Private Set Intersection (PSI), which is a hot topic in recent years, has been extensively utilized in credit evaluation, medical system and so on. However, with the development of big data era, the existing traditional PSI cannot meet the application requirements in terms of performance and scalability. In this work, we proposed two secure and effective PSI (SE-PSI) protocols on scalable datasets by leveraging deterministic encryption and Bloom Filter. Specially, our first protocol focuses on high efficiency and is secure under a semi-honest server, while the second protocol achieves security on an economic-driven malicious server and hides the set/intersection size to the server. With experimental evaluation, our two protocols need only around 15 and 24 seconds respectively over one million-element datasets. Moreover, as a novelty, a multi-round mechanism is proposed for the two protocols to improve the efficiency. The implementation demonstrates that our two-round mechanism can enhance efficiency by almost twice than two basic protocols.
Citation: Shuo Qiu, Zheng Zhang, Yanan Liu, Hao Yan, Yuan Cheng. SE-PSI: Fog/Cloud server-aided enhanced secure and effective private set intersection on scalable datasets with Bloom Filter[J]. Mathematical Biosciences and Engineering, 2022, 19(2): 1861-1876. doi: 10.3934/mbe.2022087
Private Set Intersection (PSI), which is a hot topic in recent years, has been extensively utilized in credit evaluation, medical system and so on. However, with the development of big data era, the existing traditional PSI cannot meet the application requirements in terms of performance and scalability. In this work, we proposed two secure and effective PSI (SE-PSI) protocols on scalable datasets by leveraging deterministic encryption and Bloom Filter. Specially, our first protocol focuses on high efficiency and is secure under a semi-honest server, while the second protocol achieves security on an economic-driven malicious server and hides the set/intersection size to the server. With experimental evaluation, our two protocols need only around 15 and 24 seconds respectively over one million-element datasets. Moreover, as a novelty, a multi-round mechanism is proposed for the two protocols to improve the efficiency. The implementation demonstrates that our two-round mechanism can enhance efficiency by almost twice than two basic protocols.

| [1] |
Q. Tang, Public key encryption supporting plaintext equality test and user-specified authorization, Secur. Commun. Networks, 5 (2012), 1351–1362. doi: 10.1002/sec.418. doi: 10.1002/sec.418

|
| [2] | D. Kales, C. Rechberger, T. Schneider, M. Senker, C. Weinert, Mobile private contact discovery at scale, in 28th USENIX Security Symposium (USENIX Security 19), (2019), 1447–1464. |
| [3] | P. Baldi, R. Baronio, E. De Cristofaro, P. Gasti, G. Tsudik, Countering gattaca: Efficient and secure testing of fully-sequenced human genomes, in Proceedings of the 18th ACM Conference on Computer and Communications Security, (2011), 697–702. doi: 10.1145/2046707.2046785. |
| [4] | M. Ion, B. Kreuter, E. Nergiz, S. Patel, S. Saxena, K. Seth, et al., Private intersection-sum protocol with applications to attributing aggregate ad conversions, IACR Cryptol. ePrint Arch., (2017), 738. |
| [5] |
E. D. Cristofaro, G. Tsudik, Practical private set intersection protocols with linear complexity, Lect. Notes Comput. Sci., 6052 (2010), 143–159. doi: 10.1007/978-3-642-14577-3_13. doi: 10.1007/978-3-642-14577-3_13
|
| [6] | C. Dong, L. Chen, Z. Wen, When private set intersection meets big data: An efficient and scalable protocol, in Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, (2013), 789–800. doi: 10.1145/2508859.2516701. |
| [7] |
S. Qiu, J. Liu, Y. Shi, Identity-based symmetric private set intersection, Wuhan Univ. J. Nat. Sci., 19 (2014), 426–432. doi: 10.1007/s11859-014-1035-z. doi: 10.1007/s11859-014-1035-z
|
| [8] | B. Pinkas, M. Rosulek, N. Trieu, A. Yanai, Spot-light: Lightweight private set intersection from sparse ot extension, Annu. Int. Cryptology Conf., (2019), 401–431. doi: 10.1007/978-3-030-26954-8_13. |
| [9] | M. Chase, P. Miao, Private set intersection in the internet setting from lightweight oblivious prf, Lect. Notes Comput. Sci., Springer, 12172 (2020), 34–63. doi: 10.1007/978-3-030-56877-1_2. |
| [10] |
S. Kamara, P. Mohassel, M. Raykova, S. Sadeghian, Scaling private set intersection to billion-element sets, Financ. Cryptography Data Secur., 8437 (2014), 195–215. doi: 10.1007/978-3-662-45472-5_13. doi: 10.1007/978-3-662-45472-5_13
|
| [11] |
E. Zhang, F. Li, B. Niu, Y. Wang, Server-aided private set intersection based on reputation, Inf. Sci., 387 (2017), 180–194. doi: 10.1016/j.ins.2016.09.056. doi: 10.1016/j.ins.2016.09.056
|
| [12] |
H. Liu, H. Zhang, L. Guo, J. Yu, J. Lin, Privacy-preserving cloud-aided broad learning system, Comput. Secur., 112 (2022), 102503. doi: 10.1016/j.cose.2021.102503. doi: 10.1016/j.cose.2021.102503
|
| [13] | T. Wang, J. Zhou, X. Chen, G. Wang, A. Liu, Y. Liu, A three-layer privacy preserving cloud storage scheme based on computational intelligence in fog computing, in IEEE Transactions on Emerging Topics in Computational Intelligence, 2 (2018), 3–12. doi: 10.1109/TETCI.2017.2764109. |
| [14] |
H. Zhang, J. Yu, C. Tian, G. Xu, J. Lin, Practical and secure outsourcing algorithms for solving quadratic congruences in internet of things, IEEE Int. Things J., 7 (2020), 2968–2981. doi: 10.1109/JIOT.2020.2964015. doi: 10.1109/JIOT.2020.2964015
|
| [15] | H. Zhang, J. Yu, M. S. Obaidat, P. Vijayakumar, R. Hao, Secure edge-aided computations for social internet-of-things systems, IEEE Trans. Comput. Soc. Syst., (2020), 1–12. doi: 10.1109/TCSS.2020.3030904. |
| [16] | A. Abadi, S. Terzis, C. Dong, Feather: lightweight multi-party updatable delegated private set intersection, IACR Cryptol. ePrint Arch, 2021. |
| [17] |
A. Abadi, S. Terzis, R. Metere, C. Dong, Efficient delegated private set intersection on outsourced private datasets, IEEE Trans. Dependable Secure Comput., 16 (2017), 608–624. doi: 10.1109/TDSC.2017.2708710. doi: 10.1109/TDSC.2017.2708710
|
| [18] | A. Kavousi, J. Mohajeri, M. Salmasizadeh, Improved secure efficient delegated private set intersection, in 2020 28th Iranian Conference on Electrical Engineering, (2020), 1–6. doi: 10.1109/ICEE50131.2020.9260663. |
| [19] | L. Tajan, D. Westhoff, F. Armknecht, Private set relations with bloom filters for outsourced sla validation, IACR Cryptol. ePrint Arch., (2019), 993. |
| [20] |
M. J. Freedman, K. Nissim, B. Pinkas, Efficient private matching and set intersection, Lect. Notes Comput. Sci., 3027 (2004), 1–19. doi: 10.1007/978-3-540-24676-3_1. doi: 10.1007/978-3-540-24676-3_1
|
| [21] |
S. Ghosh, M. Simkin, The communication complexity of threshold private set intersection, Lect. Notes Comput. Sci., 11693 (2019), 3–29. doi: 10.1007/978-3-030-26951-7_1. doi: 10.1007/978-3-030-26951-7_1
|
| [22] |
C. Hazay, Oblivious polynomial evaluation and secure set-intersection from algebraic prfs, J. Cryptol., 31 (2018), 537–586. doi: 10.1007/s00145-017-9263-y. doi: 10.1007/s00145-017-9263-y
|
| [23] | A. Kavousi, J. Mohajeri, M. Salmasizadeh, Efficient scalable multi-party private set intersection using oblivious prf., Secur. Trust Manage., (2021), 81–99. doi: 10.1007/978-3-030-91859-0_5. |
| [24] | P. Rindal, M. Rosulek, Improved private set intersection against malicious adversaries, in Annual International Conference on the Theory and Applications of Cryptographic Techniques, (2017), 235–259. doi: 10.1007/978-3-319-56620-7_9. |
| [25] | B. Pinkas, T. Schneider, O. Tkachenko, A. Yanai, Efficient circuit-based psi with linear communication, in Annual International Conference on the Theory and Applications of Cryptographic Techniques, (2019), 122–153. doi: 10.1007/978-3-030-17659-4_5. |
| [26] | B. Pinkas, T. Schneider, C. Weinert, U. Wieder, Efficient circuit-based psi via cuckoo hashing, in Annual International Conference on the Theory and Applications of Cryptographic Techniques, (2018), 125–157. doi: 10.1007/978-3-319-78372-7_5. |
| [27] | M. Ciampi, C. Orlandi, Combining private set-intersection with secure two-party computation, Lect. Notes Comput. Sci., Springer, 11035 (2018), 464–482. doi: 10.1007/978-3-319-98113-0_25. |
| [28] |
G. Garimella, B. Pinkas, M. Rosulek, N. Trieu, A. Yanai, Oblivious key-value stores and amplification for private set intersection, Lect. Notes Comput. Sci., 12826 (2021), 395–425. doi: 10.1007/978-3-030-84245-1_14. doi: 10.1007/978-3-030-84245-1_14
|
| [29] |
B. Pinkas, T. Schneider, M. Zohner, Scalable private set intersection based on ot extension, ACM Trans. Priv. Secur., 21 (2018), 1–35. doi: 10.1145/3154794. doi: 10.1145/3154794
|
| [30] |
M. Ali, J. Mohajeri, M. R. Sadeghi, X. Liu, Attribute-based fine-grained access control for outscored private set intersection computation, Inf. Sci., 536 (2020), 222–243. doi: 10.1016/j.ins.2020.05.041. doi: 10.1016/j.ins.2020.05.041
|
| [31] |
C. Dong, L. Chen, J. Camenisch, G. Russello, Fair private set intersection with a semi-trusted arbiter, Lect. Notes Comput. Sci., 7964 (2013), 128–144. doi: 10.1007/978-3-642-39256-6_9. doi: 10.1007/978-3-642-39256-6_9
|
| [32] | H. Chen, K. Laine, P. Rindal, Fast private set intersection from homomorphic encryption, in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, (2017), 1243–1255. doi: 10.1145/3133956.3134061. |
| [33] | S. K. Debnath, R. Dutta, Secure and efficient private set intersection cardinality using bloom filter, Lect. Notes Comput. Sci., Springer, 9290 (2015), 209–226. doi: 10.1007/978-3-319-23318-5_12. |
| [34] | D. Stritzl, Privacy-Preserving Matching Using Bloom Filters: An Analysis And An Encrypted Variant, Master's thesis, University of Twente, 2019. |
| [35] | H. Carter, B. Mood, P. Traynor, K. Butler, Outsourcing secure two-party computation as a black box, 2016. doi: 10.1002/sec.1486. |
| [36] | O. Goldreich, Foundations of cryptography: volume 2, basic applications, Cambridge University Press, 2004. |
| [37] | J. Katz, Y. Lindell, Introduction to Modern Cryptography, CRC Press, 2007. |



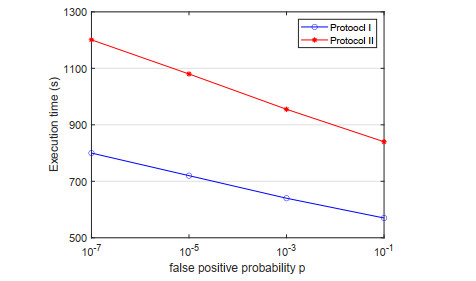
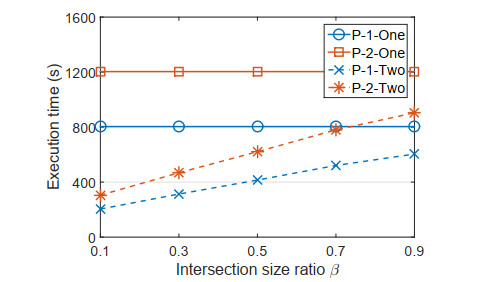
Figures(5) / Tables(3)

Shuo Qiu, Zheng Zhang, Yanan Liu, Hao Yan, Yuan Cheng. SE-PSI: Fog/Cloud server-aided enhanced secure and effective private set intersection on scalable datasets with Bloom Filter[J]. Mathematical Biosciences and Engineering, 2022, 19(2): 1861-1876. doi: 10.3934/mbe.2022087







 DownLoad:
DownLoad: