Citation: Md. Shaha Nur Kabir, Kamal Rasool, Wang-Hee Lee, Seong-In Cho, Sun-Ok Chung. Influence of delayed cooling on the quality of tomatoes (Solanum lycopersicum L.) stored in a controlled chamber[J]. AIMS Agriculture and Food, 2020, 5(2): 272-285. doi: 10.3934/agrfood.2020.2.272

| [1] |
Wilcox JK, Catignani GL, Lazarus S, et al. (2003) Tomatoes and cardiovascular health. Crit Rev Food Sci Nutr 43: 1-18. doi: 10.1080/10408690390826437

|
| [2] |
Ali A, Maqbool M, Ramachandran S, Alderson PG, et al. (2010) Gum Arabic as a novel edible coating for enhancing shelf life and improving postharvest quality of tomato (Solanum lycopersicum L.) fruit. Postharvest Biol Technol 58: 42-47. doi: 10.1016/j.postharvbio.2010.05.005
|
| [3] |
Arab L, Steck S (2000) Lycopene and cardiovascular disease. Am J Clin Nutr 71: 1691-1695. doi: 10.1093/ajcn/71.6.1691S
|
| [4] | Ali A, Magbool M, Alderson PG, Zahid N, et al. (2013) Effect of gum Arabic as an edible coating on antioxidant capacity of tomato (Solanum lycopersicum L.) fruit during storage. Postharvest Biol Technol 76: 119-124. |
| [5] | Thompson AK (2015) Fruit and vegetables: harvesting, handling and storage, 3 Eds., West Sussex: John Wiley & Sons, Ltd. |
| [6] | Arah IK, Ahorbo GK, Anku EK, Kumah EK, Amaglo H, et al. (2016) Postharvest handling practices and treatment methods for tomato handlers in developing countries: A mini review. Adv Agric 2016: 1-8. |
| [7] |
Lim BS, Lee JS, Park HJ, Oh SY, Chun JP, et al. (2016) Effects of ethylene treatment on postharvest quality in kiwi fruit. Korean j Agric Sci 43: 340-345. doi: 10.7744/kjoas.20160035
|
| [8] | Ben-Arie R, Lurie S (1986) Prolongation of fruit life after harvest. In: Monselise SP, Hand Book of Fruit Set and Development, Florida: CRC press, 493-520. |
| [9] |
Tolesa GN, Workneh TS (2017) Influence of storage environment, maturity stage and pre-storage disinfection treatments on tomato fruit quality during winter in KwaZulu-Natal, South Africa. J Food Sci Technol 54: 3230-3242. doi: 10.1007/s13197-017-2766-6
|
| [10] |
Tano K, Oulé MK, Doyon G, Lencki RW, Arul J, et al. (2007) Comparative evaluation of the effect of storage temperature fluctuation on modified atmosphere packages of selected fruit and vegetables. Postharvest Biol Technol 46: 212-221. doi: 10.1016/j.postharvbio.2007.05.008
|
| [11] |
Aghdam MS, Jannatizadeh A, Luo Z, Paliyath G, et al. (2018) Ensuring sufficient intracellular ATP supplying and friendly extracellular ATP signaling attenuates stresses, delays senescence and maintains quality in horticultural crops during postharvest life. Trends Food Sci. Technol 76: 67-81. doi: 10.1016/j.tifs.2018.04.003
|
| [12] | Roberts KP, Sargent SA, Fox AJ, et al. (2002) Effect of storage temperature on ripening and postharvest quality of grape and mini-pear tomatoes. Proceedings of the Florida State Horticultural Society, 115: 80-84. |
| [13] | Gharezi M, Joshi N, Sadeghian E, et al. (2012) Effect of postharvest treatment on stored cherry tomatoes. J Nutr Food Sci 2: 157. |
| [14] | Cantwell M (2001) Properties and recommended conditions for the long-term storage of fresh fruits and vegetables, Storage Recommendations. Davis: Department of Plant Sciences, University of California. |
| [15] | Suslow TV, Cantwell M (2000) Tomato: Recommendations for maintaining postharvest quality. Tomato Produce Facts, Postharvest Technology Center, Davis: University of California. |
| [16] | Arah IK, Amaglo H, Kumah EK, Ofori H, et al. (2015) Preharvest and postharvest factors affecting the quality and shelf life of harvested tomatoes: A mini review. Int J Agron 2015: 1-6. |
| [17] | Pila N, Gol NB, Rao TVR, et al. (2010) Effect of post-harvest treatments on physicochemical characteristics and shelf life of tomato (Lycopersicon esculentum Mill.) fruits during storage. American-Eurasian J Agric and Environ Sci 9: 470-479. |
| [18] |
Kusumaningrum D, Lee SH, Lee WH, Mo C, Cho BK, et al. (2015) A review of technologies to prolong the shelf life of fresh tropical fruits in Southeast Asia. J of Biosystems Eng 40: 345-358. doi: 10.5307/JBE.2015.40.4.345
|
| [19] | Kader AA (2005) Increasing food availability by reducing postharvest losses of fresh produce. Acta Horticulture 682: 2169-2175. |
| [20] | Wu CT (2010) An overview of postharvest biology and technology of fruits and vegetables. In: Huang CC, Proc. of the AARDO Workshop on Technology on Reducing Post-Harvest Losses and Maintaining Quality of Fruit and Vegetables 2010. Taiwan: Agricultural Research Institute, 2-11. |
| [21] | Kader AA, Stevens MA, Albright-Holton M, Morris LL, Algazi M, et al. (1977) Effect of fruit ripeness when picked on flavor and composition in fresh market tomatoes. J Am Soc Hortic Sci 102: 724-731. |
| [22] | Satyan SH, Patwardhan MV (1983) Organic acid metabolism during ripening of fruits. Indian J Biochem Biophys 20: 311-314. |
| [23] |
Barrett DM, Beaulieu JC, Shewfelt R, et al. (2010) Color, flavor, texture, and nutritional quality of fresh-cut fruits and vegetables: desirable levels, instrumental and sensory measurement, and the effects of processing. Crit Rev Food Sci Nutr 50: 369-389. doi: 10.1080/10408391003626322
|
| [24] | Simson SP, Straus MC (2010) Post-harvest technology of horticultural crops. Jaipur: Oxford Book Company, 249-302. |
| [25] |
Kim DG, Cho BK, Lee WH, et al. (2016) A novel approach in analyzing agriculture and food systems: Review of modeling and its applications. Korean j Agric Sci 43: 163-175. doi: 10.7744/kjoas.20160019
|
| [26] | Nirupama P, Gol NB, Rao TVR, et al. (2010) Effect of postharvest treatments on physicochemical characteristics and storage life of tomato (Lycopersicon esculentum Mill.) fruits during storage. Am Eurasian J Agric Environ Sci 9: 470-479. |
| [27] |
Gormley RS, Egan S (1978) Firmness and colour of the fruit of some tomato cultivars from various sources during storage. J Sci Food Agric 29: 534-538. doi: 10.1002/jsfa.2740290607
|
| [28] | Choi IL, Yoo TJ, Jung HJ, Kim IS, Kang HM, Lee YB, et al. (2011) Effects of active modified atmosphere packaging on the storability of fresh-cut Paprika. J Bio-Environ Control 20: 227-232. |
| [29] | Khairi AN, Falah MAF, Suyantohadi A, Takahashi N, Nishina H, et al. (2015) Effect of storage temperatures on color of tomato fruit (Solanum lycopersicum Mill.) cultivated under moderate water stress treatment. Agric Agric Sci Procedia 3: 178-183. |
| [30] | Pinheiro J, Alegria C, Abreu M, Gonçalves EM, Silva CLM, et al. (2013) Kinetics of changes in the physical quality parameters of fresh tomato fruits (Solanum lycopersicum, cv. 'Zinac') during storage. J Food Eng 114: 338-345. |
| [31] | Žnidarčič D, Ban D, Oplanić M, Karić L, Požrl T, et al. (2010) Influence of postharvest temperatures on physicochemical quality of tomatoes (Lycopersicon esculentum Mill.). J Food Agric Environ 8: 21-25. |
| [32] | Guillén F, Castillo S, Zapata PJ, Martínez-Romero D, Serrano M, Valero D, et al. (2007) Efficacy of 1-MCP treatment in tomato fruit. 1. Duration and concentration of 1-MCP treatment to gain an effective delay of postharvest ripening. Postharvest Biol Technol 43: 23-27. |
| [33] | Moneruzzaman KM, Hossain ABMS, Sani W, Saifuddin M, Alenazi M, et al. (2009) Effect of harvesting and storage conditions on the post-harvest quality of tomato (Lycopersicon esculentum Mill) cv. Roma VF. Aust J Crop Sci 3: 113-121. |
| [34] |
Li L, Lichter A, Kenigsbuch D, Porat R, et al. (2015) Effects of cooling delays at the wholesale market on the quality of fruit and vegetables after retail marketing. J Food Process Pres 39: 2533-2547. doi: 10.1111/jfpp.12504
|
| [35] | Madani B, Mirshekari A, Imahori Y, et al. (2019) Physiological responses to stress. In: Yahia EM, Carrillo-López A, Postharvest Physiology and Biochemistry of Fruits and Vegetables, Massachusetts: Woodhead Publishing, 405-423. |
| [36] |
Batu A (2004) Determination of acceptable firmness and colour values of tomatoes. J Food Eng 61: 471-475. doi: 10.1016/S0260-8774(03)00141-9
|
| [37] |
Lana MM, Tijskens LMM, Kooten O, et al. (2005) Effects of storage temperature and fruit ripening on firmness of fresh cut tomatoes. Postharvest Biol Technol 35: 87-95. doi: 10.1016/j.postharvbio.2004.07.001
|
| [38] |
Majidi H, Minaei S, Almasi M, Mostofi Y, et al. (2014) Tomato quality in controlled atmosphere storage, modified atmosphere packaging and cold storage. J Food Sci Technol 51: 2155-2161. doi: 10.1007/s13197-012-0721-0
|
| [39] |
Mahmood A, Hu Y, Tanny J, Asante EA, et al. (2018) Effects of shading and insect-proof screens on crop microclimate and production: A review of recent advances. Sci Hrotic 241: 241-251. doi: 10.1016/j.scienta.2018.06.078
|
| [40] |
Tigist M, Workneh TS, Woldetsadik K, et al. (2013) Effects of variety on the quality of tomato stored under ambient conditions. J Food Sci Technol 50: 477-486. doi: 10.1007/s13197-011-0378-0
|
| [41] | Majidi H, Minaei S, Almasi M, Mostofi Y, et al. (2011) Total soluble solids, titratable acidity and repining index of tomato in various storage conditions. Aust J Basic & Appl Sci 5: 1723-1726. |
| [42] | Guillén F, Castillo S, Zapata PJ, Martínez-Romero D, Valero D, Serrano M, et al. (2006) Efficacy of 1-MCP treatment in tomato fruit. 2-Effect of cultivar and ripening stage at harvest. Postharvest Biol Technol 42: 235-242. |
| [43] |
Zapata PJ, Guillén F, Martínez-Romero D, Castillo S, Valero D, Serrano M, et al. (2008) Use of alginate or zein as edible coatings to delay postharvest ripening process and to maintain tomato (Solanum lycopersicon Mill.) quality. J Sci Food Agric 88: 1287-1293. doi: 10.1002/jsfa.3220
|
| [44] | Gould WA (1992) Tomato production, processing and technology. Maryland: CTI Publications Inc. |
| [45] |
Luengwilai K, Tananuwong K, Shoemaker CF, Beckles DM, et al. (2010) Starch molecular structure shows little association with fruit physiology and starch metabolism in tomato. J Agric Food Chem 58: 1275-1282. doi: 10.1021/jf9032393
|
| [46] | Gautier H, Lopez-Lauri F, Massot C, Murshed R, Marty I, Grasselly D, Keller C, Sallanon H, Genard M, et al. (2010) Impact of ripening and salinity on tomato fruit ascorbate content and enzymatic activities related to ascorbate recycling. Funct Plant Sci Biotechnol 4: 66-75. |
| [47] |
Beckles DM (2012) Factors affecting the postharvest soluble solids and sugar content of tomato (Solanum lycopersicum L.) fruit: Review. Postharvest Biol Technol 63: 129-140. doi: 10.1016/j.postharvbio.2011.05.016
|
| [48] | Renquist AR, Reid JB (1998) Quality of processing tomato (Lycopersicon esculentum) fruit from four bloom dates in relation to optimal harvest timing. N Z J Crop Hortic Sci 26: 61-168. |
| [49] |
Campbell AD, Huysamer M, Stotz HU, Greve LC, Labavitch JM, et al. (1990) Comparison of ripening processes in intact tomato fruit and excised pericarp discs. Plant Physiol 94: 1582-1589. doi: 10.1104/pp.94.4.1582
|
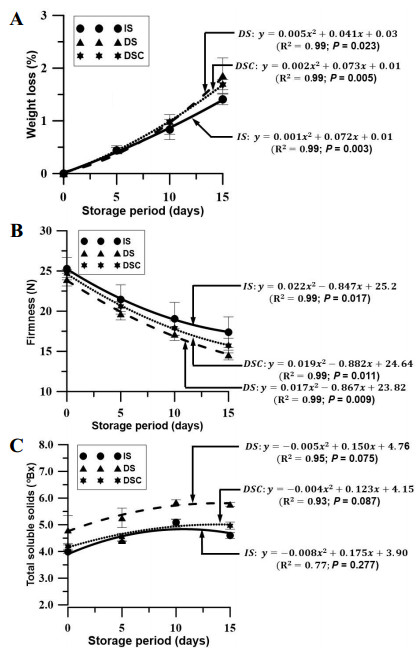
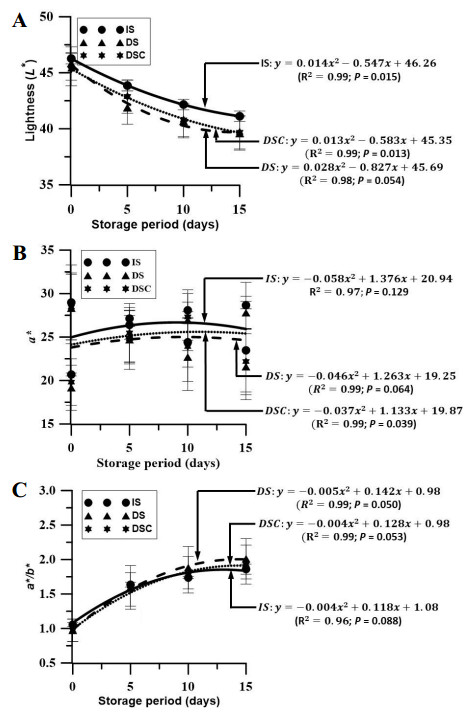
Figures(2) / Tables(3)

Md. Shaha Nur Kabir, Kamal Rasool, Wang-Hee Lee, Seong-In Cho, Sun-Ok Chung. Influence of delayed cooling on the quality of tomatoes (Solanum lycopersicum L.) stored in a controlled chamber[J]. AIMS Agriculture and Food, 2020, 5(2): 272-285. doi: 10.3934/agrfood.2020.2.272







 DownLoad:
DownLoad: