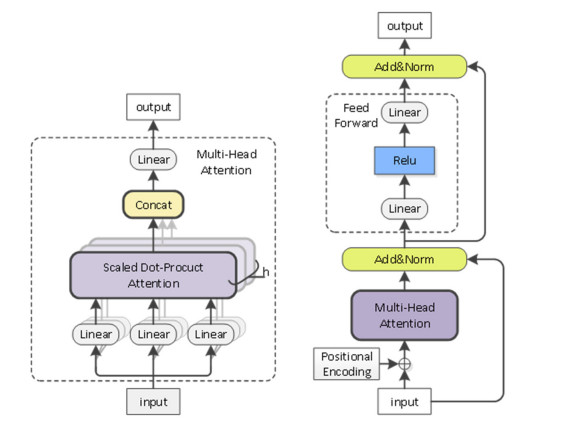
The combination of medical field and big data has led to an explosive growth in the volume of electronic medical records (EMRs), in which the information contained has guiding significance for diagnosis. And how to extract these information from EMRs has become a hot research topic. In this paper, we propose an ELMo-ET-CRF model based approach to extract medical named entity from Chinese electronic medical records (CEMRs). Firstly, a domain-specific ELMo model is fine-tuned on a common ELMo model with 4679 raw CEMRs. Then we use the encoder from Transformer (ET) as our model's encoder to alleviate the long context dependency problem, and the CRF is utilized as the decoder. At last, we compare the BiLSTM-CRF and ET-CRF model with word2vec and ELMo embeddings to CEMRs respectively to validate the effectiveness of ELMo-ET-CRF model. With the same training data and test data, the ELMo-ET-CRF outperforms all the other mentioned model architectures in this paper with 85.59% F1-score, which indicates the effectiveness of the proposed model architecture, and the performance is also competitive on the CCKS2019 leaderboard.
Citation: Qian Wan, Jie Liu, Luona Wei, Bin Ji. A self-attention based neural architecture for Chinese medical named entity recognition[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 3498-3511. doi: 10.3934/mbe.2020197
The combination of medical field and big data has led to an explosive growth in the volume of electronic medical records (EMRs), in which the information contained has guiding significance for diagnosis. And how to extract these information from EMRs has become a hot research topic. In this paper, we propose an ELMo-ET-CRF model based approach to extract medical named entity from Chinese electronic medical records (CEMRs). Firstly, a domain-specific ELMo model is fine-tuned on a common ELMo model with 4679 raw CEMRs. Then we use the encoder from Transformer (ET) as our model's encoder to alleviate the long context dependency problem, and the CRF is utilized as the decoder. At last, we compare the BiLSTM-CRF and ET-CRF model with word2vec and ELMo embeddings to CEMRs respectively to validate the effectiveness of ELMo-ET-CRF model. With the same training data and test data, the ELMo-ET-CRF outperforms all the other mentioned model architectures in this paper with 85.59% F1-score, which indicates the effectiveness of the proposed model architecture, and the performance is also competitive on the CCKS2019 leaderboard.

| [1] | B. Ji, R. Liu, S. Li, J. Yu, Q. Wu, Y. Tan, et al., A hybrid approach for named entity recognition in Chinese electronic medical record, BMC Med. Inform. Decis. Mak., 19 (2019), 64. |
| [2] | C. Zong, Statistical natural language process, Tsinghua University Press, 2013. |
| [3] |
J. Qiu, Y. Zhou, Q. Wang, T. Ruan, J. Gao, Chinese clinical named entity recognition using residual dilated convolutional neural network with conditional random field, IEEE Trans. Nanobiosci., 18 (2019), 306-315. doi: 10.1109/TNB.2019.2908678

|
| [4] | L. Li, L. Jin, Z. Jiang, D. Song, D. Huang, Biomedical named entity recognition based on extended recurrent neural networks, 2015 IEEE International Conference on bioinformatics and biomedicine, 2015. Available from: https://ieeexplore.ieee.org/abstract/document/7359761/. |
| [5] | R. Leaman, C. H. Wei, Z. Lu, tmChem: A high performance approach for chemical named entity recognition and normalization, J. Cheminf., 7 (2015), S3. |
| [6] | S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Comput., 9 (1997), 1735-1780. |
| [7] | S. Lai, L. Xu, K. Liu, J. Zhao, Recurrent convolutional neural networks for text classification, Twenty-ninth AAAI conference on artificial intelligence, 2015. Available from: https://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/viewPaper/9745. |
| [8] | T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space, arXiv preprint arXiv, 2013 (2013), 1301.3781. |
| [9] | M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, et al., Deep contextualized word representations, arXiv preprint arXiv, 2018 (2018), 1802.05365. |
| [10] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, Advances in neural information processing systems, 2017. Available from: http://papers.nips.cc/paper/7181-attention-is-all-you-need. |
| [11] | C. Lyu, B. Chen, Y. Ren, D. Ji, Long short-term memory RNN for biomedical named entity recognition, BMC Med. Inform. Decis. Mak., 18 (2017), 462. |
| [12] | G. K. Savova, J. J. Masanz, P. V. Ogren, J. Zheng, S. Sohn, K. C. Kipper-Schuler, et al., Mayo clinical text analysis and knowledge extraction system (cTAKES): Architecture, component evaluation and applications, J. Am. Med. Inf. Assoc., 17 (2010), 507-513. |
| [13] | G. Zhou, J. Su, Named entity recognition using an HMM-based chunk tagger, proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics, 2002. Available from: https://dl.acm.org/doi/10.3115/1073083.1073163. |
| [14] | M. Song, H. Yu, W. S. Han, Developing a hybrid dictionary-based bio-entity recognition technique, BMC Med. Inform. Decis. Mak., 15 (2015), S9. |
| [15] | A. McCallum, D. Freitag, F. C. Pereira, Maximum Entropy Markov Models for Information Extraction and Segmentation, LCML, 2000. Available from: http://cseweb.ucsd.edu/~elkan/254spring02/gidofalvi.pdf. |
| [16] | A. McCallum, W. Li, Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons, Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003-Volume 4, 2003. Available from: https://dl.acm.org/doi/10.3115/1119176.1119206. |
| [17] | M. Skeppstedt, M. Kvist, G. H. Nilsson, H. Dalianis, Automatic recognition of disorders, findings, pharmaceuticals and body structures from clinical text: An annotation and machine learning study, J. Biomed. Inform., 49 (2014), 148-158. |
| [18] | Z. Ju, J. Wang, F. Zhu, Named entity recognition from biomedical text using SVM, 2011 5th international conference on bioinformatics and biomedical engineering, 2011. Available from: https://ieeexplore.ieee.org/abstract/document/5779984/. |
| [19] | J. Pennington, R. Socher, C. Manning, Glove: Global vectors for word representation, Proceedings of the 2014 conference on empirical methods in natural language processing, 2014. Available from: https://www.aclweb.org/anthology/D14-1162.pdf. |
| [20] | R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, P. Kuksa, Natural language processing (almost) from scratch, J. Mach. Learn. Res., 12 (2011), 2493-2537. |
| [21] | Z. Huang, W. Xu, K. Yu, Bidirectional LSTM-CRF models for sequence tagging, arXiv preprint arXiv, 2015 (2015), 1508.01991. |
| [22] | G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, C. Dyer, Neural architectures for named entity recognition, arXiv preprint arXiv, 2016 (2016), 1603.01360. |
| [23] | X. Ma, E. Hovy, End-to-end sequence labeling via bi-directional lstm-cnns-crf, arXiv preprint arXiv, 2016 (2016), 1603.01354. |
| [24] | C. Dong, J. Zhang, C. Zong, M. Hattori, H. Di, Character-based LSTM-CRF with radical-level features for Chinese named entity recognition, in Natural Language Understanding and Intelligent Applications, Springer. (2016), 239-250. |
| [25] | J. L. Ba, J. R. Kiros, G. E. Hinton, Layer normalization, arXiv preprint arXiv, 2016 (2016), 1607.06450. |
| [26] | W. Che, Y. Liu, Y. Wang, B. Zheng, T. Liu, Towards better UD parsing: Deep contextualized word embeddings, ensemble, and treebank concatenation, arXiv preprint arXiv, 2018 (2018), 1807.03121. |
| [27] | A. Kutuzov, M. Fares, S. Oepen, E. Velldal, Word vectors, reuse, and replicability: Towards a community repository of large-text resources, Proceedings of the 58th Conference on Simulation and Modelling, 2017. Available from: https://www.duo.uio.no/handle/10852/65205. |
| [28] | Y. Zhang, J. Yang, Chinese ner using lattice lstm, arXiv preprint arXiv, 2018 (2018), 1805.02023. |
| [29] | Y. Zhu, G. Wang, CAN-NER: Convolutional attention network for Chinese named entity recognition, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019. Available from: https://www.aclweb.org/anthology/N19-1342.pdf. |
| [30] | Y. Liu, F. Meng, J. Zhang, J. Xu, Y. Chen, J. Zhou, Gcdt: A global context enhanced deep transition architecture for sequence labeling, arXiv preprint arXiv, 2019 (2019), 1906.02437. |

Figures(4) / Tables(6)

Qian Wan, Jie Liu, Luona Wei, Bin Ji. A self-attention based neural architecture for Chinese medical named entity recognition[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 3498-3511. doi: 10.3934/mbe.2020197







 DownLoad:
DownLoad: