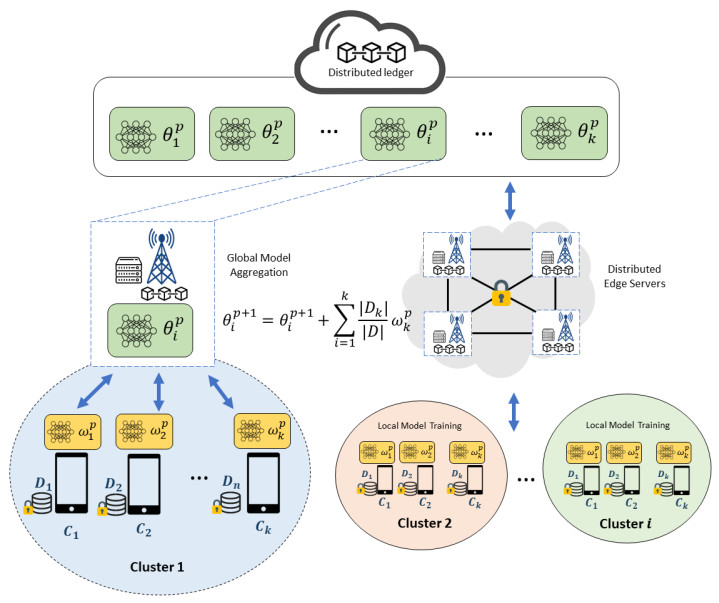
Federated learning (FL) is a distributed machine learning technique that allows multiple devices (e.g., smartphones and IoT devices) to collaborate in the training of a shared model with each device preserving the privacy of its local data. However, the highly heterogeneous distribution of data among clients in FL can result in poor convergence. In addressing this issue, the concept of personalized federated learning (PFL) has emerged. PFL aims to tackle the effects of non-independent and identically distributed data and statistical heterogeneity and to achieve personalized models with rapid model convergence. One approach is clustering-based PFL, which utilizes group-level client relationships to achieve personalization. However, this method still relies on a centralized approach, whereby the server coordinates all processes. To address these shortcomings, this study introduces a blockchain-enabled distributed edge cluster for PFL (BPFL) that combines the benefits of blockchain and edge computing. Blockchain technology can be used to enhance client privacy and security by recording transactions on immutable distributed ledger networks, thereby improving client selection and clustering. The edge computing system offers reliable storage and computation such that computational processing is locally performed in the edge infrastructure to be closer to clients. Thus, the real-time services and low-latency communication of PFL are improved. However, further work is required to develop a representative dataset for the examination of related types of attacks and defenses for a robust BPFL protocol.
Citation: Muhammad Firdaus, Siwan Noh, Zhuohao Qian, Harashta Tatimma Larasati, Kyung-Hyune Rhee. Personalized federated learning for heterogeneous data: A distributed edge clustering approach[J]. Mathematical Biosciences and Engineering, 2023, 20(6): 10725-10740. doi: 10.3934/mbe.2023475
Federated learning (FL) is a distributed machine learning technique that allows multiple devices (e.g., smartphones and IoT devices) to collaborate in the training of a shared model with each device preserving the privacy of its local data. However, the highly heterogeneous distribution of data among clients in FL can result in poor convergence. In addressing this issue, the concept of personalized federated learning (PFL) has emerged. PFL aims to tackle the effects of non-independent and identically distributed data and statistical heterogeneity and to achieve personalized models with rapid model convergence. One approach is clustering-based PFL, which utilizes group-level client relationships to achieve personalization. However, this method still relies on a centralized approach, whereby the server coordinates all processes. To address these shortcomings, this study introduces a blockchain-enabled distributed edge cluster for PFL (BPFL) that combines the benefits of blockchain and edge computing. Blockchain technology can be used to enhance client privacy and security by recording transactions on immutable distributed ledger networks, thereby improving client selection and clustering. The edge computing system offers reliable storage and computation such that computational processing is locally performed in the edge infrastructure to be closer to clients. Thus, the real-time services and low-latency communication of PFL are improved. However, further work is required to develop a representative dataset for the examination of related types of attacks and defenses for a robust BPFL protocol.

| [1] |
P. Voigt, A. Von dem Bussche, The eu general data protection regulation (gdpr), A Practical Guide, 1st Ed., Cham: Springer International Publishing, 10 (2017), 5510–5555. https://doi.org/10.1007/978-3-319-57959-7 doi: 10.1007/978-3-319-57959-7

|
| [2] |
G. J. Annas, Hipaa regulations: a new era of medical-record privacy?, New England J. Med., 348 (2003), 1486. https://doi.org/10.1056/NEJMlim035027 doi: 10.1056/NEJMlim035027
|
| [3] | A. Hard, K. Rao, R. Mathews, S. Ramaswamy, F. Beaufays, S. Augenstein, Het al., Federated learning for mobile keyboard prediction, preprint, arXiv: 1811.03604. |
| [4] |
N. Rieke, J. Hancox, W. Li, F. Milletari, H. R. Roth, S. Albarqouni, et al., The future of digital health with federated learning, NPJ Dig. Med., 3 (2020), 119. https://doi.org/10.1038/s41746-020-00323-1 doi: 10.1038/s41746-020-00323-1
|
| [5] |
X. Wang, S. Garg, H. Lin, G. Kaddoum, J. Hu, M. S. Hossain, A secure data aggregation strategy in edge computing and blockchain-empowered internet of things, IEEE Int. Things J., 9 (2020), 14237–14246. https://doi.org/10.1109/JIOT.2020.3023588 doi: 10.1109/JIOT.2020.3023588
|
| [6] |
X. Wang, S. Garg, H. Lin, G. Kaddoum, J. Hu, M. M. Hassan, Heterogeneous blockchain and ai-driven hierarchical trust evaluation for 5g-enabled intelligent transportation systems, IEEE Trans. Intell. Transp. Syst., 24 (2021), 2074–2083. https://doi.org/10.1109/TITS.2021.3129417 doi: 10.1109/TITS.2021.3129417
|
| [7] | G. Long, Y. Tan, J. Jiang, C. Zhang, Federated learning for open banking, in Federated Learning: Privacy and Incentive, (2020), 240–254. https://doi.org/10.1007/978-3-030-63076-8_17 |
| [8] | B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A. y Arcas, Communication-efficient learning of deep networks from decentralized data, in Artificial intelligence and statistics, (2017), 1273–1282. |
| [9] | V. Smith, C. K. Chiang, M. Sanjabi, A. S. Talwalkar, Federated multi-task learning, in Advances in neural information processing systems, (2017). |
| [10] |
F. Sattler, K. R. Müller, W. Samek, Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints, IEEE Trans. Neural Networks Learning Syst., 32 (2020), 3710–3722. https://doi.org/10.1109/TNNLS.2020.3015958 doi: 10.1109/TNNLS.2020.3015958
|
| [11] | Y. C. Hu, M. Patel, D. Sabella, N. Sprecher, V. Young, Mobile edge computing—a key technology towards 5g, ETSI White Paper, 11 (2015), 1–16. |
| [12] |
E. Fazeldehkordi, T. M. Grønli, A survey of security architectures for edge computing-based iot, IoT, 3 (2022), 332–365. https://doi.org/10.3390/iot3030019 doi: 10.3390/iot3030019
|
| [13] |
K. Cao, Y. Liu, G. Meng, Q. Sun, An overview on edge computing research, IEEE Access, 8 (2020), 85714–85728. https://doi.org/10.1109/ACCESS.2020.2991734 doi: 10.1109/ACCESS.2020.2991734
|
| [14] |
K. B. Letaief, Y. Shi, J. Lu, J. Lu, Edge artificial intelligence for 6g: Vision, enabling technologies, and applications, IEEE J. Selected Areas Commun., 40 (2021), 5–36. https://doi.org/10.1109/JSAC.2021.3126076 doi: 10.1109/JSAC.2021.3126076
|
| [15] |
E. Kristiani, Y. T. Tsan, P. Y. Liu, N. Y. Yen, C. T. Yang, Binary and multi-class assessment of face mask classification on edge ai using cnn and transfer learning, Human Centric Comput. Inf. Sci., 12 (2022). https://doi.org/10.22967/HCIS.2022.12.053 doi: 10.22967/HCIS.2022.12.053
|
| [16] |
M. Babar, M. S. Khan, U. Habib, B. Shah, F. Ali, D. Song, Scalable edge computing for iot and multimedia applications using machine learning, Human centric Comput. Inf. Sci., 11 (2021). https://doi.org/10.22967/hcis.2021.11.041 doi: 10.22967/hcis.2021.11.041
|
| [17] |
B. He, T. Li, An offloading scheduling strategy with minimized power overhead for internet of vehicles based on mobile edge computing, J. Inf. Process. Syst., 17 (2021), 489–504. https://doi.org/10.3745/JIPS.01.0077 doi: 10.3745/JIPS.01.0077
|
| [18] |
Y. He, Z. Tang, Strategy for task offloading of multi-user and multi-server based on cost optimization in mobile edge computing environment, J. Inf. Process. Syst., 17 (2021), 615–629. https://doi.org/10.3745/JIPS.01.0078 doi: 10.3745/JIPS.01.0078
|
| [19] |
Z. Zhou, X. Chen, E. Li, L. Zeng, K. Luo, J. Zhang, Edge intelligence: Paving the last mile of artificial intelligence with edge computing, Proc. IEEE, 107 (2019), 1738–1762. https://doi.org/10.1109/JPROC.2019.2918951 doi: 10.1109/JPROC.2019.2918951
|
| [20] | X. Zhu, H. Li, Y. Yu, Blockchain-based privacy preserving deep learning, in International Conference on Information Security and Cryptology, (2018), 370–383. https://doi.org/10.1007/978-3-030-14234-6_20 |
| [21] |
T. S. Brisimi, R. Chen, T. Mela, A. Olshevsky, I. C. Paschalidis, W. Shi, Federated learning of predictive models from federated electronic health records, Int. J. Med. Inf., 112 (2018), 59–67. https://doi.org/10.1016/j.ijmedinf.2018.01.007 doi: 10.1016/j.ijmedinf.2018.01.007
|
| [22] | S. Samarakoon, M. Bennis, W. Saad, M. Debbah, Federated learning for ultra-reliable low-latency v2v communications, in 2018 IEEE Global Communications Conference (GLOBECOM), (2018), 1–7. https://doi.org/10.1109/GLOCOM.2018.8647927 |
| [23] | M. Chen, R. Mathews, T. Ouyang, F. Beaufays, Federated learning of out-of-vocabulary words, preprint, arXiv: 1903.10635. |
| [24] | S. P. Karimireddy, S. Kale, M. Mohri, S. J. Reddi, S. U. Stich, A. T. Suresh, Scaffold: Stochastic controlled averaging for federated learning, in International Conference on Machine Learning, (2020), 5132–5143. |
| [25] | T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, V. Smith, Federated optimization in heterogeneous networks, in Proceedings of Machine learning and systems, (2020), 429–450. |
| [26] | J. Wang, Q. Liu, H. Liang, G. Joshi, H. V. Poor, Tackling the objective inconsistency problem in heterogeneous federated optimization, in Advances in neural information processing systems, (2020), 7611–7623. |
| [27] | M. Firdaus, K. H Rhee, A joint framework to privacy-preserving edge intelligence in vehicular networks, in Information Security Applications: 23rd International Conference, WISA 2022, Cham: Springer Nature Switzerland, (2023), 156–167. https://doi.org/10.1007/978-3-031-25659-2_12 |
| [28] |
J. S. P. G. M. Nam, J. G. Shon, A blockchain-based cheating detection system for online examination, KIPS Trans. Software Data Eng., 11 (2022), 267–272. https://doi.org/10.3745/KTSDE.2022.11.6.267 doi: 10.3745/KTSDE.2022.11.6.267
|
| [29] |
A. Z. Tan, H. Yu, L. Cui, Q. Yang, Towards personalized federated learning, IEEE Trans. Neural Networks Learn. Syst., (2022), 1–17. https://doi.org/10.1109/TNNLS.2022.3160699 doi: 10.1109/TNNLS.2022.3160699
|
| [30] | K. C. Sim, P. Zadrazil, F. Beaufays, An investigation into on-device personalization of end-to-end automatic speech recognition models, preprint, arXiv: 1909.06678. |
| [31] | V. Kulkarni, M. Kulkarni, A. Pant, Survey of personalization techniques for federated learning, in 2020 Fourth World Conference on Smart Trends in Systems, Security and Sustainability (WorldS4), (2020), 794–797. https://doi.org/10.1109/WorldS450073.2020.9210355 |
| [32] | Y. Jiang, J. Konečnỳ, K. Rush, S. Kannan, Improving federated learning personalization via model agnostic meta learning, preprint, arXiv: 1909.12488. |
| [33] | Y. Zhao, M. Li, L. Lai, N. Suda, D. Civin, V. Chandra, Federated learning with non-iid data, preprint, arXiv: 1806.00582. |
| [34] |
Y. Chen, X. Qin, J. Wang, C. Yu, W. Gao, Fedhealth: A federated transfer learning framework for wearable healthcare, IEEE Intell. Syst., 35 (2020), 83–93. https://doi.org/10.1109/MIS.2020.2988604 doi: 10.1109/MIS.2020.2988604
|
| [35] |
Y. Tian, T. Li, J. Xiong, M. Z. A. Bhuiyan, J. Ma, C. Peng, A blockchain-based machine learning framework for edge services in iiot, IEEE Trans. Ind. Inf., 18 (2021), 1918–1929. https://doi.org/10.1109/TII.2021.3097131 doi: 10.1109/TII.2021.3097131
|
| [36] |
J. Weng, J. Weng, J. Zhang, M. Li, Y. Zhang, W. Luo, Deepchain: Auditable and privacy-preserving deep learning with blockchain-based incentive, IEEE Trans. Dependable Secure Comput., 18 (2019), 2438–2455. https://doi.org/10.1109/TDSC.2019.2952332 doi: 10.1109/TDSC.2019.2952332
|
| [37] | Y. Huang, L. Chu, Z. Zhou, L. Wang, J. Liu, J. Pei, et al., Personalized cross-silo federated learning on non-iid data, in Proceedings of the AAAI Conference on Artificial Intelligence, (2021), 7865–7873. https://doi.org/10.1609/aaai.v35i9.16960 |
| [38] |
X. Wang, S. Garg, H. Lin, M. J. Piran, J. Hu, M. S. Hossain, Enabling secure authentication in industrial iot with transfer learning empowered blockchain, IEEE Trans. Ind. Inf., 17 (2021), 7725–7733. https://doi.org/10.1109/TII.2021.3049405 doi: 10.1109/TII.2021.3049405
|
| [39] |
Y. LeCun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proc. IEEE, 86 (1998), 2278–2324. https://doi.org/10.1109/5.726791 doi: 10.1109/5.726791
|
| [40] | M. Firdaus, H. T. Larasati, K. H. Rhee, A secure federated learning framework using blockchain and differential privacy, in 2022 IEEE 9th International Conference on Cyber Security and Cloud Computing (CSCloud)/2022 IEEE 8th International Conference on Edge Computing and Scalable Cloud (EdgeCom), (2022), 18–23. |




Figures(5) / Tables(1)

Muhammad Firdaus, Siwan Noh, Zhuohao Qian, Harashta Tatimma Larasati, Kyung-Hyune Rhee. Personalized federated learning for heterogeneous data: A distributed edge clustering approach[J]. Mathematical Biosciences and Engineering, 2023, 20(6): 10725-10740. doi: 10.3934/mbe.2023475







 DownLoad:
DownLoad: