Citation: Carlos Polanco, Vladimir N. Uversky, Manlio F. Márquez, Thomas Buhse, Miguel Arias Estrada, Alberto Huberman. Bioinformatics characterisation of the (mutated) proteins related to Andersen–Tawil syndrome[J]. Mathematical Biosciences and Engineering, 2019, 16(4): 2532-2548. doi: 10.3934/mbe.2019127

| [1] | A. H. Smith, F. A. Fish and P. J. Kannankeril, Andersen-Tawil syndrome. In. Pac. Electrophysiol. J., 6 (2006), 32–43. |
| [2] | V. Sansone and R. Tawil, Management, and treatment of Andersen–Tawil syndrome (ATS), Neurotherapeutics, 4 (2007), 233–237. |
| [3] | M. Tristani-Firouzi, J. L. Jensen and M. R. Donaldson, et al., Functional and clinical characterization of KCNJ2 mutations associated with LQT7 (Andersen syndrome), J. Clin. Invest., 110 (2002), 381–388. |
| [4] | S. Rajakulendran, S. V. Stan and M. G. Hanna, Muscle weakness, palpitations and a small chin: the Andersen–Tawil syndrome, Pract. Neurol., 10 (2010), 227–231. |
| [5] | G. M. Vincent, The Long QT Syndrome, In. Pac. Electrophysiol. J., 2 (2002), 127–142. |
| [6] | B. O. Choi, J. Kim, and B. C. Bsuh, et al., Mutations of KCNJ2 gene associated with Andersen–Tawil syndrome in Korean families, J. Hum. Genet., 52 (2007), 280–283. |
| [7] | M. R. Donaldson, J. L. Jensen and M. Tristani-Firouzi, et al., PIP2 binding residues of Kir2.1 are common targets of mutations causing Andersen syndrome, Neurology, 60 (2003), 1811–1816. |
| [8] | M. R. Donaldson, G. Yoon and Y. H. Fu, et al., Andersen–Tawil syndrome: a model of clinical variability, pleiotropy, and genetic heterogeneity, Ann. Med., 36 (2004), 92–97. |
| [9] | Y. Haruna, A. Kobori and T. Makiyama, et al., Genotype–phenotype correlations of KCNJ2 mutations in Japanese patients with Andersen–Tawil syndrome, Hum. Mutat., 28 (2007), 208. |
| [10] | N. M. Plaster, R. Tawil and M. Tristani-Firouzi, et al., Mutations in Kir2.1 cause the developmental and episodic electrical phenotypes of Andersen's syndrome, Cell, 105 (2001), 511–519. |
| [11] | L. Zhang, D. W. Benson and M. Tristani-Firouzi, et al., Electrocardiographic features in Andersen–Tawil syndrome patients with KCNJ2 mutations: characteristic T–U-wave patterns predict the KCNJ2 genotype, Circulation, 111 (2005), 272–276. |
| [12] | H. J. Jongsma and R. Wilders, Channelopathies: Kir2.1 mutations jeopardize many cell functions, Curr. Biol., 11 (2001), R747–R750. |
| [13] | H. L. Nguyen, G. H. Pieper and R. Wilders, Andersen–Tawil syndrome: clinical and molecular aspects, Int. J. Cardiol., 170 (2013), 1–16. |
| [14] | C. Polanco, Polarity index in Proteins-A Bioinformatics Tool, Bentham Science Publishers, Sharjah, U.A.E, 2016. |
| [15] | UniProt Consortium. UniProt: a hub for protein information. Nucleic Acids Res., 43 (2015), D204–D212. |
| [16] | A. S. Sheikh and K. Ranjan, Brugada syndrome: a review of the literature, Clin. Med. (Lond)., 14 (2014), 482–489. |
| [17] | G. Wang and X. Li, APD3: the antimicrobial peptide database as a tool for research and education, Nucleic Acids Res., 44 (2016), D1087–D1093. |
| [18] | A. Gautam, H. Singh and A. Tyagi, et al., CPPsite: a curated database of cell penetrating peptides. Database: the journal of biological databases and curation, (2012), bas015. |
| [19] | C. J. Oldfield, Y. Cheng and M. S. Cortese, et al., Comparing and combining predictors of mostly disordered proteins, Biochemistry, 44 (2005), 1989–2000. |
| [20] | C. J. Oldfield and A. L. Dunker, Intrinsically disordered proteins and intrinsically disordered protein regions, Ann. Rev. Biochem., 83 (2014), 553–584. |
| [21] | M. F. Márquez, A. Totomoch-Serra and G. Vargas-Alarcón, et al., Andersen-Tawil syndrome: a review of its clinical and genetic diagnosis with emphasis on cardiac manifestations, J. Arch. Cardiol. Mex., 84 (2014), 278–285. |
| [22] | A. De Biasio, C. Guarnaccia and M. Popovic, et al., Prevalence of intrinsic disorder in the intracellular region of human single-pass type I proteins: the case of the notch ligand Delta-4, J. Prot. Res., 7 (2008), 2496–2506. |
| [23] | S. Siegel, Estadística no paramétrica aplicada a las ciencias, Trillas, 155–165, (1985). |
| [24] | H. Grassmann, Extension theory. History of Mathematics, American Mathematical Society, (2000). |
| [25] | J. M. Chappell, A. Iqbal and L. J. Gunn, et al., Functions of Multivector Variables, PLoS ONE., 10 (2015), e0116943. |
| [26] | J. Pouget, A new type of periodic paralysis: Andersen–Tawil syndrome, Bull. Acad. Natl. Med., 192 (2008), 1551–1556. |
| [27] | S. Cagnin, E. Cimetta and C. Guiducci, et al., Overview of micro- and nano-technology tools for stem cell applications: micropatterned and microelectronic devices, Sensors (Basel)., 12 (2012) 15947–15982. |
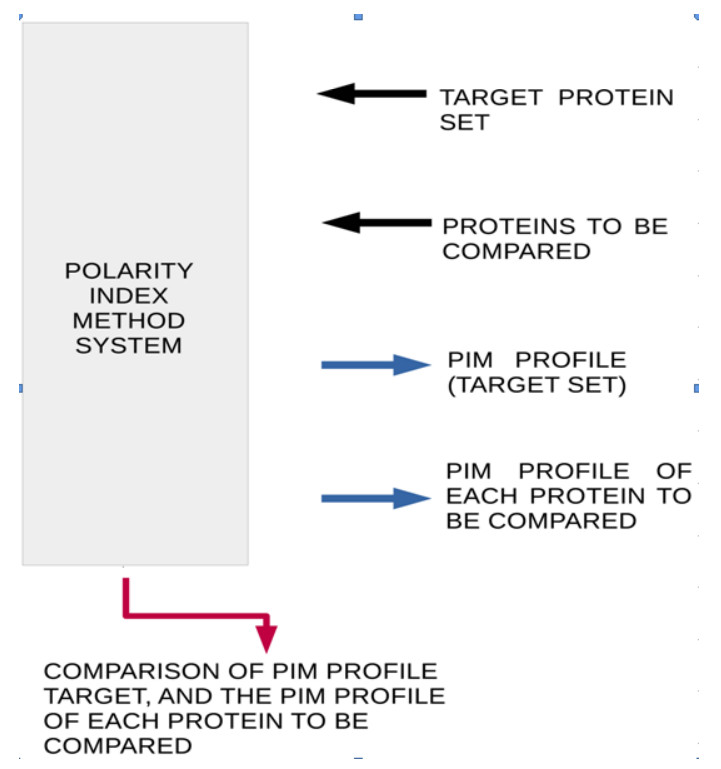
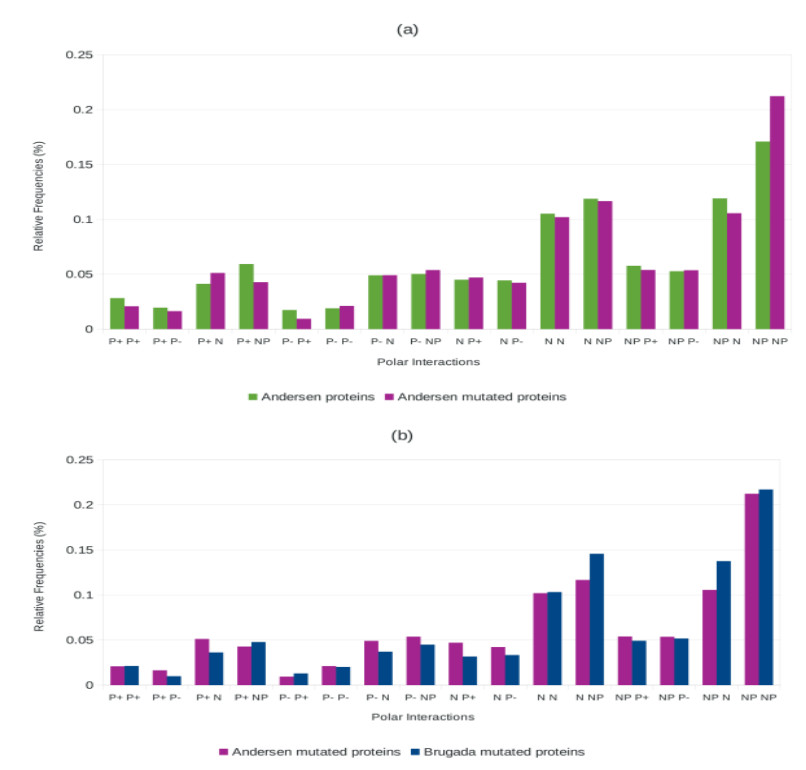
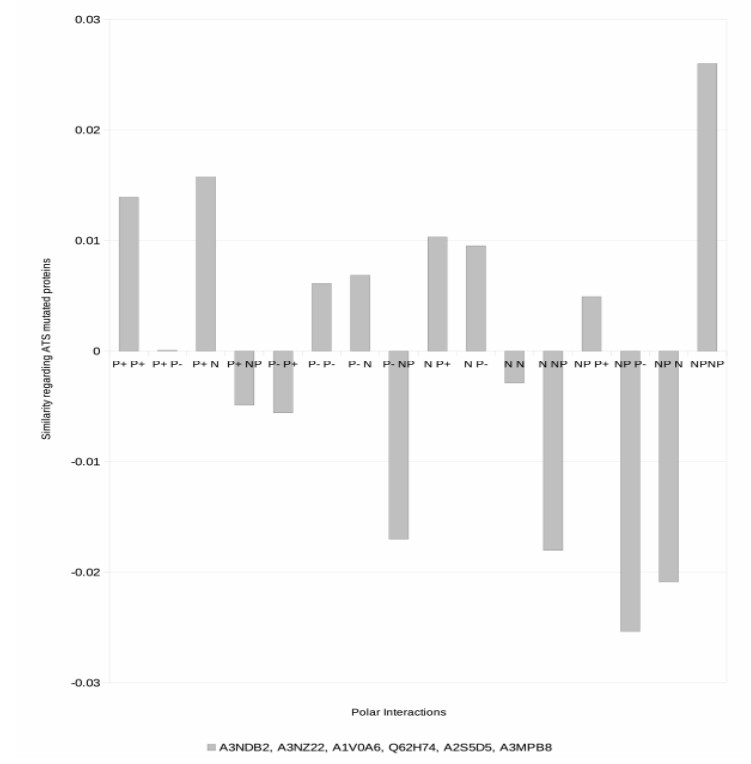
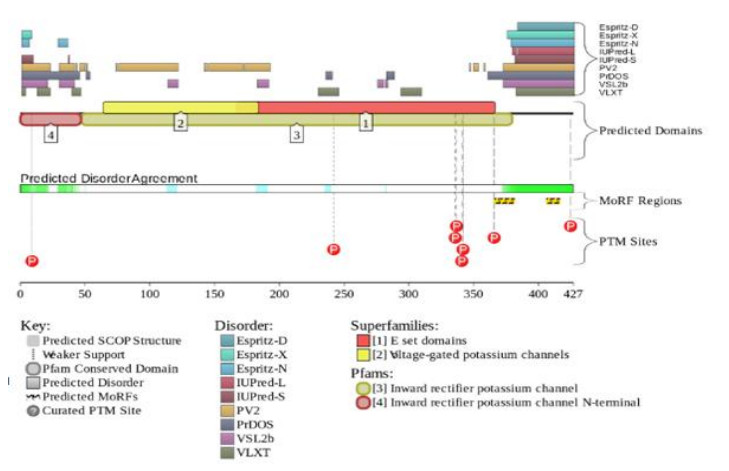
Figures(4) / Tables(3)

Carlos Polanco, Vladimir N. Uversky, Manlio F. Márquez, Thomas Buhse, Miguel Arias Estrada, Alberto Huberman. Bioinformatics characterisation of the (mutated) proteins related to Andersen–Tawil syndrome[J]. Mathematical Biosciences and Engineering, 2019, 16(4): 2532-2548. doi: 10.3934/mbe.2019127







 DownLoad:
DownLoad: