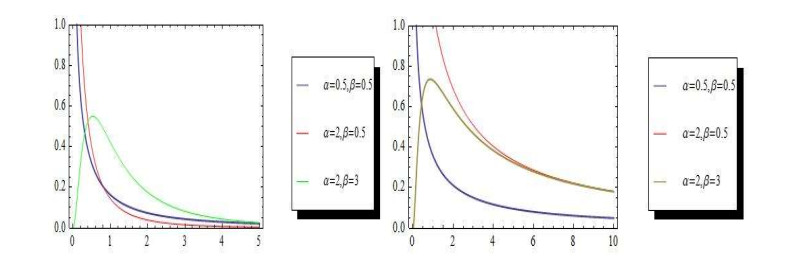
This article discusses the problem of estimation with step stress partially accelerated life tests using Type-II progressively censored samples. The lifetime of items under use condition follows the two-parameters inverted Kumaraswamy distribution. The maximum likelihood estimates for the unknown parameters are computed numerically. Using the property of asymptotic distributions for maximum likelihood estimation, we constructed asymptotic interval estimates. The Bayes procedure is used to calculate estimates of the unknown parameters from symmetrical and asymmetric loss functions. The Bayes estimates cannot be obtained explicitly, therefor the Lindley's approximation and the Markov chain Monte Carlo technique are used to obtaining the Bayes estimates. Furthermore, the highest posterior density credible intervals for the unknown parameters are calculated. An example is presented to illustrate the methods of inference. Finally, a numerical example of March precipitation (in inches) in Minneapolis failure times in the real world is provided to illustrate how the approaches will perform in practice.
Citation: Manal M. Yousef, Rehab Alsultan, Said G. Nassr. Parametric inference on partially accelerated life testing for the inverted Kumaraswamy distribution based on Type-II progressive censoring data[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 1674-1694. doi: 10.3934/mbe.2023076
This article discusses the problem of estimation with step stress partially accelerated life tests using Type-II progressively censored samples. The lifetime of items under use condition follows the two-parameters inverted Kumaraswamy distribution. The maximum likelihood estimates for the unknown parameters are computed numerically. Using the property of asymptotic distributions for maximum likelihood estimation, we constructed asymptotic interval estimates. The Bayes procedure is used to calculate estimates of the unknown parameters from symmetrical and asymmetric loss functions. The Bayes estimates cannot be obtained explicitly, therefor the Lindley's approximation and the Markov chain Monte Carlo technique are used to obtaining the Bayes estimates. Furthermore, the highest posterior density credible intervals for the unknown parameters are calculated. An example is presented to illustrate the methods of inference. Finally, a numerical example of March precipitation (in inches) in Minneapolis failure times in the real world is provided to illustrate how the approaches will perform in practice.

| [1] |
E. K. Al-Hussaini, A. H. Abdel-Hamid, Bayesian estimation of the parameters, reliability and hazard rate functions of mixtures under accelerated life tests, Commun. Stat. Simul. Comput., 33 (2004), 963–982. https://doi.org/10.1081/SAC-200040703 doi: 10.1081/SAC-200040703

|
| [2] |
E. K. Al-Hussaini, A. H. Abdel-Hamid, Accelerated life tests under finite mixture models, J. Stat. Comput. Simul., 76 (2006), 673–690. https://doi.org/10.1080/10629360500108087 doi: 10.1080/10629360500108087
|
| [3] |
A. M. Abd-Elfattah, A. S. Hassan, S. G. Nassr, Estimation in step-stress partially accelerated life tests for the Burr type XⅡ distribution using type I censoring, Stat. Methodol., 5 (2008), 502–514. https://doi.org/10.1016/j.stamet.2007.12.001 doi: 10.1016/j.stamet.2007.12.001
|
| [4] |
M. M. Mohie El-Din, S. E. Abu-Youssef, N. S. A. Ali, A. M. Abd El-Raheem, Estimation in step-stress accelerated life tests for Weibull distribution with progressive first-failure censoring, J. Stat. Appl. Probab., 3 (2015), 403–411. http://dx.doi.org/10.1155/2015/319051 doi: 10.1155/2015/319051
|
| [5] |
A. E. B. A. Ahmad, A. A. Soliman, M. M. Yousef, Bayesian Bayesian estimation of exponentiated Weibull distribution under partially accelerated life tests, Bull. Malays. Math. Sci. Soc., 39 (2016), 227–244. https://doi.org/10.1007/s40840-015-0170-9 doi: 10.1007/s40840-015-0170-9
|
| [6] |
A. A. Ismail, Likelihood Inference for a step stress partially accelerated life test model with type-I progressive hybrid censored data from Weibull distribution, J. Stat. Comput. Simul., 84 (2016), 2486–2494. https://doi.org/10.1080/00949655.2013.836195 doi: 10.1080/00949655.2013.836195
|
| [7] |
B. Liu, Y. Shi, J. Cai, R. Wang, Reliability analysis of masked data in adaptive step-stress partially accelerated lifetime tests with progressive removal, Commun. Stat. Theory Methods, 46 (2017), 6174–6191. https://doi.org/10.1080/03610926.2015.1122058 doi: 10.1080/03610926.2015.1122058
|
| [8] | S. A. Lone, A. Rahman, A. Islam, Step stress partially accelerated life testing plan for competing risk using adaptive Type-I progressive hybrid censoring, Pak. J. Stat., 33 (2017), 237–248. |
| [9] |
M. Nassar, S. G. Nassr, S. Dey, Analysis of Burr type XⅡ distribution under step stress partially accelerated life tests with Type I and adaptive Type Ⅱ progressively hybrid censoring schemes, Ann. Data Sci., 4 (2017), 227–248. https://doi.org/10.1007/s40745-017-0101-8 doi: 10.1007/s40745-017-0101-8
|
| [10] |
S. G. Nassr, N. Elharoun, Inference for exponentiated Weibull distribution under constant stress partially accelerated life tests with multiple censored, Commun. Stat. Appl. Methods, 26 (2019), 131–148. https://doi.org/10.29220/CSAM.2019.26.2.131 doi: 10.29220/CSAM.2019.26.2.131
|
| [11] |
A. S. Hassan, S. G. Nassr, S. Pramanik, S. S. Maiti, Estimation in constant stress partially accelerated life tests for Weibull distribution based on censored competing risks data, Ann. Data Sci., 7 (2020), 45–62. https://doi.org/10.1007/s40745-019-00226-3 doi: 10.1007/s40745-019-00226-3
|
| [12] |
Ç. ÇETİNKAYA, Estimation in step-stress partially accelerated life tests for the power Lindley distribution under progressive censoring, Gazi Univ. J. Sci., 34 (2021), 579–590. https://doi.org/10.35378/gujs.682499 doi: 10.35378/gujs.682499
|
| [13] |
I. Alam, A. Ahmed, Inference on maintenance service policy under step-stress partially accelerated life tests using progressive censoring, J. Stat. Comput. Simul., 92 (2022), 813–829. https://doi.org/10.1080/00949655.2021.1975282 doi: 10.1080/00949655.2021.1975282
|
| [14] |
Y. Wang, W. Wang, Y. Tang, A Bayesian semiparametric accelerate failure time mixture cure model, Int. J. Biostat., 2021 (2021). https://doi.org/10.1515/ijb-2021-0012 doi: 10.1515/ijb-2021-0012
|
| [15] |
A. Xu, S. Zhou, Y. Tang, A unified model for system reliability evaluation under dynamic operating conditions, IEEE Trans. Reliab., 70 (2019), 65–72. https://doi.org/10.1109/TR.2019.2948173 doi: 10.1109/TR.2019.2948173
|
| [16] |
C. Luo, L. Shen, A. Xu, Modelling and estimation of system reliability under dynamic operating environments and lifetime ordering constraints, Reliab. Eng. Syst. Saf., 218 (2022), 108136. https://doi.org/10.1016/j.ress.2021.108136 doi: 10.1016/j.ress.2021.108136
|
| [17] |
M. M. Yousef, S. A. Alyami, A. F. Hashem, Statistical inference for a constant-stress partially accelerated life tests based on progressively hybrid censored samples from inverted Kumaraswamy distribution, PloS One, 17 (2022), e0272378. https://doi.org/10.1371/journal.pone.0272378 doi: 10.1371/journal.pone.0272378
|
| [18] | N. Balakrishnan, R. Aggarwala, Progressive Censoring: Theory, Methods, and Applications, Birkhauser, Boston, 2000. |
| [19] | N. Balakrishnan, E. Cramer, The Art of Progressive Censoring, Birkhauser, New York, 2014. https://doi.org/10.1007/978-0-8176-4807-7 |
| [20] |
F. Zhang, X. Shi, H. K. T. Ng, Information geometry of the exponential family of distributions with progressive Type-Ⅱ censoring, Entropy, 23 (2021), 687. https://doi.org/10.3390/e23060687 doi: 10.3390/e23060687
|
| [21] |
S. Dey, A. Elshahhat, Analysis of Wilson‐Hilferty distribution under progressive Type‐Ⅱ censoring, Qual. Reliab. Eng. Int., 2022 (2022). https://doi.org/10.1002/qre.3173 doi: 10.1002/qre.3173
|
| [22] | A. M. Abd AL-Fattah, A. A. EL-Helbawy, G. R. AL-Dayian, Inverted Kumaraswamy distribution: Properties and estimation, Pak. J. Stat., 33 (2017), 37–61. |
| [23] |
M. Mohie El-Din, M. Abu-Moussa, On estimation and prediction for the inverted Kumaraswamy distribution based on general progressive censored samples, Pak. J. Stat. Oper. Res., 14 (2018), 717–736. https://doi.org/10.18187/pjsor.v14i3.2103 doi: 10.18187/pjsor.v14i3.2103
|
| [24] |
A. M. Daghistani, B. Al-Zahrani, M. Q. Shahbaz, Relations for moments of dual generalized order statistics for a new inverse Kumaraswamy distribution, Pak. J. Stat. Oper. Res., 15 (2019), 989–997. https://doi.org/10.18187/pjsor.v15i4.3079 doi: 10.18187/pjsor.v15i4.3079
|
| [25] |
K. Bagci, T. Arslan, H. E. Celik, Inverted Kumarswamy distribution for modeling the wind speed data: Lake Van, Turkey, Renewable Sustainable Energy Rev., 135 (2021), 110110. https://doi.org/10.1016/j.rser.2020.110110 doi: 10.1016/j.rser.2020.110110
|
| [26] |
F. Noor, S. Masood, M. Zaman, M. Siddiqa, R. A. Wagan, I. U. Khan, et al., Bayesian analysis of inverted Kumaraswamy mixture model with application to burning velocity of chemicals, Math. Prob. Eng., 2021 (2021). https://doi.org/10.1155/2021/5569652 doi: 10.1155/2021/5569652
|
| [27] | V. Bagdonavicius, M. Nikulin, Accelerated Life Models: Modeling and Statistical Analysis. Chapman and Hall/CRC Press, Boca Raton, Florida, 2021. |
| [28] | H. R. Varian, A Bayesian approach to real estate assessment, in Variants in Economic Theory: Selected Works of H. R. Varian, Edward Elgar Publishing, (2000), 144–155. |
| [29] |
M. Doostparast, S. Deepak, A. Zangoie, Estimation with the lognormal distribution on the basis of records, J. Stat. Comput. Simul., 83 (2013), 2339–2351. https://doi.org/10.1080/00949655.2012.691973 doi: 10.1080/00949655.2012.691973
|
| [30] |
D. V. Lindley, Approximate Bayesian methods, Trabajos de Estadistica y de investigacin operativa, 31 (1980), 223–245. https://doi.org/10.1007/BF02888353 doi: 10.1007/BF02888353
|
| [31] |
M. Doostparast, M. G. Akbari, N. Balakrishna, Bayesian analysis for the two-parameter Pareto distribution based on record values and times, J. Stat. Comput. Simul., 81 (2011), 1393–1403. https://doi.org/10.1080/00949655.2010.486762 doi: 10.1080/00949655.2010.486762
|
| [32] | N. Balakrishnan, R. A. Sandhu, A simple simulational algorithm for generating progressive Type-Ⅱ censored samples, Am. Stat., 49 (1985), 229–230. |
| [33] |
D. Hinkley, On quick choice of power transformations, J. R. Stat. Ser. C, 26 (1977), 67–69. https://doi.org/10.2307/2346869 doi: 10.2307/2346869
|
| [34] | M. H. Chen, Q. M. Shao, Monte Carlo estimation of Bayesian credible and HPD intervals, J. Comput. Graphical Stat., 8 (1999), 69–92. |







Figures(8) / Tables(11)

Manal M. Yousef, Rehab Alsultan, Said G. Nassr. Parametric inference on partially accelerated life testing for the inverted Kumaraswamy distribution based on Type-II progressive censoring data[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 1674-1694. doi: 10.3934/mbe.2023076







 DownLoad:
DownLoad: