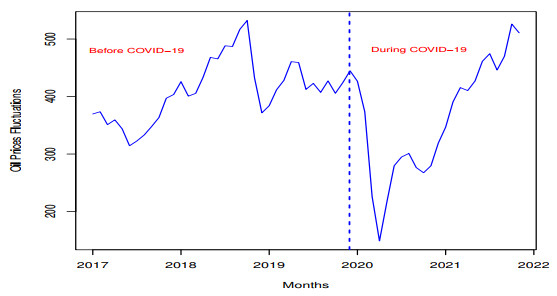
The COVID-19 epidemic has had a profound effect on almost every aspect of daily life, including the financial sector, education, transportation, health care, and so on. Among these sectors, the financial and health sectors are the most affected areas by COVID-19. Modeling and predicting the impact of the COVID-19 epidemic on the financial and health care sectors is particularly important these days. Therefore, this paper has two aims, (i) to introduce a new probability distribution for modeling the financial data set (oil prices data), and (ii) to implement a machine learning approach to predict the oil prices. First, we introduce a new approach for developing new probability distributions for the univariate analysis of the oil price data. The proposed approach is called a new reduced exponential-$ X $ (NRE-$ X $) family. Based on this approach, two new statistical distributions are introduced for modeling the oil price data and its log returns. Based on certain statistical tools, we observe that the proposed probability distributions are the best competitors for modeling the prices' data sets. Second, we carry out a multivariate analysis while considering some covariates of oil price data. Dual well-known machine learning algorithms, namely, the least absolute shrinkage and absolute deviation (Lasso) and Elastic net (Enet) are utilized to achieve the important features for oil prices based on the best model. The best model is established through forecasting performance.
Citation: Huda M. Alshanbari, Zubair Ahmad, Faridoon Khan, Saima K. Khosa, Muhammad Ilyas, Abd Al-Aziz Hosni El-Bagoury. Univariate and multivariate analyses of the asset returns using new statistical models and penalized regression techniques[J]. AIMS Mathematics, 2023, 8(8): 19477-19503. doi: 10.3934/math.2023994
The COVID-19 epidemic has had a profound effect on almost every aspect of daily life, including the financial sector, education, transportation, health care, and so on. Among these sectors, the financial and health sectors are the most affected areas by COVID-19. Modeling and predicting the impact of the COVID-19 epidemic on the financial and health care sectors is particularly important these days. Therefore, this paper has two aims, (i) to introduce a new probability distribution for modeling the financial data set (oil prices data), and (ii) to implement a machine learning approach to predict the oil prices. First, we introduce a new approach for developing new probability distributions for the univariate analysis of the oil price data. The proposed approach is called a new reduced exponential-$ X $ (NRE-$ X $) family. Based on this approach, two new statistical distributions are introduced for modeling the oil price data and its log returns. Based on certain statistical tools, we observe that the proposed probability distributions are the best competitors for modeling the prices' data sets. Second, we carry out a multivariate analysis while considering some covariates of oil price data. Dual well-known machine learning algorithms, namely, the least absolute shrinkage and absolute deviation (Lasso) and Elastic net (Enet) are utilized to achieve the important features for oil prices based on the best model. The best model is established through forecasting performance.

| [1] |
B. B. Ahundjanov, S. B. Akhundjanov, B. B. Okhunjanov, Risk perception and oil and gasoline markets under COVID-19, J. Econ. Bus., 115 (2021), 105979. https://doi.org/10.1016/j.jeconbus.2020.105979 doi: 10.1016/j.jeconbus.2020.105979

|
| [2] |
C. T. Vidya, K. P. Prabheesh, Implications of COVID-19 pandemic on the global trade networks, Emerg. Mark. Financ. Tr., 56 (2020), 2408–2421. https://doi.org/10.1080/1540496X.2020.1785426 doi: 10.1080/1540496X.2020.1785426
|
| [3] |
M. Ali, N. Alam, S. A. R. Rizvi, Coronavirus (COVID-19). An epidemic or pandemic for financial markets, J. Behav. Expe. Financ., 27 (2020), 100341. https://doi.org/10.1016/j.jbef.2020.100341 doi: 10.1016/j.jbef.2020.100341
|
| [4] |
W. Zhao, S. K. Khosa, Z. Ahmad, M. Aslam, A. Z. Afify, Type-Ⅰ heavy tailed family with applications in medicine, engineering and insurance, Plos One, 15 (2020), e0237462. https://doi.org/10.1371/journal.pone.0237462 doi: 10.1371/journal.pone.0237462
|
| [5] |
R. Gerlagh, R. J. Heijmans, K. E. Rosendahl, COVID-19 tests the market stability reserve, Environ. Resour. Econ., 76 (2020), 855–865. https://doi.org/10.1007/s10640-020-00441-0 doi: 10.1007/s10640-020-00441-0
|
| [6] |
C. Gharib, S. Mefteh-Wali, S. B. Jabeur, The bubble contagion effect of COVID-19 outbreak: Evidence from crude oil and gold markets, Financ. Res. Lett., 38 (2021), 101703. https://doi.org/10.1016/j.frl.2020.101703 doi: 10.1016/j.frl.2020.101703
|
| [7] |
Z. Ahmad, E. Mahmoudi, S. Dey, S. K. Khosa, Modeling vehicle insurance loss data using a new member of TX family of distributions, J. Stat. Theory Appl., 19 (2020), 133–147. https://doi.org/10.2991/jsta.d.200421.001 doi: 10.2991/jsta.d.200421.001
|
| [8] |
D. Zhang, M. Hu, Q. Ji, Financial markets under the global pandemic of COVID-19, Financ. Res. Lett., 36 (2020), 101528. https://doi.org/10.1016/j.frl.2020.101528 doi: 10.1016/j.frl.2020.101528
|
| [9] |
E. Arrigo, C. Liberati, P. Mariani, Social media data and users' preferences: A statistical analysis to support marketing communication, Big Data Res., 24 (2021), 100189. https://doi.org/10.1016/j.bdr.2021.100189 doi: 10.1016/j.bdr.2021.100189
|
| [10] |
M. Z. Rashid, A. S. Akhter, Survival weighted power function distribution with applications to medical, oceanology and metrology data, Adv. Appl. Stat., 67 (2021), 117–253. https://doi.org/10.17654/AS067020133 doi: 10.17654/AS067020133
|
| [11] |
W. Wang, Z. Ahmad, O. Kharazmi, C. B. Ampadu, E. H. Hafez, M. M. M. El-Din, New generalized-X family: Modeling the reliability engineering applications, Plos One, 16 (2021), e0248312. https://doi.org/10.1371/journal.pone.0248312 doi: 10.1371/journal.pone.0248312
|
| [12] |
C. S. Kumar, S. R. Nair, A generalized Log-Weibull distribution with bio-medical applications, Int. J. Stat. Med. Res., 10 (2021), 10–21. https://doi.org/10.6000/1929-6029.2021.10.02 doi: 10.6000/1929-6029.2021.10.02
|
| [13] |
H. S. Bakouch, C. Chesneau, O. A. Elsamadony, The Gumbel kernel for estimating the probability density function with application to hydrology data, J. Data Inform. Manag., 3 (2021), 261–269. https://doi.org/10.1007/s42488-021-00058-y doi: 10.1007/s42488-021-00058-y
|
| [14] |
D. Bhati, S. Ravi, On generalized log-Moyal distribution: A new heavy tailed size distribution, Insur. Math. Econ., 79 (2018), 247–259. https://doi.org/10.1016/j.insmatheco.2018.02.002 doi: 10.1016/j.insmatheco.2018.02.002
|
| [15] |
Z. Ahmad, E. Mahmoudi, G. G. Hamedani, O. Kharazmi, New methods to define heavy-tailed distributions with applications to insurance data, J. Taibah Univ. Sci., 14 (2020), 359–382. https://doi.org/10.1080/16583655.2020.1741942 doi: 10.1080/16583655.2020.1741942
|
| [16] |
Z. Li, J. Beirlant, S. Meng, Generalizing the log-Moyal distribution and regression models for heavy-tailed loss data, ASTIN Bull. J. IAA, 51 (2021), 57–99. https://doi.org/10.1017/asb.2020.35 doi: 10.1017/asb.2020.35
|
| [17] |
Ł. Bielak, A. Grzesiek, J. Janczura, A. Wyłomańska, Market risk factors analysis for an international mining company. Multi-dimensional, heavy-tailed-based modelling, Resour. Policy, 74 (2021), 102308. https://doi.org/10.1016/j.resourpol.2021.102308 doi: 10.1016/j.resourpol.2021.102308
|
| [18] |
D. B. Madan, Multivariate distributions for financial returns, Int. J. Theor. Appl. Fin., 23 (2020), 20500417. https://doi.org/10.1142/S0219024920500417 doi: 10.1142/S0219024920500417
|
| [19] |
C. O. Cepoi, Asymmetric dependence between stock market returns and news during COVID-19 financial turmoil, Financ. Res. Lett., 36 (2020), 101658. https://doi.org/10.1016/j.frl.2020.101658 doi: 10.1016/j.frl.2020.101658
|
| [20] |
W. Wang, W. Li, N. Zhang, K. Liu, Portfolio formation with preselection using deep learning from long-term financial data, Expert Syst. Appl., 143 (2020), 113042. https://doi.org/10.1016/j.eswa.2019.113042 doi: 10.1016/j.eswa.2019.113042
|
| [21] |
S. M. Carta, S. Consoli, A. S. Podda, D. R. Recupero, M. M. Stanciu, Ensembling and dynamic asset selection for risk-controlled statistical arbitrage, IEEE Access, 9 (2021), 29942–29959. https://doi.org/10.1109/ACCESS.2021.3059187 doi: 10.1109/ACCESS.2021.3059187
|
| [22] |
L. W. Cong, K. Tang, J. Wang, Y. Zhang, Deep sequence modeling: Development and applications in asset pricing, J. Financ. Data Sci., 3 (2021), 28–42. https://doi.org/10.3905/jfds.2020.1.053 doi: 10.3905/jfds.2020.1.053
|
| [23] |
F. Schuhmacher, H. Kohrs, B. R. Auer, Justifying mean-variance portfolio selection when asset returns are skewed, Manag. Sci., 67 (2021), 7812–7824. https://doi.org/10.1287/mnsc.2020.3846 doi: 10.1287/mnsc.2020.3846
|
| [24] |
S. Karim, M. U. Akhtar, R. Tashfeen, M. R. Rabbani, A. A. A. Rahman, A. AlAbbas, Sustainable banking regulations pre and during coronavirus outbreak: The moderating role of financial stability, Econ. Res.-Ekon. Istraž., 35 (2022), 3360–3377. https://doi.org/10.1080/1331677X.2021.1993951 doi: 10.1080/1331677X.2021.1993951
|
| [25] |
Z. Ahmad, G. G. Hamedani, N. S. Butt, Recent developments in distribution theory: A brief survey and some new generalized classes of distributions, Pak. J. Stat. Oper. Res., 15 (2019), 87–110. https://doi.org/10.18187/pjsor.v15i1.2803 doi: 10.18187/pjsor.v15i1.2803
|
| [26] |
A. Alzaatreh, C. Lee, F. Famoye, A new method for generating families of continuous distributions, Metron, 71 (2013), 63–79. https://doi.org/10.1007/s40300-013-0007-y doi: 10.1007/s40300-013-0007-y
|
| [27] |
J. L. Castle, J. A. Doornik, D. F. Hendry, Modelling non-stationary 'big data', Int. J. Forecasting, 37 (2021), 1556–1575. https://doi.org/10.1016/j.ijforecast.2020.08.002 doi: 10.1016/j.ijforecast.2020.08.002
|
| [28] |
F. Khan, A. Urooj, K. Ullah, B. Alnssyan, Z. Almaspoor, A comparison of Autometrics and penalization techniques under various error distributions: Evidence from Monte Carlo simulation, Complexity, 2021. https://doi.org/10.1155/2021/9223763 doi: 10.1155/2021/9223763
|
| [29] |
R. Tibshirani, Regression shrinkage and selection via the lasso, J. R. Stat. Soc. B, 58 (1996), 267–288. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x doi: 10.1111/j.2517-6161.1996.tb02080.x
|
| [30] |
F. Khan, A. Urooj, S. A. Khan, S. K. Khosa, S. Muhammadullah, Z. Almaspoor, Evaluating the performance of feature selection methods using huge big data: A Monte Carlo simulation approach, Math. Prob. Eng., 2022. https://doi.org/10.1155/2022/6607330 doi: 10.1155/2022/6607330
|
| [31] |
S. Smeekes, E. Wijler, Macroeconomic forecasting using penalized regression methods, Int. J. Forecasting, 34 (2018), 408–430. https://doi.org/10.1016/j.ijforecast.2018.01.001 doi: 10.1016/j.ijforecast.2018.01.001
|
| [32] |
J. H. Stock, M. W. Watson, Macroeconomic forecasting using diffusion indexes, J. Bus. Econ. Stat., 20 (2002), 147–162. https://doi.org/10.1198/073500102317351921 doi: 10.1198/073500102317351921
|


















Figures(19) / Tables(9)

Huda M. Alshanbari, Zubair Ahmad, Faridoon Khan, Saima K. Khosa, Muhammad Ilyas, Abd Al-Aziz Hosni El-Bagoury. Univariate and multivariate analyses of the asset returns using new statistical models and penalized regression techniques[J]. AIMS Mathematics, 2023, 8(8): 19477-19503. doi: 10.3934/math.2023994







 DownLoad:
DownLoad: