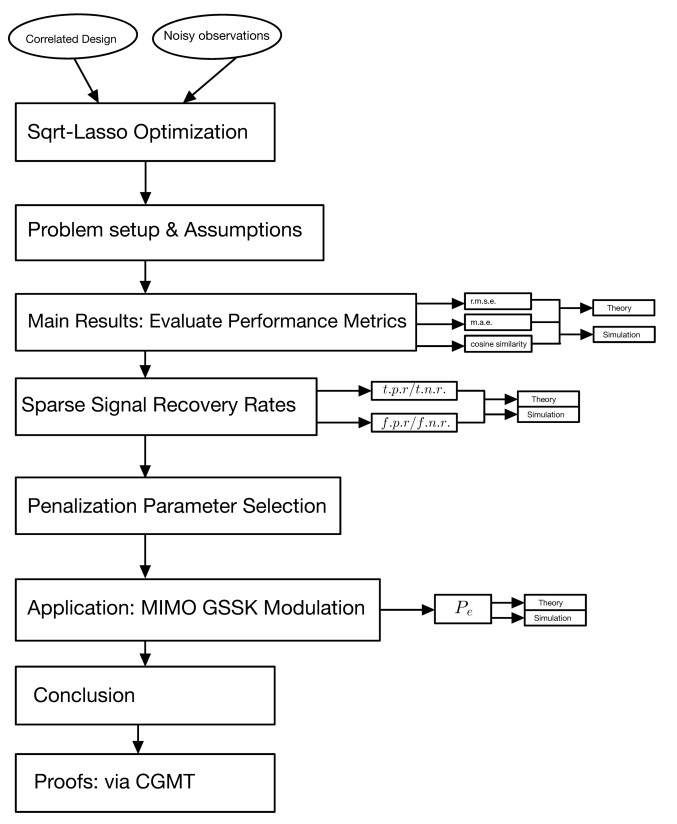
This paper provided a comprehensive analysis of sparse signal estimation from noisy and possibly underdetermined linear observations in the high-dimensional asymptotic regime. The focus was on the square-root lasso (sqrt-lasso), a popular convex optimization method used for sparse signal recovery. We analyzed its performance using several metrics, such as root-mean-squared error (r.m.s.e.), mean absolute error (m.a.e.), cosine similarity, and true/false recovery rates. The analysis assumed a normally distributed design matrix with left-sided correlation and Gaussian noise. In addition to theoretical contributions, we applied these results to a real-world wireless communications problem by examining the error performance of sqrt-lasso in generalized space shift keying (GSSK) modulation for multiple-input multiple-output (MIMO) systems. This application was particularly relevant, as the GSSK modulation generates sparse data symbols, making it an ideal scenario for sparse recovery techniques. Our study offered tight asymptotic approximations for the performance of sqrt-lasso in such systems. Beyond the wireless communications application, the results had broader implications for other high-dimensional applications, including compressed sensing, machine learning, and statistical inference. The analysis presented in this paper, supported by numerical simulations, provided practical insights into how sqrt-lasso behaved under correlated designs, offering useful guidelines for optimizing its use in real-world scenarios. The expressions and insights obtained from this study can be used to optimally choose the penalization parameter of the sqrt-lasso. By applying these results, one can make informed decisions about performance and fine-tuning the sqrt-lasso, considering the presence of correlated regressors in a high-dimensional context.
Citation: Ayed M. Alrashdi, Masad A. Alrasheedi. Square-root lasso under correlated regressors: Tight statistical analysis with a wireless communications application[J]. AIMS Mathematics, 2024, 9(11): 32872-32903. doi: 10.3934/math.20241573
This paper provided a comprehensive analysis of sparse signal estimation from noisy and possibly underdetermined linear observations in the high-dimensional asymptotic regime. The focus was on the square-root lasso (sqrt-lasso), a popular convex optimization method used for sparse signal recovery. We analyzed its performance using several metrics, such as root-mean-squared error (r.m.s.e.), mean absolute error (m.a.e.), cosine similarity, and true/false recovery rates. The analysis assumed a normally distributed design matrix with left-sided correlation and Gaussian noise. In addition to theoretical contributions, we applied these results to a real-world wireless communications problem by examining the error performance of sqrt-lasso in generalized space shift keying (GSSK) modulation for multiple-input multiple-output (MIMO) systems. This application was particularly relevant, as the GSSK modulation generates sparse data symbols, making it an ideal scenario for sparse recovery techniques. Our study offered tight asymptotic approximations for the performance of sqrt-lasso in such systems. Beyond the wireless communications application, the results had broader implications for other high-dimensional applications, including compressed sensing, machine learning, and statistical inference. The analysis presented in this paper, supported by numerical simulations, provided practical insights into how sqrt-lasso behaved under correlated designs, offering useful guidelines for optimizing its use in real-world scenarios. The expressions and insights obtained from this study can be used to optimally choose the penalization parameter of the sqrt-lasso. By applying these results, one can make informed decisions about performance and fine-tuning the sqrt-lasso, considering the presence of correlated regressors in a high-dimensional context.

| [1] |
D. L. Donoho, Compressed sensing, IEEE Trans. Inform. Theory, 52 (2006), 1289–1306. https://doi.org/10.1109/TIT.2006.871582 doi: 10.1109/TIT.2006.871582

|
| [2] |
D. L. Donoho, A. Maleki, A. Montanari, Message-passing algorithms for compressed sensing, Proc. Natl. Acad. Sci. U.S.A., 106 (2009), 18914–18919. https://doi.org/10.1073/pnas.0909892106 doi: 10.1073/pnas.0909892106
|
| [3] | I. B. Atitallah, C. Thrampoulidis, A. Kammoun, T. Y. Al-Naffouri, M. Alouini, B. Hassibi, The BOX-LASSO with application to GSSK modulation in massive MIMO systems, In: 2017 IEEE International symposium on information theory (ISIT), Germany: IEEE, 2017, 1082–1086. https://doi.org/10.1109/ISIT.2017.8006695 |
| [4] |
M. Lustig, D. Donoho, J. M. Pauly, Sparse MRI: The application of compressed sensing for rapid MR imaging, Magn. Reson. Med., 58 (2007), 1182–1195. https://doi.org/10.1002/mrm.21391 doi: 10.1002/mrm.21391
|
| [5] |
M. I. Jordan, T. M. Mitchell, Machine learning: Trends, perspectives, and prospects, Science, 349 (2015), 255–260. https://doi.org/10.1126/science.aaa8415 doi: 10.1126/science.aaa8415
|
| [6] |
R. Tibshirani, Regression shrinkage and selection via the Lasso, J. R. Stat. Soc. Ser. B Stat. Methodol., 58 (1996), 267–288. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x doi: 10.1111/j.2517-6161.1996.tb02080.x
|
| [7] | P. Bühlmann, S. Van De Geer, Statistics for high-dimensional data: Methods, theory and applications, Heidelberg: Springer Berlin, 2011. https://doi.org/10.1007/978-3-642-20192-9 |
| [8] |
A. Belloni, V. Chernozhukov, L. Wang, Square-root lasso: Pivotal recovery of sparse signals via conic programming, Biometrika, 98 (2011), 791–806. https://doi.org/10.1093/biomet/asr043 doi: 10.1093/biomet/asr043
|
| [9] |
Y. Wiaux, L. Jacques, G. Puy, A. M. M. Scaife, P. Vandergheynst, Compressed sensing imaging techniques for radio interferometry, Mon. Not. Roy. Astron. Soc., 395 (2009), 1733–1742. https://doi.org/10.1111/j.1365-2966.2009.14665.x doi: 10.1111/j.1365-2966.2009.14665.x
|
| [10] |
A. M. Alrashdi, A. E. Alrashdi, A. Alghadhban, M. A. H. Eleiwa, Optimum GSSK transmission in massive MIMO systems using the Box-lASSO decoder, IEEE Access, 10 (2022), 15845–15859. https://doi.org/10.1109/ACCESS.2022.3148329 doi: 10.1109/ACCESS.2022.3148329
|
| [11] |
P. Waldmann, G. Mészáros, B. Gredler, C. Fuerst, J. Sölkner, Evaluation of the lasso and the elastic net in genome-wide association studies, Front. Genet., 4 (2013), 270. https://doi.org/10.3389/fgene.2013.00270 doi: 10.3389/fgene.2013.00270
|
| [12] |
Y. Chu, S. M. Ali, M. Lu, Y. Zhang, Incorporating heterogeneous features into the random subspace method for bearing fault diagnosis, Entropy, 25 (2023), 1194. https://doi.org/10.3390/e25081194 doi: 10.3390/e25081194
|
| [13] |
I. T. Jolliffe, N. T. Trendafilov, M. Uddin, A modified principal component technique based on the LASSO, J. Comput. Graph. Statist., 12 (2003), 531–547. https://doi.org/10.1198/1061860032148 doi: 10.1198/1061860032148
|
| [14] |
N. Tang, S. Mao, Y. Wang, R. M. Nelms, Solar power generation forecasting with a LASSO-based approach, IEEE Internet Things J., 5 (2018), 1090–1099. https://doi.org/10.1109/JIOT.2018.2812155 doi: 10.1109/JIOT.2018.2812155
|
| [15] | M. Pawlak, J. Lv, Analysis of large scale power systems via lasso learning algorithms, In: Artificial intelligence and soft computing. ICAISC 2019, Cham: Springer, 11508 (2019), 652–662. https://doi.org/10.1007/978-3-030-20912-4_59 |
| [16] |
Y. Li, Y. Li, Y. Sun, Online static security assessment of power systems based on LASSO algorithm, Appl. Sci., 8 (2018), 1442. https://doi.org/10.3390/app8091442 doi: 10.3390/app8091442
|
| [17] |
H. Ohlsson, L. Ljung, Identification of switched linear regression models using sum-of-norms regularization, Automatica, 49 (2013), 1045–1050. https://doi.org/10.1016/j.automatica.2013.01.031 doi: 10.1016/j.automatica.2013.01.031
|
| [18] |
A. Chiuso, G. Pillonetto, A bayesian approach to sparse dynamic network identification, Automatica, 48 (2012), 1553–1565. https://doi.org/10.1016/j.automatica.2012.05.054 doi: 10.1016/j.automatica.2012.05.054
|
| [19] |
S. L. Kukreja, J. Löfberg, M. J. Brenner, A least absolute shrinkage and selection operator (LASSO) for nonlinear system identification, IFAC Proc. Vol., 39 (2006), 814–819. https://doi.org/10.3182/20060329-3-AU-2901.00128 doi: 10.3182/20060329-3-AU-2901.00128
|
| [20] | M. Mézard, G. Parisi, M. A. Virasoro, Spin glass theory and beyond: An introduction to the replica method and its applications, 9 (1986), 476. https://doi.org/10.1142/0271 |
| [21] | C. Thrampoulidis, S. Oymak, B. Hassibi, The Gaussian min-max theorem in the presence of convexity, arXiv: 1408.4837, 2014. https://doi.org/10.48550/arXiv.1408.4837 |
| [22] |
E. Candes, T. Tao, The dantzig selector: Statistical estimation when p is much larger than n, Ann. Statist., 35 (2007), 2313–2351. https://doi.org/10.1214/009053606000001523 doi: 10.1214/009053606000001523
|
| [23] |
M. J. Wainwright, Sharp thresholds for high-dimensional and noisy sparsity recovery using $\ell_1 $-constrained quadratic programming (Lasso), IEEE Trans. Inform. Theory, 55 (2009), 2183–2202. https://doi.org/10.1109/TIT.2009.2016018 doi: 10.1109/TIT.2009.2016018
|
| [24] |
P. J. Bickel, Y. Ritov, A. B. Tsybakov, Simultaneous analysis of Lasso and dantzig selector, Ann. Statist., 37 (2009), 1705–1732. https://doi.org/10.1214/08-AOS620 doi: 10.1214/08-AOS620
|
| [25] | G. M. James, C. L. Paulson, P. Rusmevichientong, The constrained Lasso, 2012. |
| [26] |
M. Bayati, A. Montanari, The Lasso risk for Gaussian matrices, IEEE Trans. Inform. Theory, 58 (2011), 1997–2017. https://doi.org/10.1109/TIT.2011.2174612 doi: 10.1109/TIT.2011.2174612
|
| [27] | M. Bayati, J. Pereira, A. Montanari, The Lasso risk: Asymptotic results and real world examples, Adv. Neural Inf. Process. Syst., 23 (2010). |
| [28] |
M. Vehkaperä, Y. Kabashima, S. Chatterjee, Analysis of regularized LS reconstruction and random matrix ensembles in compressed sensing, IEEE Trans. Inform. Theory, 62 (2016), 2100–2124. https://doi.org/10.1109/TIT.2016.2525824 doi: 10.1109/TIT.2016.2525824
|
| [29] | S. Rangan, V. Goyal, A. K. Fletcher, Asymptotic analysis of MAP estimation via the replica method and compressed sensing, Adv. Neural Inf. Process. Syst., 22 (2009). |
| [30] | Y. Kabashima, T. Wadayama, T. Tanaka, Statistical mechanical analysis of a typical reconstruction limit of compressed sensing, In: 2010 IEEE international symposium on information theory, Austin: IEEE, 2010, 1533–1537. https://doi.org/10.1109/ISIT.2010.5513526 |
| [31] | M. Stojnic, Recovery thresholds for $l$1 optimization in binary compressed sensing, In: 2010 IEEE international symposium on information theory, Austin: IEEE, 2010, 1593–1597. https://doi.org/10.1109/ISIT.2010.5513435 |
| [32] | M. Stojnic, A framework to characterize performance of LASSO algorithms, arXiv: 1303.7291, 2013. https://doi.org/10.48550/arXiv.1303.7291 |
| [33] | S. Oymak, C. Thrampoulidis, B. Hassibi, The squared-error of generalized LASSO: A precise analysis, In: 2013 51st Annual allerton conference on communication, control, and computing (Allerton), Monticello: IEEE, 2013, 1002–1009. https://doi.org/10.1109/Allerton.2013.6736635 |
| [34] | C. Thrampoulidis, S. Oymak, B. Hassibi, Simple error bounds for regularized noisy linear inverse problems, In: 2014 IEEE international symposium on information theory, Honolulu: IEEE, 2014, 3007–3011. https://doi.org/10.1109/ISIT.2014.6875386 |
| [35] | C. Thrampoulidis, S. Oymak, B. Hassibi, Regularized linear regression: A precise analysis of the estimation error, In: 28th Conference on learning theory, 40 (2015), 1683–1709. |
| [36] | C. Thrampoulidis, A. Panahi, B. Hassibi, Asymptotically exact error analysis for the generalized equation-LASSO, In: 2015 IEEE international symposium on information theory (ISIT), Hong Kong: IEEE, 2015, 2021–2025. https://doi.org/10.1109/ISIT.2015.7282810 |
| [37] | C. Thrampoulidis, A. Panahi, D. Guo, B. Hassibi, Precise error analysis of the LASSO, In: 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), South Brisbane: IEEE, 2015, 3467–3471. https://doi.org/10.1109/ICASSP.2015.7178615 |
| [38] |
C. Thrampoulidis, E. Abbasi, B. Hassibi, Precise error analysis of regularized $ M$-estimators in high dimensions, IEEE Trans. Inform. Theory, 64 (2018), 5592–5628. https://doi.org/10.1109/TIT.2018.2840720 doi: 10.1109/TIT.2018.2840720
|
| [39] | E. Abbasi, C. Thrampoulidis, B. Hassibi, General performance metrics for the LASSO, In: 2016 IEEE information theory workshop (ITW), Cambridge: IEEE Trans, 2016,181–185. https://doi.org/10.1109/ITW.2016.7606820 |
| [40] | C. Thrampoulidis, E. Abbasi, B. Hassibi, Lasso with non-linear measurements is equivalent to one with linear measurements, Adv. Neural Inf. Process. Syst., 2015, 3420–3428. |
| [41] | A. M. Alrashdi, I. B. Atitallah, T. Y. Al-Naffouri, M. S. Alouini, Precise performance analysis of the LASSO under matrix uncertainties, In: 2017 IEEE global conference on signal and information processing (GlobalSIP), Montreal: IEEE, 2017, 1290–1294. https://doi.org/10.1109/GlobalSIP.2017.8309169 |
| [42] |
A. M. Alrashdi, M. Alazmi, M. A. Alrasheedi, Generalized penalized constrained regression: Sharp guarantees in high dimensions with noisy features, Mathematics, 11 (2023), 3706. https://doi.org/10.3390/math11173706 doi: 10.3390/math11173706
|
| [43] |
A. M. Alrashdi, I. B. Atitallah, T. Y. Al-Naffouri, Precise performance analysis of the box-elastic net under matrix uncertainties, IEEE Signal Process. Lett., 26 (2019), 655–659. https://doi.org/10.1109/LSP.2019.2897215 doi: 10.1109/LSP.2019.2897215
|
| [44] |
M. Hebiri, J. Lederer, How correlations influence Lasso prediction, IEEE Trans. Inform. Theory, 59 (2012), 1846–1854. https://doi.org/10.1109/TIT.2012.2227680 doi: 10.1109/TIT.2012.2227680
|
| [45] |
M. Celentano, A. Montanari, Y. Wei, The Lasso with general Gaussian designs with applications to hypothesis testing, Anna. Statist., 51 (2023), 2194–2220. https://doi.org/10.1214/23-AOS2327 doi: 10.1214/23-AOS2327
|
| [46] | A. M. Alrashdi, H. Sifaou, A. Kammoun, M.-S. Alouini, T. Y. Al-Naffouri, Precise error analysis of the Lasso under correlated designs, arXiv: 2008.13033, 2020. https://doi.org/10.48550/arXiv.2008.13033 |
| [47] | A. M. Alrashdi, H. Sifaou, A. Kammoun, M. S. Alouini, T. Y. Al-Naffouri, Box-relaxation for bpsk recovery in massive MIMO: A precise analysis under correlated channels, In: ICC 2020-2020 IEEE international conference on communications (ICC), Dublin: IEEE, 2020, 1–6. https://doi.org/10.1109/ICC40277.2020.9149198 |
| [48] | A. M. Alrashdi, Large system analysis of box-relaxation in correlated massive MIMO systems under imperfect CSI, In: 2021 IEEE globecom workshops (GC Wkshps), Spain: IEEE, 2021, 1–6. https://doi.org/10.1109/GCWkshps52748.2021.9682159 |
| [49] |
A. M. Alrashdi, Asymptotic characterisation of regularised zero-forcing receiver for imperfect and correlated massive multiple-input multiple-output systems, IET Signal Process., 16 (2022), 413–425. https://doi.org/10.1049/sil2.12105 doi: 10.1049/sil2.12105
|
| [50] | J. Jeganathan, A. Ghrayeb, L. Szczecinski, Generalized space shift keying modulation for MIMO channels, In: 2008 IEEE 19th international symposium on personal, indoor and mobile radio communications, France: IEEE, 2008, 1–5. https://doi.org/10.1109/PIMRC.2008.4699782 |
| [51] |
A. Adhikary, J. Nam, J.Y. Ahn, G. Caire, Joint spatial division and multiplexing—the large-scale array regime, IEEE Trans. Inform. Theory, 59 (2013), 6441–6463. https://doi.org/10.1109/TIT.2013.2269476 doi: 10.1109/TIT.2013.2269476
|
| [52] |
P. Xia, L. Zhang, F. Li, Learning similarity with cosine similarity ensemble, Inform. Sci., 307 (2015), 39–52. https://doi.org/10.1016/j.ins.2015.02.024 doi: 10.1016/j.ins.2015.02.024
|
| [53] | C. Thrampoulidis, Recovering structured signals in high dimensions via non-smooth convex optimization: Precise performance analysis, California Institute of Technology, 2016. https://doi.org/doi:10.7907/Z998850V |
| [54] |
H. Shin, M. Z. Win, J. H. Lee, M. Chiani, On the capacity of doubly correlated MIMO channels, IEEE Trans. Wirel. Commun., 5 (2006), 2253–2265. https://doi.org/10.1109/TWC.2006.1687741 doi: 10.1109/TWC.2006.1687741
|
| [55] | S. Diamond, S. Boyd, CVXPY: A Python-embedded modeling language for convex optimization, J. Mach. Learn. Res., 17 (2016), 1–5. |
| [56] |
C. Giacobino, S. Sardy, J. Diaz-Rodriguez, N. Hengartner, Quantile universal threshold, Electron. J. Statist., 11 (2017), 4701–4722. https://doi.org/10.1214/17-EJS1366 doi: 10.1214/17-EJS1366
|
| [57] |
S. Sardy, X. Ma, Sparse additive models in high dimensions with wavelets, Scand. J. Statist., 51 (2024), 89–108. https://doi.org/10.1111/sjos.12680 doi: 10.1111/sjos.12680
|
| [58] | D. G. Luenberger, Y. Ye, Linear and nonlinear programming, Cham: Springer, 2021. https://doi.org/10.1007/978-3-030-85450-8 |
| [59] |
L. Lu, G. Y. Li, A L. Swindlehurst, A. Ashikhmin, R. Zhang, An overview of massive MIMO: Benefits and challenges, IEEE J Selected Topics Signal Process., 8 (2014), 742–758. https://doi.org/10.1109/JSTSP.2014.2317671 doi: 10.1109/JSTSP.2014.2317671
|
| [60] |
J. Jeganathan, A. Ghrayeb, L. Szczecinski, A. Ceron, Space shift keying modulation for MIMO channels, IEEE Trans. Wirel. Commun., 8 (2009), 3692–3703. https://doi.org/10.1109/TWC.2009.080910 doi: 10.1109/TWC.2009.080910
|
| [61] |
C. M. Yu, S. H. Hsieh, H.W. Liang, C. S. Lu, W. H. Chung, S. Y. Kuo, et al., Compressed sensing detector design for space shift keying in MIMO systems, IEEE Commun. Lett., 16 (2012), 1556–1559. https://doi.org/10.1109/LCOMM.2012.091212.121319 doi: 10.1109/LCOMM.2012.091212.121319
|
| [62] | E. Abbasi, F. Salehi, B. Hassibi, Universality in learning from linear measurements, Adv. Neural Inf. Process. Syst., 32 (2019). |
| [63] |
H. Hu and Y. M. Lu, Universality laws for high-dimensional learning with random features, IEEE Trans. Inform. Theory, 69 (2022), 1932–1964. https://doi.org/10.1109/TIT.2022.3217698 doi: 10.1109/TIT.2022.3217698
|
| [64] |
F. Gerace, F. Krzakala, B. Loureiro, L. Stephan, L. Zdeborová, Gaussian universality of perceptrons with random labels, Phys. Rev. E, 109 (2024), 034305. https://doi.org/10.1103/PhysRevE.109.034305 doi: 10.1103/PhysRevE.109.034305
|
| [65] |
W. Gander, G. H. Golub, U. von Matt, A constrained eigenvalue problem, Linear Algebra Appl., 114-115 (1989), 815–839. https://doi.org/10.1016/0024-3795(89)90494-1 doi: 10.1016/0024-3795(89)90494-1
|
| [66] |
P. D. Tao, L. T. H. An, A D.C. optimization algorithm for solving the trust-region subproblem, SIAM J. Optim., 8 (1998), 476–505. https://doi.org/10.1137/S1052623494274313 doi: 10.1137/S1052623494274313
|
| [67] |
S. Adachi, S. Iwata, Y. Nakatsukasa, A. Takeda, Solving the trust-region subproblem by a generalized eigenvalue problem, SIAM J. Optim., 27 (2017), 269–291. https://doi.org/10.1137/16M1058200 doi: 10.1137/16M1058200
|
| [68] | O. Dhifallah, Y. M. Lu, A precise performance analysis of learning with random features, arXiv: 2008.11904, 2020. https://doi.org/10.48550/arXiv.2008.11904 |
| [69] | R. Couillet, M. Debbah, Random matrix methods for wireless communications, Cambridge: Cambridge University Press, 2011. https://doi.org/10.1017/CBO9780511994746 |







Figures(8) / Tables(2)

Ayed M. Alrashdi, Masad A. Alrasheedi. Square-root lasso under correlated regressors: Tight statistical analysis with a wireless communications application[J]. AIMS Mathematics, 2024, 9(11): 32872-32903. doi: 10.3934/math.20241573







 DownLoad:
DownLoad: